
Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
In computer programming, the block starting symbol (abbreviated to .bss or bss) is the portion of an object file, executable, or assembly language code that contains statically allocated variables that are declared but have not been assigned a value yet. It is often referred to as the "bss section" or "bss segment".
Typically only the length of the bss section, but no data, is stored in the object file. The program loader allocates memory for the bss section when it loads the program. By placing variables with no value in the .bss section, instead of the .data or .rodata section which require initial value data, the size of the object file is reduced.
On some platforms, some or all of the bss section is initialized to zeroes. Unix-like systems and Windows initialize the bss section to zero, which can thus be used for C and C++ statically allocated variables that are initialized to all zero bits. Operating systems may use a technique called zero-fill-on-demand to efficiently implement the bss segment.[1] In embedded software, the bss segment is mapped into memory that is initialized to zero by the C run-time system before main() is entered. Some C run-time systems may allow part of the bss segment not to be initialized; C variables must explicitly be placed into that portion of the bss segment.[2]
On some computer architectures, the application binary interface also supports an sbss segment for "small data". Typically, these data items can be accessed using shorter instructions that may only be able to access a certain range of addresses. Architectures supporting thread-local storage might use a tbss section for uninitialized, static data marked as thread-local.[3]
Origin
[edit]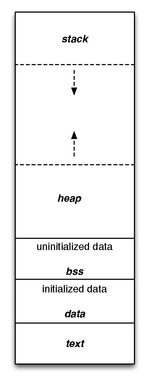
Historically, BSS (from Block Started by Symbol) is a pseudo-operation in UA-SAP (United Aircraft Symbolic Assembly Program), the assembler developed in the mid-1950s for the IBM 704 by Roy Nutt, Walter Ramshaw, and others at United Aircraft Corporation.[4][5] The BSS keyword was later incorporated into FORTRAN Assembly Program[6] (FAP) and Macro Assembly Program[7] (MAP), IBM's standard assemblers for its 709 and 7090/94 computers. It defined a label (i.e. symbol) and reserved a block of uninitialized space for a given number of words.[8] In this situation BSS served as a shorthand in place of individually reserving a number of separate smaller data locations. Some assemblers support a complementary or alternative directive BES, for Block Ended by Symbol, where the specified symbol corresponds to the end of the reserved block.[9]
BSS in C
[edit]In C, statically allocated objects without an explicit initializer are initialized to zero (for arithmetic types) or a null pointer (for pointer types). Implementations of C typically represent zero values and null pointer values using a bit pattern consisting solely of zero-valued bits (despite filling bss with zero is not required by the C standard, all variables in .bss are required to be individually initialized to some sort of zeroes according to Section 6.7.8 of C ISO Standard 9899:1999 or section 6.7.9 for newer standards). Hence, the BSS segment typically includes all uninitialized objects (both variables and constants) declared at file scope (i.e., outside any function) as well as uninitialized static local variables (local variables declared with the static keyword); static local constants must be initialized at declaration, however, as they do not have a separate declaration, and thus are typically not in the BSS section, though they may be implicitly or explicitly initialized to zero. An implementation may also assign statically-allocated variables and constants initialized with a value consisting solely of zero-valued bits to the BSS section.
Peter van der Linden, a C programmer and author, says, "Some people like to remember it as 'Better Save Space'. Since the BSS segment only holds variables that don't have any value yet, it doesn't actually need to store the image of these variables. The size that BSS will require at runtime is recorded in the object file, but BSS (unlike the data segment) doesn't take up any actual space in the object file."[10]
BSS in Fortran
[edit]In Fortran, common block variables are allocated in this segment.[11] Some compilers may, for 64-bit instruction sets, limit offsets, in instructions that access this segment, to 32 bits, limiting its size to 2 GB or 4 GB.[12][13][14] Also, note that Fortran does not require static data to be initialized to zero. On those systems where the bss segment is initialized to zero, putting common block variables and other static data into that segment guarantees that it will be zero, but for portability, programmers should not depend on that.
See also
[edit]References
[edit]- ^ McKusick, Marshall Kirk; Karels, Michael J. (1986). "A New Virtual Memory Implementation for Berkeley UNIX" (PDF). University of California, Berkeley. p. 3. CiteSeerX 10.1.1.368.432.
- ^ "Memory Sections". AVR Libc Home page.
