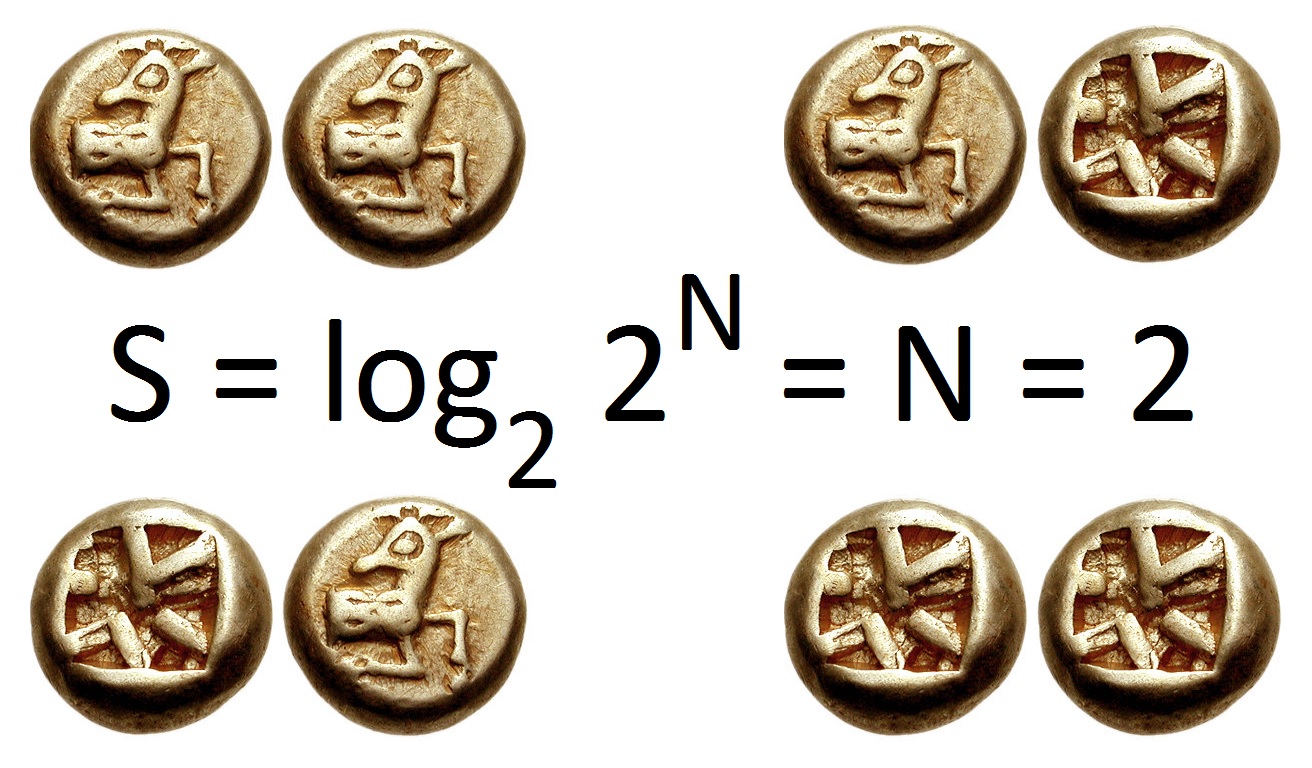
Recent from talks
Entropy (information theory)
Knowledge base stats:
Talk channels stats:
Members stats:
Entropy (information theory)
In information theory, the entropy of a random variable quantifies the average level of uncertainty or information associated with the variable's potential states or possible outcomes. This measures the expected amount of information needed to describe the state of the variable, considering the distribution of probabilities across all potential states. Given a discrete random variable , which may be any member within the set and is distributed according to , the entropy is where denotes the sum over the variable's possible values. The choice of base for , the logarithm, varies for different applications. Base 2 gives the unit of bits (or "shannons"), while base e gives "natural units" nat, and base 10 gives units of "dits", "bans", or "hartleys". An equivalent definition of entropy is the expected value of the self-information of a variable.



![{\displaystyle p\colon {\mathcal {X}}\to [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/937cff631c9e7bd8e359d598557d62ef8910597b)



