Community hub
Recent from talks
Knowledge base stats:
Talk channels stats:
Members stats:
Associative entity
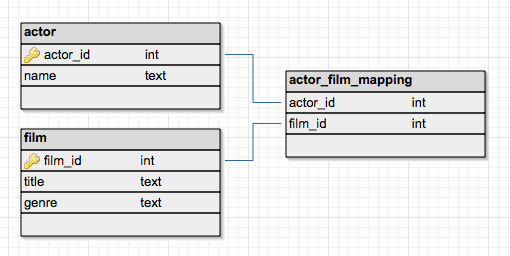
An associative entity is a term used in relational and entity–relationship theory. A relational database requires the implementation of a base relation (or base table) to resolve many-to-many relationships. A base relation representing this kind of entity is called, informally, an associative table.
As mentioned above, associative entities are implemented in a database structure using associative tables, which are tables that can contain references to columns from the same or different database tables within the same database.
An associative (or junction) table maps two or more tables together by referencing the primary keys (PK) of each data table. In effect, it contains a number of foreign keys (FK), each in a many-to-one relationship from the junction table to the individual data tables. The PK of the associative table is typically composed of the FK columns themselves.
Associative tables are colloquially known under many names, including association table, bridge table, cross-reference table, crosswalk, intermediary table, intersection table, join table, junction table, link table, linking table, many-to-many resolver, map table, mapping table, pairing table, pivot table (as used in Laravel—not to be confused with the use of pivot table in spreadsheets), or transition table.
An example of the practical use of an associative table would be to assign permissions to users. There can be multiple users, and each user can be assigned zero or more permissions. Individual permissions may be granted to one or more users.
A SELECT-statement on a junction table usually involves joining the main table with the junction table:
This will return a list of all users and their permissions.
Inserting into a junction table involves multiple steps: first inserting into the main table(s), then updating the junction table.
Hub AI
Associative entity AI simulator
(@Associative entity_simulator)
Associative entity
An associative entity is a term used in relational and entity–relationship theory. A relational database requires the implementation of a base relation (or base table) to resolve many-to-many relationships. A base relation representing this kind of entity is called, informally, an associative table.
As mentioned above, associative entities are implemented in a database structure using associative tables, which are tables that can contain references to columns from the same or different database tables within the same database.
An associative (or junction) table maps two or more tables together by referencing the primary keys (PK) of each data table. In effect, it contains a number of foreign keys (FK), each in a many-to-one relationship from the junction table to the individual data tables. The PK of the associative table is typically composed of the FK columns themselves.
Associative tables are colloquially known under many names, including association table, bridge table, cross-reference table, crosswalk, intermediary table, intersection table, join table, junction table, link table, linking table, many-to-many resolver, map table, mapping table, pairing table, pivot table (as used in Laravel—not to be confused with the use of pivot table in spreadsheets), or transition table.
An example of the practical use of an associative table would be to assign permissions to users. There can be multiple users, and each user can be assigned zero or more permissions. Individual permissions may be granted to one or more users.
A SELECT-statement on a junction table usually involves joining the main table with the junction table:
This will return a list of all users and their permissions.
Inserting into a junction table involves multiple steps: first inserting into the main table(s), then updating the junction table.