- ^ "ELF Special Sections". Linux Standard Base PDA Specification 3.0RC1.
- ^ Network Dictionary. Javvin Press, 2007, p. 70.
- ^ Coding for the MIT-IBM 704 Computer October 1957, p. V-10
- ^ FORTRAN ASSEMBLY PROGRAM (FAP) for the IBM 709/7090 (PDF). IBM. 1961. p. 30. J28-6098-1. Retrieved 18 October 2017.
- ^ IBM 7090/7094 IBSYS Operating System Version 13 Macro Assembly Program (MAP) Language (PDF). IBM. 1963. C28-6392-4.
- ^ Timar, Ted; et al. (1996). "Unix - Frequently Asked Questions (1/7)". Question 1.3.
- ^ Free Software Foundation, Inc. "38.9. Directives". Using as: Using as, the Gnu Assembler. Archived from the original on March 19, 2014. Retrieved Feb 22, 2014.
- ^ Peter van der Linden, Expert C Programming: Deep C Secrets, Prentice Hall 1994, p. 141
- ^ How does Fortran 77 allocate common-block variables?
- ^ "IBM RS/6000 and PowerPC Options". Using the GNU Compiler Collection (GCC) – GCC 7.2.0.
- ^ "SPARC Options". Using the GNU Compiler Collection (GCC) – GCC 7.2.0.
- ^ "x86 Options". Using the GNU Compiler Collection (GCC) – GCC 7.2.0.
- Stevens, W. Richard (1992). Advanced Programming in the Unix Environment. Addison–Wesley. Section 7.6. ISBN 0-201-56317-7.
Overview
Definition and Purpose
The .bss section, standing for "block started by symbol," is a dedicated segment in object files, executables, and assembly code that allocates space for global and static variables declared without explicit initialization, treating them as zero-initialized.[5] In formats like ELF, it is defined as holding uninitialized data that contributes to the program's memory image, with the system responsible for zero-filling the area upon loading.[6] The primary purpose of the .bss section is to efficiently reserve memory for such variables without embedding their zero values directly in the object file, which would unnecessarily inflate its size.[7] Instead, the section uses a special type (SHT_NOBITS in ELF) that occupies no on-disk space but specifies the required memory allocation, allowing the loader or operating system to initialize it to zeros at runtime.[6] This approach optimizes storage and loading, particularly for large arrays or blocks of uninitialized data. Unlike the .data section, which stores global and static variables with explicit non-zero initial values embedded in the file (using SHT_PROGBITS in ELF), the .bss section is exclusively for uninitialized or zero-initialized items, ensuring a clear separation that facilitates efficient program execution and debugging.[6] For example, in a C program compiled with GCC, the declarationstatic int count; results in the variable being placed in .bss, where it defaults to zero without storing that value in the object file.[8]
Key Characteristics
The .bss section is characterized by its type SHT_NOBITS in the Executable and Linking Format (ELF), which means it occupies no physical space within the object file or executable binary itself. Instead, only the size of the section is recorded in the file's section header, and the operating system loader allocates the corresponding memory at runtime, typically as part of the data segment in the program's virtual address space. This design ensures that the file remains compact while reserving space for uninitialized data that will be populated during program execution. All variables placed in the .bss section are implicitly initialized to zero by the operating system when the program starts, without requiring explicit zero values in the source code. However, for variables explicitly initialized to zero (such asint x = 0;), many compilers, including GCC, optimize by placing them in .bss rather than the .data section to further reduce file size, though this behavior can be disabled with options like -fno-zero-initialized-in-bss. This implicit zero-filling occurs automatically as part of the loader's process, ensuring predictable starting values for uninitialized storage.[9]
The .bss section primarily accommodates file-scope global variables and static variables that lack explicit initialization, including static variables declared within functions, which are effectively treated as globals with limited visibility. This scoping ensures that such variables persist across function calls and maintain their zero-initialized state throughout the program's lifetime.
