Community hub
Jackson structured programming
View on Wikipedia
Jackson structured programming (JSP) is a method for structured programming developed by British software consultant Michael A. Jackson. It was described in his 1975 book Principles of Program Design.[1] The technique of JSP is to analyze the data structures of the files that a program must read as input and produce as output, and then produce a program design based on those data structures, so that the program control structure handles those data structures in a natural and intuitive way.
JSP describes structures (of both data and programs) using three basic structures – sequence, iteration, and selection (or alternatives). These structures are diagrammed as (in effect) a visual representation of a regular expression.
Introduction
[edit]Michael A. Jackson originally developed JSP in the 1970s. He documented the system in his 1975 book Principles of Program Design.[1] In a 2001 conference talk,[2] he provided a retrospective analysis of the original driving forces behind the method, and related it to subsequent software engineering developments. Jackson's aim was to make COBOL batch file processing programs easier to modify and maintain, but the method can be used to design programs for any programming language that has structured control constructs—sequence, iteration, and selection ("if/then/else").
Jackson Structured Programming was similar to Warnier/Orr structured programming[3][4] although JSP considered both input and output data structures while the Warnier/Orr method focused almost exclusively on the structure of the output stream.
Motivation for the method
[edit]At the time that JSP was developed, most programs were batch COBOL programs that processed sequential files stored on tape. A typical program read through its input file as a sequence of records, so that all programs had the same structure— a single main loop that processed all of the records in the file, one at a time. Jackson asserted that this program structure was almost always wrong, and encouraged programmers to look for more complex data structures. In Chapter 3 of Principles of Program Design[1] Jackson presents two versions of a program, one designed using JSP, the other using the traditional single-loop structure. Here is his example, translated from COBOL into Java. The purpose of these two programs is to recognize groups of repeated records (lines) in a sorted file, and to produce an output file listing each record and the number of times that it occurs in the file.
Here is the traditional, single-loop version of the program.
String line;
int count = 0;
String firstLineOfGroup = null;
// begin single main loop
while ((line = in.readLine()) != null) {
if (firstLineOfGroup == null || !line.equals(firstLineOfGroup)) {
if (firstLineOfGroup != null) {
System.out.println(firstLineOfGroup + " " + count);
}
count = 0;
firstLineOfGroup = line;
}
count++;
}
if (firstLineOfGroup != null) {
System.out.println(firstLineOfGroup + " " + count);
}
Here is a JSP-style version of the same program. Note that (unlike the traditional program) it has two loops, one nested inside the other. The outer loop processes groups of repeating records, while the inner loop processes the individual records in a group.
String line;
int numberOfLinesInGroup;
line = in.readLine();
// begin outer loop: process 1 group
while (line != null) {
numberOfLinesInGroup = 0;
String firstLineOfGroup = line;
// begin inner loop: process 1 record in the group
while (line != null && line.equals(firstLineOfGroup)) {
numberOfLinesInGroup++;
line = in.readLine();
}
System.out.println(firstLineOfGroup + " " + numberOfLinesInGroup);
}
Jackson criticises the traditional single-loop version for failing to process the structure of the input file (a sequence of groups containing repeating records) in a natural way. One sign of its unnatural design is that, in order to work properly, it is forced to include special code for handling the first and last record of the file.
The basic method
[edit]JSP uses semi-formal steps to capture the existing structure of a program's inputs and outputs in the structure of the program itself.
The intent is to create programs which are easy to modify over their lifetime. Jackson's major insight was that requirement changes are usually minor tweaks to the existing structures. For a program constructed using JSP, the inputs, the outputs, and the internal structures of the program all match, so small changes to the inputs and outputs should translate into small changes to the program.
JSP structures programs in terms of four component types:
- fundamental operations
- sequences
- iterations
- selections
The method begins by describing a program's inputs in terms of the four fundamental component types. It then goes on to describe the program's outputs in the same way. Each input and output is modelled as a separate Data Structure Diagram (DSD). To make JSP work for compute-intensive applications, such as digital signal processing (DSP) it is also necessary to draw algorithm structure diagrams, which focus on internal data structures rather than input and output ones.
