Recent from talks
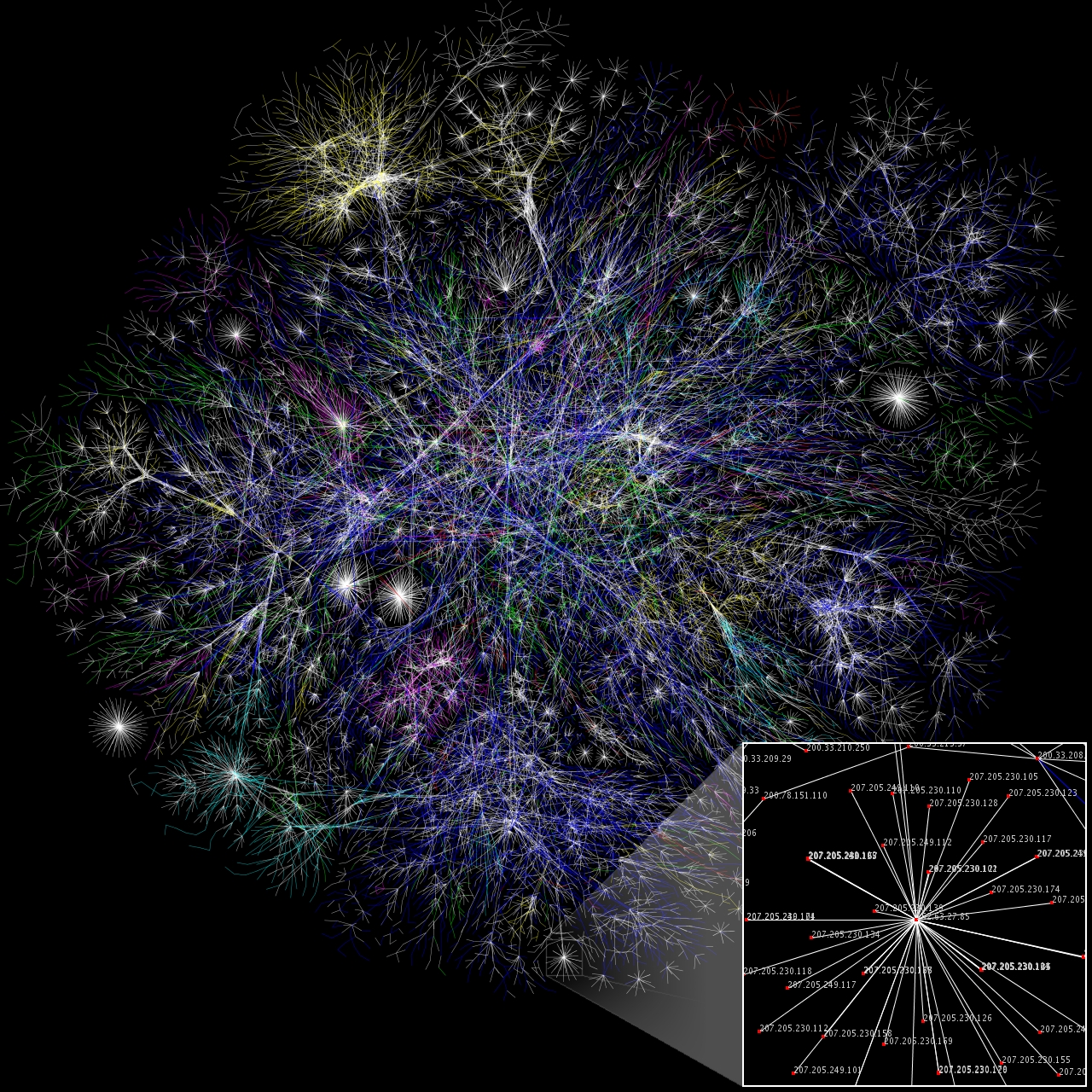
Barabási–Albert model
Knowledge base stats:
Talk channels stats:
Members stats:
Barabási–Albert model
The Barabási–Albert (BA) model is an algorithm for generating random scale-free networks using a preferential attachment mechanism. Several natural and human-made systems, including the Internet, the World Wide Web, citation networks, and some social networks are thought to be approximately scale-free and certainly contain few nodes (called hubs) with unusually high degree as compared to the other nodes of the network. The BA model tries to explain the existence of such nodes in real networks. The algorithm is named for its inventors Albert-László Barabási and Réka Albert.
Many observed networks (at least approximately) fall into the class of scale-free networks, meaning that they have power-law (or scale-free) degree distributions, while random graph models such as the Erdős–Rényi (ER) model and the Watts–Strogatz (WS) model do not exhibit power laws. The Barabási–Albert model is one of several proposed models that generate scale-free networks. It incorporates two important general concepts: growth and preferential attachment. Both growth and preferential attachment exist widely in real networks.
Growth means that the number of nodes in the network increases over time.
Preferential attachment means that the more connected a node is, the more likely it is to receive new links. Nodes with a higher degree have a stronger ability to grab links added to the network. Intuitively, the preferential attachment can be understood if we think in terms of social networks connecting people. Here a link from A to B means that person A "knows" or "is acquainted with" person B. Heavily linked nodes represent well-known people with lots of relations. When a newcomer enters the community, they are more likely to become acquainted with one of those more visible people rather than with a relative unknown. The BA model was proposed by assuming that in the World Wide Web, new pages link preferentially to hubs, i.e. very well known sites such as Google, rather than to pages that hardly anyone knows. If someone selects a new page to link to by randomly choosing an existing link, the probability of selecting a particular page would be proportional to its degree. The BA model claims that this explains the preferential attachment probability rule.
Later, the Bianconi–Barabási model works to address this issue by introducing a "fitness" parameter. Preferential attachment is an example of a positive feedback cycle where initially random variations (one node initially having more links or having started accumulating links earlier than another) are automatically reinforced, thus greatly magnifying differences. This is also sometimes called the Matthew effect, "the rich get richer". See also autocatalysis.
The only parameter in the BA model is , a positive integer. The network initializes with a network of nodes.