In terms of structure, the .bss section is typically aligned to word boundaries (such as 4 or 8 bytes, depending on the architecture) via the section header's sh_addralign field, which must be a power of two, and its total size is often rounded up to the next alignment boundary for efficient memory access. In the standard virtual memory layout of a program, .bss follows immediately after the .data segment, extending the data segment's memory image and contributing to the difference between the segment's file size (p_filesz) and memory size (p_memsz) in ELF program headers.[10]
Historical Development
Origins in Early Computing
The .bss section traces its origins to early assemblers developed for IBM mainframe computers in the 1950s. The acronym "BSS" stands for "Block Started by Symbol," a pseudo-operation first introduced in the United Aircraft Symbolic Assembly Program (UA-SAP) for the IBM 704 around 1956. This directive was later adopted in assemblers like the FORTRAN Assembly Program (FAP) for the IBM 709 and 7090 systems in 1959.[11] It enabled programmers to allocate blocks of consecutive memory locations for uninitialized data or working storage without generating explicit binary output in the object code. The BSS operation addressed limitations in the era's resource-constrained environments by optimizing object file size and assembly efficiency, as it simply advanced the location counter by the specified amount, leaving initialization—typically to zero—to the loader at program execution time. This was particularly important on systems like the IBM 704 and 7090/7094, where memory and I/O resources were limited.[12] In practice, the directive was used in assembly code with a format such assymbol BSS expression, where the optional symbol defined the starting address and the absolute expression specified the block size in words. For instance, BUFFER BSS 100 reserved 100 words beginning at the location labeled BUFFER, without storing any values.[11] The first documentation of BSS appears in manuals from UA-SAP in the mid-1950s, with further elaboration in IBM's FAP manuals from the early 1960s, reflecting its roots in early symbolic assembly programming where space conservation was paramount for batch processing and program portability.
As IBM transitioned to the System/360 architecture in 1964, the BSS concept influenced subsequent assemblers, though the specific directive was replaced by equivalents like the DS (Define Storage) instruction in Basic Assembler Language (BAL) to achieve similar uninitialized reservation.[13]
Adoption and Evolution in Unix-like Systems
The .bss section was introduced to Unix in the early 1970s through PDP-11 assemblers, where it served as a dedicated portion of object files for uninitialized data, building on earlier computing conventions to optimize memory usage in resource-constrained environments.[14] This integration aligned with the development of the first PDP-11 Unix versions around 1972, enabling efficient handling of global and static variables without explicit initialization in the binary.[15] By Version 6 Unix, released in May 1975, the .bss mechanism was standardized within the a.out object file format, specifying a fixed field for the size of uninitialized data to ensure consistent loading across systems.[16] The evolution continued with AT&T Unix System V in 1983, where .bss was formalized as a standard section in the Common Object File Format (COFF), replacing the simpler a.out structure for better support on diverse 32-bit architectures like the 3B20. This shift improved relocation and section management, allowing .bss to represent uninitialized data without bloating file sizes.[17] In the 1990s, as Linux gained prominence, .bss was adapted into the Executable and Linkable Format (ELF), adopted widely by mid-decade for enhanced portability and extensibility across Unix-like systems; ELF treats .bss as a NOBITS section, allocating memory at runtime without storing zeros on disk.[6] Brian Kernighan and Dennis Ritchie's "The C Programming Language" (1978) played a pivotal role in spreading .bss concepts, as the book described external and static variables as implicitly zero-initialized if unspecified, aligning with Unix's .bss handling and influencing C's adoption in Unix development. As of 2025, .bss remains a core element in POSIX-compliant systems, integral to ELF executables for efficient memory mapping.[7] In Apple ecosystems, enhancements via LLVM and the Mach-O format since the 2000s refined .bss as the __bss section, supporting zero-initialization for uninitialized statics while integrating with code-signing and ARM architectures.[18] Early Unix loaders explicitly cleared the .bss section to zero during program execution, a necessity driven by hardware limitations where reused memory from prior processes was not guaranteed to be cleared, ensuring security and predictable behavior on PDP-11 systems.[19] This practice, rooted in the a.out loader's design, persists in some embedded Unix-like systems to mitigate risks from non-zeroed RAM.[16]Usage in Programming Languages
In C and C++
In C and C++, the .bss section is used by compilers such as GCC and Clang to store global and static variables that lack an explicit initializer, ensuring they are zero-initialized at program startup. For example, a declaration likeint global_var; places the variable in .bss, where the runtime environment or startup code initializes it to zero before main() executes, as required by the C standard for objects with static storage duration.[20] This behavior optimizes executable size by avoiding storage of explicit zero values in the file.[9]
Variables explicitly initialized to zero, such as int global_var = 0;, are by default placed in .bss by GCC to leverage the same zero-filling mechanism, though the -fno-zero-initialized-in-bss flag can redirect them to the .data section if needed for specific linking or debugging requirements.[9] In contrast, non-zero initializations always go to .data. This placement applies uniformly to both global variables and those declared static within functions or at file scope.