The input and output structures are then unified or merged into a final program structure, known as a Program Structure Diagram (PSD). This step may involve the addition of a small amount of high-level control structure to marry up the inputs and outputs. Some programs process all the input before doing any output, whilst others read in one record, write one record and iterate. Such approaches have to be captured in the PSD.
The PSD, which is language neutral, is then implemented in a programming language. JSP is geared towards programming at the level of control structures, so the implemented designs use just primitive operations, sequences, iterations and selections. JSP is not used to structure programs at the level of classes and objects, although it can helpfully structure control flow within a class's methods.
JSP uses a diagramming notation to describe the structure of inputs, outputs and programs, with diagram elements for each of the fundamental component types.
A simple operation is drawn as a box.

An operation
A sequence of operations is represented by boxes connected with lines. In the example below, A is a sequence consisting of operations B, C and D.

A sequence
An iteration is again represented with joined boxes. In addition the iterated operation has a star in the top right corner of its box. In the example below, A is an iteration of zero or more invocations of operation B.

An iteration
Selection is similar to a sequence, but with a circle drawn in the top right hand corner of each optional operation. In the example, A is a selection of one and only one of operations B, C or D.

A selection
Note that it in the above diagrams, it is element A that is the sequence or iteration, not the elements B, C or D (which in the above diagrams are all elementary). Jackson gives the 'Look-down rule' to determine what an element is, i.e. look at the elements below an element to find out what it is.
A worked example
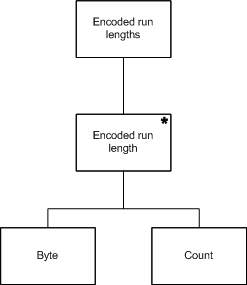
[edit]As an example, here is how a JSP programmer would design and code a run length encoder. A run length encoder is a program whose input is a stream of bytes which can be viewed as occurring in runs, where a run consists of one or more occurrences of bytes of the same value. The output of the program is a stream of byte pairs, where each byte pair is a compressed description of a run. In each pair, the first byte is the value of the repeated byte in a run and the second byte is a number indicating the number of times that that value was repeated in the run. For example, a run of eight occurrences of the letter "A" in the input stream ("AAAAAAAA") would produce "A8" as a byte pair in the output stream. Run length encoders are often used for crudely compressing bitmaps.
With JSP, the first step is to describe the data structure(s) of a program's input stream(s). The program has only one input stream, consisting of zero or more runs of the same byte value. Here is the JSP data structure diagram for the input stream.

The second step is to describe the output data structure, which in this case consists of zero or more iterations of byte pairs.
The next step is to describe the correspondences between the components of the input and output structures.

The next step is to use the correspondences between the two data structures to create a program structure that is capable of processing the input data structure and producing the output data structure. (Sometimes this isn't possible. See the discussion of structure clashes, below.)

Once the program structure is finished, the programmer creates a list of the computational operations that the program must perform, and the program structure diagram is fleshed out by hanging those operations off of the appropriate structural components.
- read a byte
- remember byte
- set counter to zero
- increment counter
- output remembered byte
- output counter
Also, at this stage conditions on iterations (loops) and selections (if-then-else or case statements) are listed and added to the program structure diagram.
- while there are more bytes
- while there are more bytes and this byte is the same as the run's first byte and the count will still fit in a byte
Once the diagram is finished, it can be translated into whatever programming language is being used. Here is a translation into C.
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
int c;
int first_byte;
int count;
c = getchar(); /* get first byte */
while (c != EOF) {
/* process the first byte in the run */
first_byte = c;
count = 1;
c = getchar(); /* get next byte */
/* process the succeeding bytes in the run */
while (c != EOF && c == first_byte && count < 255) {
/* process one byte of the same value */
count++;
c = getchar(); /* get next byte */
}
putchar(first_byte);
putchar(count);
}
return EXIT_SUCCESS;
}
Techniques for handling difficult design problems
[edit]In Principles of Program Design Jackson recognized situations that posed specific kinds of design problems, and provided techniques for handling them.
