Community hub
Recent from talks
Knowledge base stats:
Talk channels stats:
Members stats:
Feature learning
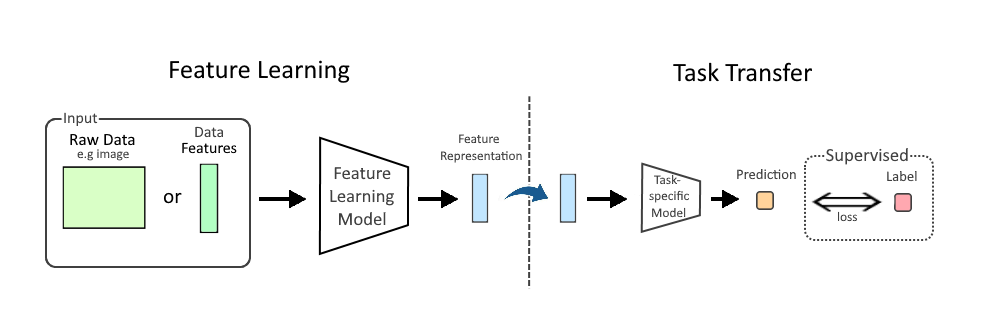
In machine learning (ML), feature learning or representation learning is a set of techniques that allow a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
Feature learning is motivated by the fact that ML tasks such as classification often require input that is mathematically and computationally convenient to process. However, real-world data, such as image, video, and sensor data, have not yielded to attempts to algorithmically define specific features. An alternative is to discover such features or representations through examination, without relying on explicit algorithms.
Feature learning can be either supervised, unsupervised, or self-supervised:
Supervised feature learning is learning features from labeled data. The data label allows the system to compute an error term, the degree to which the system fails to produce the label, which can then be used as feedback to correct the learning process (reduce/minimize the error). Approaches include:
Dictionary learning develops a set (dictionary) of representative elements from the input data such that each data point can be represented as a weighted sum of the representative elements. The dictionary elements and the weights may be found by minimizing the average representation error (over the input data), together with L1 regularization on the weights to enable sparsity (i.e., the representation of each data point has only a few nonzero weights).
Supervised dictionary learning exploits both the structure underlying the input data and the labels for optimizing the dictionary elements. For example, this supervised dictionary learning technique applies dictionary learning on classification problems by jointly optimizing the dictionary elements, weights for representing data points, and parameters of the classifier based on the input data. In particular, a minimization problem is formulated, where the objective function consists of the classification error, the representation error, an L1 regularization on the representing weights for each data point (to enable sparse representation of data), and an L2 regularization on the parameters of the classifier.
Neural networks are a family of learning algorithms that use a "network" consisting of multiple layers of inter-connected nodes. It is inspired by the animal nervous system, where the nodes are viewed as neurons and edges are viewed as synapses. Each edge has an associated weight, and the network defines computational rules for passing input data from the network's input layer to the output layer. A network function associated with a neural network characterizes the relationship between input and output layers, which is parameterized by the weights. With appropriately defined network functions, various learning tasks can be performed by minimizing a cost function over the network function (weights).
Multilayer neural networks can be used to perform feature learning, since they learn a representation of their input at the hidden layer(s) which is subsequently used for classification or regression at the output layer. The most popular network architecture of this type is Siamese networks.
Hub AI
Feature learning AI simulator
(@Feature learning_simulator)
Feature learning
In machine learning (ML), feature learning or representation learning is a set of techniques that allow a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
Feature learning is motivated by the fact that ML tasks such as classification often require input that is mathematically and computationally convenient to process. However, real-world data, such as image, video, and sensor data, have not yielded to attempts to algorithmically define specific features. An alternative is to discover such features or representations through examination, without relying on explicit algorithms.
Feature learning can be either supervised, unsupervised, or self-supervised:
Supervised feature learning is learning features from labeled data. The data label allows the system to compute an error term, the degree to which the system fails to produce the label, which can then be used as feedback to correct the learning process (reduce/minimize the error). Approaches include:
Dictionary learning develops a set (dictionary) of representative elements from the input data such that each data point can be represented as a weighted sum of the representative elements. The dictionary elements and the weights may be found by minimizing the average representation error (over the input data), together with L1 regularization on the weights to enable sparsity (i.e., the representation of each data point has only a few nonzero weights).
Supervised dictionary learning exploits both the structure underlying the input data and the labels for optimizing the dictionary elements. For example, this supervised dictionary learning technique applies dictionary learning on classification problems by jointly optimizing the dictionary elements, weights for representing data points, and parameters of the classifier based on the input data. In particular, a minimization problem is formulated, where the objective function consists of the classification error, the representation error, an L1 regularization on the representing weights for each data point (to enable sparse representation of data), and an L2 regularization on the parameters of the classifier.
Neural networks are a family of learning algorithms that use a "network" consisting of multiple layers of inter-connected nodes. It is inspired by the animal nervous system, where the nodes are viewed as neurons and edges are viewed as synapses. Each edge has an associated weight, and the network defines computational rules for passing input data from the network's input layer to the output layer. A network function associated with a neural network characterizes the relationship between input and output layers, which is parameterized by the weights. With appropriately defined network functions, various learning tasks can be performed by minimizing a cost function over the network function (weights).
Multilayer neural networks can be used to perform feature learning, since they learn a representation of their input at the hidden layer(s) which is subsequently used for classification or regression at the output layer. The most popular network architecture of this type is Siamese networks.