In C++, the same principles extend to static data members of classes and global variables within namespaces, which also receive static storage duration and are thus allocated in .bss if uninitialized or zero-initialized.[21] Namespaces do not alter this section placement, treating enclosed globals as standard file-scope entities. Program startup performs zero-initialization for all such objects before any dynamic initialization occurs.
Developers can manually direct variables to .bss using GCC's __attribute__((section(".bss"))) on global or static declarations, overriding default compiler decisions for custom section layouts in object files.
The following example illustrates .bss usage in C:
#include <stdio.h>
int bss_var; // Placed in .bss
int main() {
printf("Value of bss_var: %d\n", bss_var); // Outputs 0
return 0;
}
#include <stdio.h>
int bss_var; // Placed in .bss
int main() {
printf("Value of bss_var: %d\n", bss_var); // Outputs 0
return 0;
}
gcc -o example example.c) and inspected via objdump -h example, the output shows bss_var contributing to the size of the .bss section, confirming its placement for zero-initialization at runtime.
C99 and C11 introduce tentative definitions, allowing multiple declarations of the same global variable without initializers across translation units (e.g., extern int shared_var; in headers and int shared_var; in one source file); these are resolved into a single .bss allocation at link time, with the tentative ones acting as declarations unless an actual definition appears.[20] This mechanism supports modular code without duplication errors, provided exactly one definition exists.[20]
In Assembly Languages
In assembly languages, the .bss section is defined using specific directives in popular assemblers such as NASM and the GNU Assembler (GAS). In NASM, programmers initiate the .bss section with thesection .bss directive, followed by space reservation using pseudo-instructions like resb for bytes, resw for words (typically 16 bits), resd for double words (32 bits), or resq for quad words (64 bits). In GAS, the equivalent is .section .bss to switch to the section, with space allocated via .space or .zero directives specifying the number of bytes, ensuring no initial values are stored in the output file.[22]
Across architectures, the .bss usage remains consistent in GNU tools, though segment naming aligns with the target. For x86, it traditionally maps to the bss segment in flat memory models. On ARM and RISC-V architectures, GAS employs the same .section .bss directive, reserving uninitialized space that the runtime environment (e.g., loader) zeros out.[22]
During linking, symbols declared in the .bss section, such as global_var: resd 1 in NASM, receive assigned addresses in the final executable but contribute no binary content to the object file, as their space is implicitly zero-filled by the operating system loader to optimize file size.
A representative example in NASM for an ELF output targets a 1KB buffer:
section .bss
buffer resb 1024
section .bss
buffer resb 1024
In Fortran
In Fortran, uninitialized data structures such as COMMON blocks and SAVE variables are typically mapped to the .bss section during compilation and linking, where they are allocated space but not explicitly stored in the executable file, relying on runtime zero-initialization by the operating system. For instance, a declaration likeCOMMON /BLOCK/ VAR without prior initialization places VAR in .bss, allowing shared access across program units while conserving file size for large arrays common in numerical simulations.[24][25]
This approach differs from C, where global variables are explicitly declared; in Fortran, COMMON blocks serve to simulate global storage in a block-oriented manner, and .bss handles zero-initialization for extensive arrays or module data to optimize memory usage in scientific applications. Compilers like gfortran and Intel Fortran Compiler (ifort/ifx) place uninitialized EQUIVALENCE sets or MODULE variables—such as INTEGER :: arr(100) in a module without assignment—into .bss, with the linker allocating contiguous space based on the largest declaration size. Like C compilers, they place zero-initialized variables in .bss by default.[9][26]
Historically, Fortran 77 (standardized in 1978) introduced BSS-like storage for blank (unnamed) COMMON blocks, which provided implicit zero-initialization for shared uninitialized data across subroutines, evolving in Fortran 90 and later standards to support modules as a more structured alternative to COMMON for encapsulating such variables.[27][28]
MODULE example_mod
IMPLICIT NONE
INTEGER, SAVE :: arr(100) ! Uninitialized; placed in .bss by linker