One of these situations is a case in which a program processes two input files, rather than one. In 1975, one of the standard "wicked problems" was how to design a transaction-processing program. In such a program, a sequential file of update records is run against a sequential master file, producing an updated master file as output. (For example, at night a bank would run a batch program that would update the balances in its customers' accounts based on records of the deposits and withdrawals that they had made that day.) Principles of Program Design provided a standard solution for that problem, along with an explanation of the logic behind the design.
Another kind of problem involved what Jackson called "recognition difficulties" and today we would call parsing problems. The basic JSP design technique was supplemented by POSIT and QUIT operations to allow the design of what we would now call a backtracking parser.
JSP also recognized three situations that are called "structure clashes"— a boundary clash, an ordering clash, and an interleaving clash— and provided techniques for dealing with them. In structure clash situations the input and output data structures are so incompatible that it is not possible to produce the output file from the input file. It is necessary, in effect, to write two programs— the first processes the input stream, breaks it down into smaller chunks, and writes those chunks to an intermediate file. The second program reads the intermediate file and produces the desired output.
JSP and object-oriented design
[edit]JSP was developed long before object-oriented technologies became available. It and its successor method JSD do not treat what now would be called "objects" as collections of more or less independent methods. Instead, following the work of C. A. R. Hoare, JSP and JSD describe software objects as co-routines.[5][6]
See also
[edit]References
[edit]- ^ a b c Jackson, MA (1975), Principles of Program Design, Academic.
- ^ Jackson, MA (2001), JSP in Perspective (PDF), sd&m Pioneers’ Conference, Bonn, June 2001, archived (PDF) from the original on 2017-05-16, retrieved 2017-01-26
{{citation}}: CS1 maint: location (link) CS1 maint: location missing publisher (link) - ^ Warnier, JD (1974), Logical Construction of Programs, NY: Van Nostrand Reinhold
- ^ Orr, KT (1980), "Structured programming in the 1980s", Proceedings of the ACM 1980 Annual Conference, New York, NY: ACM Press, pp. 323–26, doi:10.1145/800176.809987, ISBN 978-0897910286, S2CID 26834496
- ^ Wieringa, R (Dec 1998), "A survey of structured and object-oriented software specification methods and techniques", ACM Computing Surveys, 30 (4): 459–527, CiteSeerX 10.1.1.107.5410, doi:10.1145/299917.299919, S2CID 14967319.
- ^ Henderson-Sellers, Brian; Edwards, JM (Sep 1990), "The object-oriented systems life cycle", Communications of the ACM, 33 (9): 142–59, doi:10.1145/83880.84529, S2CID 14680399.
External links
[edit]Jackson structured programming
View on GrokipediaIntroduction and History
Definition and Overview
Jackson Structured Programming (JSP) is a methodology for designing structured programs that aligns the program's logical structure with the underlying data structures, particularly for sequential data processing tasks. Developed by Michael A. Jackson, it emphasizes deriving program control flow directly from the input and output data streams to ensure clarity and maintainability.[2][4] Key characteristics of JSP include its language independence, allowing application across various programming languages such as COBOL, C, and others without reliance on specific syntax. The approach is data-driven, prioritizing the structure of data streams over procedural logic to guide design decisions. It employs a diagrammatic notation to visually represent both data and program structures, facilitating systematic analysis and error detection early in the development process.[2][3] JSP emerged as a significant contribution to the structured programming paradigm of the 1970s, promoting modularity, top-down decomposition, and the elimination of unstructured control flows like goto statements to enhance program readability and verifiability. Its core components consist of data structure diagrams, which model input/output streams using sequences, iterations, and selections; program structure diagrams, which mirror these data patterns; and the explicit correspondence between data organization and program logic to resolve processing requirements.[2][4]Historical Development