The concept of information entropy was introduced by Claude Shannon in his 1948 paper "A Mathematical Theory of Communication", and is also referred to as Shannon entropy. Shannon's theory defines a data communication system composed of three elements: a source of data, a communication channel, and a receiver. The "fundamental problem of communication" – as expressed by Shannon – is for the receiver to be able to identify what data was generated by the source, based on the signal it receives through the channel. Shannon considered various ways to encode, compress, and transmit messages from a data source, and proved in his source coding theorem that the entropy represents an absolute mathematical limit on how well data from the source can be losslessly compressed onto a perfectly noiseless channel. Shannon strengthened this result considerably for noisy channels in his noisy-channel coding theorem.
Entropy in information theory is directly analogous to the entropy in statistical thermodynamics. The analogy results when the values of the random variable designate energies of microstates, so Gibbs's formula for the entropy is formally identical to Shannon's formula. Entropy has relevance to other areas of mathematics such as combinatorics and machine learning. The definition can be derived from a set of axioms establishing that entropy should be a measure of how informative the average outcome of a variable is. For a continuous random variable, differential entropy is analogous to entropy. The definition generalizes the above.
![{\displaystyle \mathbb {E} [-\log p(X)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/392d6bb368ca2b76ced69928ed3338cfab7e172d)
The core idea of information theory is that the "informational value" of a communicated message depends on the degree to which the content of the message is surprising. If a highly likely event occurs, the message carries very little information. On the other hand, if a highly unlikely event occurs, the message is much more informative. For instance, the knowledge that some particular number will not be the winning number of a lottery provides very little information, because any particular chosen number will almost certainly not win. However, knowledge that a particular number will win a lottery has high informational value because it communicates the occurrence of a very low probability event.
The information content, also called the surprisal or self-information, of an event is a function that increases as the probability of an event decreases. When is close to 1, the surprisal of the event is low, but if is close to 0, the surprisal of the event is high. This relationship is described by the function where is the logarithm, which gives 0 surprise when the probability of the event is 1. In fact, log is the only function that satisfies а specific set of conditions defined in section § Characterization.



Hence, we can define the information, or surprisal, of an event by
or equivalently,


Entropy measures the expected (i.e., average) amount of information conveyed by identifying the outcome of a random trial. This implies that rolling a die has higher entropy than tossing a coin because each outcome of a die toss has smaller probability () than each outcome of a coin toss ().


Hub AI
Entropy (information theory) AI simulator
(@Entropy (information theory)_simulator)
Entropy (information theory)
In information theory, the entropy of a random variable quantifies the average level of uncertainty or information associated with the variable's potential states or possible outcomes. This measures the expected amount of information needed to describe the state of the variable, considering the distribution of probabilities across all potential states. Given a discrete random variable , which may be any member within the set and is distributed according to , the entropy is where denotes the sum over the variable's possible values. The choice of base for , the logarithm, varies for different applications. Base 2 gives the unit of bits (or "shannons"), while base e gives "natural units" nat, and base 10 gives units of "dits", "bans", or "hartleys". An equivalent definition of entropy is the expected value of the self-information of a variable.
The concept of information entropy was introduced by Claude Shannon in his 1948 paper "A Mathematical Theory of Communication", and is also referred to as Shannon entropy. Shannon's theory defines a data communication system composed of three elements: a source of data, a communication channel, and a receiver. The "fundamental problem of communication" – as expressed by Shannon – is for the receiver to be able to identify what data was generated by the source, based on the signal it receives through the channel. Shannon considered various ways to encode, compress, and transmit messages from a data source, and proved in his source coding theorem that the entropy represents an absolute mathematical limit on how well data from the source can be losslessly compressed onto a perfectly noiseless channel. Shannon strengthened this result considerably for noisy channels in his noisy-channel coding theorem.
Entropy in information theory is directly analogous to the entropy in statistical thermodynamics. The analogy results when the values of the random variable designate energies of microstates, so Gibbs's formula for the entropy is formally identical to Shannon's formula. Entropy has relevance to other areas of mathematics such as combinatorics and machine learning. The definition can be derived from a set of axioms establishing that entropy should be a measure of how informative the average outcome of a variable is. For a continuous random variable, differential entropy is analogous to entropy. The definition generalizes the above.
The core idea of information theory is that the "informational value" of a communicated message depends on the degree to which the content of the message is surprising. If a highly likely event occurs, the message carries very little information. On the other hand, if a highly unlikely event occurs, the message is much more informative. For instance, the knowledge that some particular number will not be the winning number of a lottery provides very little information, because any particular chosen number will almost certainly not win. However, knowledge that a particular number will win a lottery has high informational value because it communicates the occurrence of a very low probability event.
The information content, also called the surprisal or self-information, of an event is a function that increases as the probability of an event decreases. When is close to 1, the surprisal of the event is low, but if is close to 0, the surprisal of the event is high. This relationship is described by the function where is the logarithm, which gives 0 surprise when the probability of the event is 1. In fact, log is the only function that satisfies а specific set of conditions defined in section § Characterization.
Hence, we can define the information, or surprisal, of an event by
or equivalently,
Entropy measures the expected (i.e., average) amount of information conveyed by identifying the outcome of a random trial. This implies that rolling a die has higher entropy than tossing a coin because each outcome of a die toss has smaller probability () than each outcome of a coin toss ().
Recent media