END MODULE example_mod
PROGRAM main
USE example_mod
! arr is zero-initialized at runtime via .bss
PRINT *, arr(1) ! Outputs 0
END PROGRAM main
MODULE example_mod
IMPLICIT NONE
INTEGER, SAVE :: arr(100) ! Uninitialized; placed in .bss by linker
END MODULE example_mod
PROGRAM main
USE example_mod
! arr is zero-initialized at runtime via .bss
PRINT *, arr(1) ! Outputs 0
END PROGRAM main
In Other Languages and Systems
In Rust, static variables initialized to zero are placed in the .bss section to leverage runtime zero-initialization by the operating system or startup code in bare-metal environments.[29] For mutable statics usingstatic mut or crates like lazy_static!, developers can target the .bss section explicitly via custom linker scripts, which is common in embedded Rust applications to optimize memory layout.[30] For example, the declaration static mut BUFFER: [u8; 256] = [0; 256]; allocates a zero-initialized byte array in .bss, mapping to assembly as a symbol in that section without storing zeros in the binary.[29]
In embedded systems, such as those using GCC for AVR microcontrollers, the .bss section holds uninitialized global and static variables allocated in RAM, but without an operating system, zero-initialization must be performed manually in the startup code before reaching main().[31] This approach avoids including zero values in the firmware image, reducing flash usage, though the startup routine—often written in assembly—must loop to clear the .bss region explicitly.[32]
The Java Virtual Machine (JVM) does not natively employ a .bss section, as it manages memory through garbage collection and does not produce object files with traditional sections like ELF.[33] However, when Java applications interface with native code via the Java Native Interface (JNI), the underlying C or C++ libraries can use .bss for uninitialized data in their ELF binaries, emulating standard C behavior during interoperation.[34]
In the Go programming language, introduced in 2009, uninitialized global variables are allocated in an equivalent of the .bss section within ELF object files, where the runtime or loader handles zero-initialization to maintain efficiency similar to C conventions.[35] This placement ensures that globals without explicit values do not inflate the binary size, with Go's linker managing the section for static storage duration objects.[36]
Implementation in Object File Formats
In ELF Format
In the Executable and Linking Format (ELF), the .bss section is defined within the section header table as a dedicated entry with specific attributes that distinguish it from other sections containing initialized data. The section header structure includessh_name set to the string ".bss", sh_type assigned to SHT_NOBITS to indicate that it occupies no space in the file itself, and sh_flags configured with SHF_ALLOC to mark it for allocation in memory at runtime along with SHF_WRITE to permit modifications by the program.[7][6] This design ensures that uninitialized global and static variables are represented without storing explicit zero values in the binary, thereby reducing file size while reserving the necessary memory space.[6]
During the loading process, the .bss section is incorporated into a loadable program header entry of type PT_LOAD, which maps the relevant portions of the file into memory. For such segments, the p_filesz field reflects only the size of the actual file data (which is 0 for .bss due to its SHT_NOBITS type), while p_memsz specifies the full memory allocation, including the .bss contribution to ensure the loader zeros out the extended region.[7][6] The ELF format, introduced in 1992 as part of UNIX System V Release 4 (SVR4) development by UNIX System Laboratories, supports both 32-bit and 64-bit addressing, allowing .bss sections to handle large-scale allocations in modern systems.[6] Alignment for the .bss section is typically set to 8 bytes in 64-bit ELF files to match common data type requirements, as specified in the sh_addralign field of the section header.[7]
Tools like readelf and objdump provide visibility into the .bss section without revealing any file-stored data, confirming its zero-initialization occurs solely at load time. For instance, running readelf -S on an ELF object file displays the .bss entry with its sh_size (the total memory size for uninitialized variables), sh_type as NOBITS, and sh_offset as 0, indicating no on-disk content. Similarly, objdump -h lists the section with a size but no associated dump output, underscoring the absence of explicit zeros in the file.[7]