Michael A. Jackson, a British computer scientist born in 1936, began his career in the early 1960s working as a programmer on COBOL systems for various organizations, including Maxwell Stamp Associates and the NAAFI, using machines like the IBM 1401 and Honeywell 400.[5] During this period, he encountered challenges in designing reliable data processing programs, which influenced his later methodologies. In 1971, Jackson founded Michael Jackson Systems Ltd. as an independent consulting firm, focusing on software design solutions.[5][6] Jackson developed Jackson Structured Programming (JSP) in the early 1970s as a method for designing structured programs, particularly for file-processing tasks, emphasizing alignment between data and program structures.[5][3] The methodology was first formally documented in his seminal 1975 book, Principles of Program Design, published by Academic Press, which outlined JSP's core techniques and gained rapid recognition.[5][7] By 1977, JSP had become widely known in the software community, with endorsements from figures like C. A. R. Hoare, and had been adopted as a standard (SDM/77) by the UK government; the name 'Jackson Structured Programming' was coined by a Swedish licensee in 1974.[2][7] In the late 1970s, Jackson continued refining JSP through conference presentations, such as his 1976 paper on constructive program design methods and contributions to the 1978 International Conference on Software Engineering.[7] This period saw JSP's expansion beyond individual programs to broader system design, leading to its evolution into Jackson System Development (JSD) in the early 1980s, co-developed with John Cameron to address full information system modeling.[5][7] JSD was detailed in Jackson's 1983 book, System Development, published by Prentice-Hall, marking a shift toward entity-based system specifications.[7][8] JSP saw significant adoption in education and industry during the late 1970s and 1980s, with training courses offered through Jackson's firm and European licensees, influencing structured programming practices in data processing sectors.[5] By the 1980s, integrations with computer-aided software engineering (CASE) tools emerged to automate JSP diagramming and design, enhancing its practical application in professional environments.[9][10]Motivation and Principles
Origins and Motivation
In the 1960s and 1970s, programming was dominated by unstructured code reliant on goto statements, particularly in languages like COBOL and assembly, which were commonly used for batch processing applications such as payroll and inventory systems. These environments often involved sequential file handling on tape-based systems, leading to programs that were difficult to design, debug, and maintain due to tangled control flows and frequent runtime errors during production runs.[2][11] A primary challenge was the mismatch between program logic and underlying data structures, which exacerbated errors in data-processing tasks; for instance, incompatibilities in stream ordering, boundaries, and interleaving often required awkward backtracking or ad-hoc fixes. Lack of modularity further compounded issues, as monolithic codebases resisted modifications and scaling, especially in consultancy projects handling complex serial files for industries like insurance. Michael A. Jackson, drawing from his early 1960s experiences programming assembler on IBM and Honeywell machines, observed these persistent difficulties firsthand while consulting on systems like the mid-1960s Microsystem project for an insurance broker, where dynamic batch processing demanded more reliable designs.[2][11][12] Jackson's key insight was that programs should be structured to mirror the hierarchical nature of their input and output data streams, thereby simplifying design and reducing bugs—a principle born from recognizing that "a program to process a stream is best structured in the same way as the stream itself." This data-centric motivation contrasted sharply with contemporary flowchart-based methods, which prioritized control flow and often yielded inflexible structures ill-suited to sequential data challenges, as opposed to JSP's emphasis on aligning program architecture with data logic from the outset.[2][11]Core Principles
Jackson Structured Programming (JSP) is grounded in the principle of structure preservation, which mandates that the program's control flow must mirror the hierarchical organization of its input and output data structures to ensure clarity, maintainability, and correctness.[13] This correspondence ensures that the program's logic aligns directly with the data it processes, avoiding discrepancies that could lead to errors during implementation or modification.[14] By deriving the program structure from data patterns, JSP facilitates a systematic design process where changes in data formats correspond to localized adjustments in the program.[15] At its core, JSP emphasizes serial or sequential files as the primary data focus, where basic structures—sequence, selection, and iteration—are defined by the data's organization rather than arbitrary procedural decisions.[14] Sequence represents components occurring once in a fixed order, selection allows choice among alternatives based on conditions, and iteration enables repetition of components zero or more times until a condition is met.[16] These patterns are visually captured in structure diagrams using specific notations: sequences are represented by arranging components in a linear order, iterations by marking the component with a circled plus sign (+), and selections by marking the component with a circled question mark (?) or using conditional branches, providing a precise, diagrammatic representation of data hierarchies without embedding procedural details.[14][2] JSP maintains independence from specific programming languages, making it applicable to any procedural environment such as COBOL, Fortran, or Pascal, thereby promoting designs that enhance readability and verifiability across implementations.[15] This language neutrality stems from its focus on abstract structural elements rather than syntactic constructs.[13] Furthermore, JSP rigorously avoids arbitrary control flows, such as unrestricted jumps or gotos, by enforcing structured constructs that follow the data-derived logic, ensuring a predictable and analyzable program flow free from unstructured elements.[14]The Basic JSP Method
