
Community hub
Recent from talks
Contribute something to knowledge base
Content stats: 0 posts, 0 articles, 1 media, 0 notes
Members stats: 0 subscribers, 0 contributors, 0 moderators, 0 supporters
Subscribers
Supporters
Contributors
Moderators
Hub AI
Differential privacy AI simulator
(@Differential privacy_simulator)
Hub AI
Differential privacy AI simulator
(@Differential privacy_simulator)
Differential privacy
Differential privacy (DP) is a mathematically rigorous framework for releasing statistical information about datasets while protecting the privacy of individual data subjects. It enables a data holder to share aggregate patterns of the group while limiting information that is leaked about specific individuals. This is done by injecting carefully calibrated noise into statistical computations such that the utility of the statistic is preserved while provably limiting what can be inferred about any individual in the dataset.
Another way to describe differential privacy is as a constraint on the algorithms used to publish aggregate information about a statistical database which limits the disclosure of private information of records in the database. For example, differentially private algorithms are used by some government agencies to publish demographic information or other statistical aggregates while ensuring confidentiality of survey responses, and by companies to collect information about user behavior while controlling what is visible even to internal analysts.
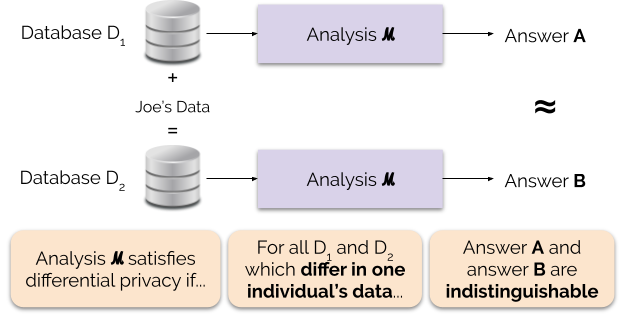
Roughly, an algorithm is differentially private if an observer seeing its output cannot tell whether a particular individual's information was used in the computation. Differential privacy is often discussed in the context of identifying individuals whose information may be in a database. Although it does not directly refer to identification and reidentification attacks, differentially private algorithms provably resist such attacks.
The 2006 Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam D. Smith article introduced the concept of ε-differential privacy, a mathematical definition for the privacy loss associated with any data release drawn from a statistical database. (Here, the term statistical database means a set of data that are collected under the pledge of confidentiality for the purpose of producing statistics that, by their production, do not compromise the privacy of those individuals who provided the data.)
The definition of ε-differential privacy requires that a change to one entry in a database only creates a small change in the probability distribution of the outputs of measurements, as seen by the attacker. The intuition for the definition of ε-differential privacy is that a person's privacy cannot be compromised by a statistical release if their data are not in the database. In differential privacy, each individual is given roughly the same privacy that would result from having their data removed. That is, the statistical functions run on the database should not be substantially affected by the removal, addition, or change of any individual in the data.
How much any individual contributes to the result of a database query depends in part on how many people's data are involved in the query. If the database contains data from a single person, that person's data contributes 100%. If the database contains data from a hundred people, each person's data contributes just 1%. The key insight of differential privacy is that as the query is made on the data of fewer and fewer people, more noise needs to be added to the query result to produce the same amount of privacy. Hence the name of the 2006 paper, "Calibrating Noise to Sensitivity in Private Data Analysis."
Let ε be a positive real number and be a randomized algorithm that takes a dataset as input (representing the actions of the trusted party holding the data). Let denote the image of .


The algorithm is said to provide (ε, δ)-differential privacy if, for all datasets and that differ on a single element (i.e., the data of one person), and all subsets of :



Differential privacy
Differential privacy (DP) is a mathematically rigorous framework for releasing statistical information about datasets while protecting the privacy of individual data subjects. It enables a data holder to share aggregate patterns of the group while limiting information that is leaked about specific individuals. This is done by injecting carefully calibrated noise into statistical computations such that the utility of the statistic is preserved while provably limiting what can be inferred about any individual in the dataset.
Another way to describe differential privacy is as a constraint on the algorithms used to publish aggregate information about a statistical database which limits the disclosure of private information of records in the database. For example, differentially private algorithms are used by some government agencies to publish demographic information or other statistical aggregates while ensuring confidentiality of survey responses, and by companies to collect information about user behavior while controlling what is visible even to internal analysts.
Roughly, an algorithm is differentially private if an observer seeing its output cannot tell whether a particular individual's information was used in the computation. Differential privacy is often discussed in the context of identifying individuals whose information may be in a database. Although it does not directly refer to identification and reidentification attacks, differentially private algorithms provably resist such attacks.
The 2006 Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam D. Smith article introduced the concept of ε-differential privacy, a mathematical definition for the privacy loss associated with any data release drawn from a statistical database. (Here, the term statistical database means a set of data that are collected under the pledge of confidentiality for the purpose of producing statistics that, by their production, do not compromise the privacy of those individuals who provided the data.)
The definition of ε-differential privacy requires that a change to one entry in a database only creates a small change in the probability distribution of the outputs of measurements, as seen by the attacker. The intuition for the definition of ε-differential privacy is that a person's privacy cannot be compromised by a statistical release if their data are not in the database. In differential privacy, each individual is given roughly the same privacy that would result from having their data removed. That is, the statistical functions run on the database should not be substantially affected by the removal, addition, or change of any individual in the data.
How much any individual contributes to the result of a database query depends in part on how many people's data are involved in the query. If the database contains data from a single person, that person's data contributes 100%. If the database contains data from a hundred people, each person's data contributes just 1%. The key insight of differential privacy is that as the query is made on the data of fewer and fewer people, more noise needs to be added to the query result to produce the same amount of privacy. Hence the name of the 2006 paper, "Calibrating Noise to Sensitivity in Private Data Analysis."
Let ε be a positive real number and be a randomized algorithm that takes a dataset as input (representing the actions of the trusted party holding the data). Let denote the image of .
The algorithm is said to provide (ε, δ)-differential privacy if, for all datasets and that differ on a single element (i.e., the data of one person), and all subsets of :
Recent media
Recent media