An example ELF section header for .bss in a 64-bit object file might appear as follows in hexadecimal dump or structural representation (excerpted and simplified for clarity):
Section Header (.bss):
sh_name: 0x[ index to ".bss" in string table ]
sh_type: 0x8 (SHT_NOBITS)
sh_flags: 0x3 (SHF_WRITE | SHF_ALLOC)
sh_addr: 0x[ virtual address, e.g., 0x601000 ]
sh_offset: 0x0
sh_size: 0x[ size in bytes, e.g., 0x100 for 256 bytes of uninitialized space ]
sh_link: 0x0
sh_info: 0x0
sh_addralign: 0x8
sh_entsize: 0x0
Section Header (.bss):
sh_name: 0x[ index to ".bss" in string table ]
sh_type: 0x8 (SHT_NOBITS)
sh_flags: 0x3 (SHF_WRITE | SHF_ALLOC)
sh_addr: 0x[ virtual address, e.g., 0x601000 ]
sh_offset: 0x0
sh_size: 0x[ size in bytes, e.g., 0x100 for 256 bytes of uninitialized space ]
sh_link: 0x0
sh_info: 0x0
sh_addralign: 0x8
sh_entsize: 0x0
sh_size is calculated by the linker as the aggregate size of all uninitialized variables (e.g., global arrays or buffers declared without initializers in C), ensuring precise memory reservation without inflating the file.[6] This structure exemplifies how ELF optimizes for runtime efficiency in Unix-like systems.[7]
In COFF and PE Formats
In the Common Object File Format (COFF), the .bss section is designated for uninitialized data, such as global and static variables that are not explicitly initialized in the source code.[37] This section bears the name ".bss" in the section header and is flagged with the characteristic IMAGE_SCN_CNT_UNINITIALIZED_DATA, which has a value of 0x00000080, indicating that it contains uninitialized data without any corresponding raw data stored in the file itself.[37] Developed by AT&T Bell Laboratories in the 1980s as part of early Unix object file formats and formalized in Unix System V, COFF provided a structured way to handle relocatable object code, with .bss enabling efficient representation of zero-initialized memory blocks.[17] Unlike sections for initialized data (e.g., .data), the .bss section omits raw file content to conserve disk space; instead, the loader allocates memory at runtime and initializes it to zero.[37] In the COFF section table, the entry for .bss specifies a VirtualSize field that denotes the total size of the uninitialized data in memory, while the SizeOfRawData and PointerToRawData fields are both set to 0, reflecting the absence of file-backed data.[37] For example, a typical COFF section header for .bss might appear as follows in a hexadecimal dump or tool output:| Field | Value (Example) | Description |
|---|---|---|
| Name | .bss | Section identifier |
| VirtualSize | 0x00001000 | Size in memory (e.g., 4 KB) |
| VirtualAddress | 0x00400000 | RVA in loaded image |
| SizeOfRawData | 0x00000000 | No raw data in file |
| PointerToRawData | 0x00000000 | No file offset |
| Characteristics | 0xC0000080 | Includes IMAGE_SCN_CNT_UNINITIALIZED_DATA (0x80), plus read/write/memory flags |
In Mach-O Format
In the Mach-O file format used by macOS and iOS, the .bss equivalent is represented primarily through the__bss and __common sections within the __DATA segment. The __bss section holds uninitialized static variables, such as those declared with static int var;, ensuring they are zero-initialized at runtime per C/C++ standards.[18] In contrast, the __common section accommodates tentative definitions for uninitialized external global variables, like int var; at file scope, which are resolved and zeroed during linking and loading.[18] Both sections employ the section type S_ZEROFILL (value 0x1), which signifies zero-fill-on-demand semantics, meaning no actual data is stored in the file itself to save space; instead, the sections indicate the size and alignment required for allocation. This flag distinguishes them from regular sections (S_REGULAR), as S_ZEROFILL sections lack file backing and are flagged as writable but non-executable in the __DATA segment.
During program loading, the dynamic linker dyld processes the Mach-O file's load commands to map segments into virtual memory. For S_ZEROFILL sections like __bss and __common, dyld allocates the specified memory region in the process's address space and initializes it to zero only when first accessed (read or write), leveraging the operating system's demand-paging mechanism for efficiency. This on-demand zero-filling avoids unnecessary memory operations for unused variables, and the sections support copy-on-write sharing across processes until modification.[18] Mach-O's support for universal (fat) binaries further enhances this by embedding multiple architectures (e.g., x86_64 and arm64) in a single file, with dyld selecting and loading the appropriate __DATA segment variant based on the host CPU, ensuring seamless multi-architecture handling for .bss data.