Steps in the Basic Method
The basic method of Jackson Structured Programming (JSP) outlines a sequential workflow for designing simple programs by deriving the control structure directly from the data structures of inputs and outputs, promoting structured and maintainable code.Principles of Program Design, M. A. Jackson, Academic Press, 1975 This approach avoids arbitrary control flows, instead ensuring the program's logic mirrors the inherent organization of the data it processes, as detailed in Jackson's foundational work.[9] The process begins with Step 1: analyzing the input and output data structures to identify fundamental patterns, including sequences (ordered elements), selections (alternative branches), and iterations (repeating elements). This analysis examines how data arrives or is produced—such as linear streams, nested variants, or looped records—to reveal the logical relationships that the program must accommodate, forming the foundation for subsequent design decisions.[9] Step 2 involves constructing data structure diagrams for the inputs and outputs using standard notation, which employs simple symbols to denote basic components like operations (represented as boxes), sequences (connected linearly), iterations (marked with asterisks for repetition), and selections (indicated by circles for choices). These diagrams provide a visual yet formal representation of the data's hierarchy and variability, enabling precise identification of correspondences between inputs and outputs without introducing extraneous program complexity.[17] In Step 3, the program structure is designed to match the data structures, establishing a one-to-one correspondence where each data element or pattern directly maps to a corresponding program segment, such as a sequence of operations or an iterative loop. This matching preserves the data's natural structure in the program, minimizing the risk of unstructured code like goto statements and ensuring the overall flow reflects the problem's requirements.[2] Step 4 refines the initial program structure by incorporating substructures for nested data elements and conditionals to handle selections or variant cases, while verifying completeness through checks for coverage of all identified patterns and potential edge conditions. This refinement iterates on the matched structure, adding necessary details like bounds for iterations or guards for selections to confirm the design fully addresses the data processing needs without gaps or redundancies.[8] The final Step 5 generates pseudocode from the refined structure diagram, emphasizing modularity by breaking the design into independent, hierarchically organized components that can be easily translated into a target programming language. This pseudocode uses structured constructs like if-then-else for selections and while-do for iterations, serving as an intermediate artifact that maintains the design's integrity during implementation.[9]Structure Diagrams
Structure diagrams in Jackson Structured Programming (JSP) employ a specialized diagrammatic notation to represent both data and program structures, facilitating the alignment between input/output data streams and the corresponding program logic.[17] The notation uses simple symbols to denote fundamental structural elements: basic operations are represented by rectangles. Sequences of components that occur in a fixed order are shown by connecting rectangles with straight lines. Iterations, where a component repeats zero or more times, are indicated by an asterisk (*) placed in the top-right corner of the relevant rectangle. Selections, where one of several alternative components is chosen based on conditions, are marked by a circle (o) in the top-right corner of the rectangle. Straight lines also connect substructures to illustrate hierarchical relationships within the overall structure.[18] There are three primary types of structure diagrams in JSP: the Input Structure Diagram (ISD), which models the organization of input data streams; the Output Structure Diagram (OSD), which outlines the structure of generated outputs; and the Program Structure Diagram (PSD), which integrates the ISD and OSD to define the program's operational flow.[17] Construction begins with developing the ISD and OSD to capture the inherent structures of data, followed by deriving the PSD that parallels these data diagrams to ensure the program mirrors the data's complexity without introducing unnecessary elements.[17] A key rule during construction is to avoid clashes in structural complexity, meaning that iterative or selective elements in the data must be matched by corresponding program constructs, preventing mismatches that could lead to unstructured code.