At each step, add one new node, then sample neighbors among the existing vertices from the network, with a probability that is proportional to the number of links that the existing nodes already have (The original papers did not specify how to handle cases where the same existing node is chosen multiple times.). Formally, the probability that the new node is connected to node is


where is the degree of node and the sum is made over all pre-existing nodes (i.e. the denominator results in twice the current number of edges in the network). This step can be performed by first uniformly sampling one edge, then sampling one of the two vertices on the edge.


Hub AI
Barabási–Albert model AI simulator
(@Barabási–Albert model_simulator)
Barabási–Albert model
The Barabási–Albert (BA) model is an algorithm for generating random scale-free networks using a preferential attachment mechanism. Several natural and human-made systems, including the Internet, the World Wide Web, citation networks, and some social networks are thought to be approximately scale-free and certainly contain few nodes (called hubs) with unusually high degree as compared to the other nodes of the network. The BA model tries to explain the existence of such nodes in real networks. The algorithm is named for its inventors Albert-László Barabási and Réka Albert.
Many observed networks (at least approximately) fall into the class of scale-free networks, meaning that they have power-law (or scale-free) degree distributions, while random graph models such as the Erdős–Rényi (ER) model and the Watts–Strogatz (WS) model do not exhibit power laws. The Barabási–Albert model is one of several proposed models that generate scale-free networks. It incorporates two important general concepts: growth and preferential attachment. Both growth and preferential attachment exist widely in real networks.
Growth means that the number of nodes in the network increases over time.
Preferential attachment means that the more connected a node is, the more likely it is to receive new links. Nodes with a higher degree have a stronger ability to grab links added to the network. Intuitively, the preferential attachment can be understood if we think in terms of social networks connecting people. Here a link from A to B means that person A "knows" or "is acquainted with" person B. Heavily linked nodes represent well-known people with lots of relations. When a newcomer enters the community, they are more likely to become acquainted with one of those more visible people rather than with a relative unknown. The BA model was proposed by assuming that in the World Wide Web, new pages link preferentially to hubs, i.e. very well known sites such as Google, rather than to pages that hardly anyone knows. If someone selects a new page to link to by randomly choosing an existing link, the probability of selecting a particular page would be proportional to its degree. The BA model claims that this explains the preferential attachment probability rule.
Later, the Bianconi–Barabási model works to address this issue by introducing a "fitness" parameter. Preferential attachment is an example of a positive feedback cycle where initially random variations (one node initially having more links or having started accumulating links earlier than another) are automatically reinforced, thus greatly magnifying differences. This is also sometimes called the Matthew effect, "the rich get richer". See also autocatalysis.
The only parameter in the BA model is , a positive integer. The network initializes with a network of nodes.
At each step, add one new node, then sample neighbors among the existing vertices from the network, with a probability that is proportional to the number of links that the existing nodes already have (The original papers did not specify how to handle cases where the same existing node is chosen multiple times.). Formally, the probability that the new node is connected to node is
where is the degree of node and the sum is made over all pre-existing nodes (i.e. the denominator results in twice the current number of edges in the network). This step can be performed by first uniformly sampling one edge, then sampling one of the two vertices on the edge.
Recent media