Developers can inspect these sections using tools like otool, where the command otool -l executable displays the load commands, including segment details and section types such as S_ZEROFILL for __bss. In Xcode, the compiler and linker automatically place eligible uninitialized static and global variables into these sections during object file generation and final linking.[18] The Mach-O format evolved from the Mach kernel developed in the 1980s at Carnegie Mellon University, with the full format introduced in the late 1980s for NeXT systems and adopted by Apple in macOS; optimizations for .bss handling, including better alignment and zerofill efficiency, were refined in the 2010s alongside ARM64 support for iOS devices.[41] A representative example of the relevant load command structure for the __DATA,__bss section follows a 64-bit segment command (LC_SEGMENT_64), which includes a section header with fields like sectname set to "__bss", segname to "__DATA", flags including S_ZEROFILL, addr and size for virtual allocation, and align typically as a power of 2 (e.g., 3 for 8-byte alignment).
struct segment_command_64 {
uint32_t cmd; // LC_SEGMENT_64
uint32_t cmdsize; // sizeof this command (e.g., 552 for multiple sections)
char segname[16]; // "__DATA"
uint64_t vmaddr; // Virtual memory address
uint64_t vmsize; // Total size of segment
uint64_t fileoff; // File offset (0 for zerofill parts)
uint64_t filesize; // File size (0 for zerofill)
uint32_t maxprot; // Maximum permissions
uint32_t initprot; // Initial permissions (e.g., VM_PROT_READ | VM_PROT_WRITE)
uint32_t nsects; // Number of sections (1+)
uint32_t flags; // Segment flags
// Followed by nsects * section_64 structures
};
struct section_64 {
char sectname[16]; // "__bss"
char segname[16]; // "__DATA"
uint64_t addr; // Virtual address of section
uint64_t size; // Size in bytes
uint32_t offset; // File offset (0 for S_ZEROFILL)
uint32_t align; // Log2 of alignment (e.g., 3 for 8 bytes)
uint32_t reloff; // Relocation offset (usually 0)
uint32_t nreloc; // Number of relocations (0)
uint32_t flags; // Section type: 0x1 (S_ZEROFILL)
// Additional reserved fields...
};
struct segment_command_64 {
uint32_t cmd; // LC_SEGMENT_64
uint32_t cmdsize; // sizeof this command (e.g., 552 for multiple sections)
char segname[16]; // "__DATA"
uint64_t vmaddr; // Virtual memory address
uint64_t vmsize; // Total size of segment
uint64_t fileoff; // File offset (0 for zerofill parts)
uint64_t filesize; // File size (0 for zerofill)
uint32_t maxprot; // Maximum permissions
uint32_t initprot; // Initial permissions (e.g., VM_PROT_READ | VM_PROT_WRITE)
uint32_t nsects; // Number of sections (1+)
uint32_t flags; // Segment flags
// Followed by nsects * section_64 structures
};
struct section_64 {
char sectname[16]; // "__bss"
char segname[16]; // "__DATA"
uint64_t addr; // Virtual address of section
uint64_t size; // Size in bytes
uint32_t offset; // File offset (0 for S_ZEROFILL)
uint32_t align; // Log2 of alignment (e.g., 3 for 8 bytes)
uint32_t reloff; // Relocation offset (usually 0)
uint32_t nreloc; // Number of relocations (0)
uint32_t flags; // Section type: 0x1 (S_ZEROFILL)
// Additional reserved fields...