[17] Correspondence rules ensure tight alignment between program operations and data elements, such that each structural component in the PSD directly corresponds to an element in the ISD or OSD—for instance, an iteration in the data structure is processed by a single iterative operation in the program, maintaining one-to-one mapping.[17] This parallelism promotes modular, comprehensible designs where program logic naturally follows data flow. Validation of these diagrams requires checking for completeness, where all necessary components are included; balance, ensuring inputs and outputs are symmetrically handled; and absence of unstructured elements, such as arbitrary jumps or unmodeled conditions that violate the method's principles.[17] These criteria confirm that the diagrams accurately reflect a structured solution to the problem.[17]Handling Serial Files
Serial files, also known as sequential files, consist of linear, ordered data streams that lack random access capabilities and must be processed in a fixed sequence from beginning to end. These files were prevalent in 1970s batch processing systems, where data was typically stored on magnetic tapes or early disk systems, requiring programs to read or write records one after another without skipping or backtracking except through rewinding.[2] In Jackson Structured Programming (JSP), serial files are modeled as fundamental data structures using sequence or iteration constructs in structure diagrams, ensuring that the program's control flow aligns precisely with the file's sequential nature. This approach mandates that input and output operations occur in lockstep with the program's iterations, where each loop cycle corresponds to processing one record or group of records, thereby mirroring the file's inherent order.[19][8] Key techniques in JSP for handling serial files include matching the file's structure directly to program loops, such as using iterations to process repeating record groups, and employing selections to manage variable-length records where the number or size of sub-records varies. For instance, a file with variable-length records might be diagrammed as a sequence of fixed headers followed by an optional iteration of variable fields, allowing the program to read until an end marker or length indicator is encountered, often via a single read-ahead rule that loads the next record immediately after processing the current one. This ensures efficient traversal without buffering excess data.[8][2] The benefits of this JSP method for serial file processing lie in its ability to reduce errors in input/output operations by enforcing a direct correspondence between data flow and program logic, such as performing exactly one read per iteration to avoid missing or duplicating records. This alignment promotes clearer, more maintainable code, particularly in batch environments where data integrity is critical.[19][8] However, JSP's techniques are optimized for linear data flows and perform best with straightforward serial files; for more complex structures involving multiple interleaved files or non-sequential access patterns, additional extensions like intermediate buffering or structure transformations are required to resolve mismatches.[2]Examples and Applications
Worked Example
To illustrate the basic Jackson Structured Programming (JSP) method, consider a simple problem: processing a serial input file containing employee records to generate a report listing only the employees from the "Sales" department, including their names and salaries. The input file consists of records in sequence, each containing a department code, employee name, and salary, and is assumed to be sorted by department code for structural alignment. This example demonstrates how JSP preserves data structures in the program design to minimize errors. The first step is to construct the Input Structure Diagram (ISD) for the serial file. The ISD represents the logical structure of the input data as a sequence of employee records, where each record is a serial component of fields. Since the file is sorted by department, it can be viewed as groups of records sharing the same department code, enabling nested iterations.Employee File
|
+-- Department Group *
|
+-- Employee Record *
|
+-- dept_code -- name -- salary
Sales Report
|
+-- Selected Employee *
|
+-- name -- salary
Process Employee File for Sales Report
|
+-- Department Group * (select if dept_code = "Sales")
|
+-- Employee Record *
|
+-- if selected:
| +-- name -- [salary](/page/Salary) (output)
+-- dept_code -- name -- [salary](/page/Salary) (input)
process_sales_report:
reset(input_file);
read_next_record(dept_code, name, [salary](/page/Salary)); // Initial read
while not end_of_file:
current_dept := dept_code;
if current_dept = "[Sales](/page/Sales)":
// Process group for [Sales](/page/Sales)
while not end_of_file and dept_code = current_dept:
output name;
output [salary](/page/Salary);
[newline](/page/Newline);
read_next_record(dept_code, name, [salary](/page/Salary));
else:
// Skip non-Sales group
while not end_of_file and dept_code = current_dept:
read_next_record(dept_code, name, [salary](/page/Salary));
close(input_file);