};
Advantages and Considerations
Benefits for Memory Efficiency
The .bss section enhances memory efficiency by significantly reducing the size of executable files, as it omits storage of the actual zero bytes on disk and instead records only the section's size in the object file headers. This approach, defined by the ELF format's SHT_NOBITS type, ensures that uninitialized data contributes to the program's runtime memory image without occupying file space, allowing linkers to represent large blocks of zeros with minimal overhead.[42] For instance, a 1 MB array declared in .bss typically adds just 8 bytes to the binary for the size field in 64-bit systems, in contrast to a full 1 MB allocation in the .data section for initialized variables.[42] This space-saving mechanism is especially valuable in embedded systems with constrained storage, such as microcontrollers, where avoiding redundant zero storage in ROM or FLASH prevents unnecessary increases in firmware size and supports efficient deployment on resource-limited hardware.[43] In Linux environments, the .bss section can accommodate gigabytes of virtual memory for large uninitialized buffers—common in applications like simulations and games—without inflating the executable file, leveraging the operating system's virtual addressing to allocate space only as needed.[44] Additionally, .bss improves load time efficiency, as the operating system zero-initializes the section via memory mapping rather than copying data from the file, a process accelerated by demand paging where pages are filled with zeros upon first access.[44] This design, rooted in Unix traditions since the 1980s, facilitates sparse memory allocation in virtual address spaces by reserving address ranges without physical backing until runtime, optimizing both file I/O and initial program startup.[45]Limitations and Common Pitfalls
The .bss section relies on the runtime environment or startup code for zero-initialization of its variables, which poses challenges in freestanding implementations without an operating system. In such environments, like embedded systems or kernel development, there is no automatic zeroing by the OS loader; developers must explicitly clear the .bss section in the program's entry code, such as using a memset operation on the section's bounds. For instance, the Linux kernel manually zeros its .bss during early boot using assembly code in arch/x86/boot/header.S to clear the section with rep stosl instructions, ensuring uninitialized static data starts at zero without depending on external mechanisms.[46][47] Global and static variables placed in .bss across multiple compilation units (translation units) have no guaranteed initialization order, as specified in the C and C++ standards. This indeterminacy can result in the static initialization order fiasco, where a variable in one unit depends on another in a different unit that may not yet be constructed, leading to undefined behavior or crashes during program startup. Within a single translation unit, initialization proceeds in declaration order, but inter-unit sequencing remains unspecified to allow linker flexibility.[48] A frequent pitfall arises from assuming .bss variables begin with arbitrary non-zero values, similar to uninitialized local variables on the stack; in reality, they are zeroed, which can cause bugs in code that conditionally initializes based on non-zero checks or expects garbage values for debugging. For example, logic likeif (global_var != 0) { /* assume already set */ } may skip necessary setup, propagating zeros incorrectly through the program. In multi-threaded applications, .bss-hosted static variables are shared across threads, introducing race conditions on concurrent reads or writes without synchronization, even though C++11 mandates thread-safe initialization for function-local statics.[49]
Violations of the strict aliasing rule when using pointers to .bss variables can trigger erroneous optimizations in compilers like GCC. During the 2010s, GCC versions such as 4.4 enforced stricter aliasing at -O2, assuming incompatible pointer types (e.g., casting a pointer to a .bss int to char*) do not overlap, which led to bugs where updates via one pointer were ignored, returning stale or null values in structures.[50] To mitigate, developers often use -fno-strict-aliasing or type-compatible accesses, though this reduces optimization potential.
Consider this example of a race condition with an uninitialized static variable in .bss, accessed concurrently:
#include <thread>
#include <vector>
#include <iostream>
static int counter; // Placed in .bss, zero-initialized
void increment() {
for (int i = 0; i < 1000; ++i) {
++counter; // Race: concurrent increments may lose updates
}
}
int main() {
std::vector<std::thread> threads;
for (int i = 0; i < 10; ++i) {
threads.emplace_back(increment);
}
for (auto& t : threads) {
t.join();
}
std::cout << "Counter: " << counter << std::endl; // Expected: 10000, but often less due to races
return 0;
}
#include <thread>
#include <vector>
#include <iostream>
static int counter; // Placed in .bss, zero-initialized
void increment() {
for (int i = 0; i < 1000; ++i) {
++counter; // Race: concurrent increments may lose updates
}
}
int main() {
std::vector<std::thread> threads;
for (int i = 0; i < 10; ++i) {
threads.emplace_back(increment);
}
for (auto& t : threads) {
t.join();
}
std::cout << "Counter: " << counter << std::endl; // Expected: 10000, but often less due to races
return 0;
}
#include <atomic>
int counter = 0; // Placed in .data, explicitly initialized
void increment() {
for (int i = 0; i < 1000; ++i) {
++counter; // Still races without atomic
}
}
// Better: use std::atomic for thread-safety
std::atomic<int> atomic_counter{0}; // Thread-safe increments
#include <atomic>
int counter = 0; // Placed in .data, explicitly initialized
void increment() {
for (int i = 0; i < 1000; ++i) {
++counter; // Still races without atomic
}
}
// Better: use std::atomic for thread-safety
std::atomic<int> atomic_counter{0}; // Thread-safe increments