Recent from talks
Blacklist (computing)
Knowledge base stats:
Talk channels stats:
Members stats:
Blacklist (computing)
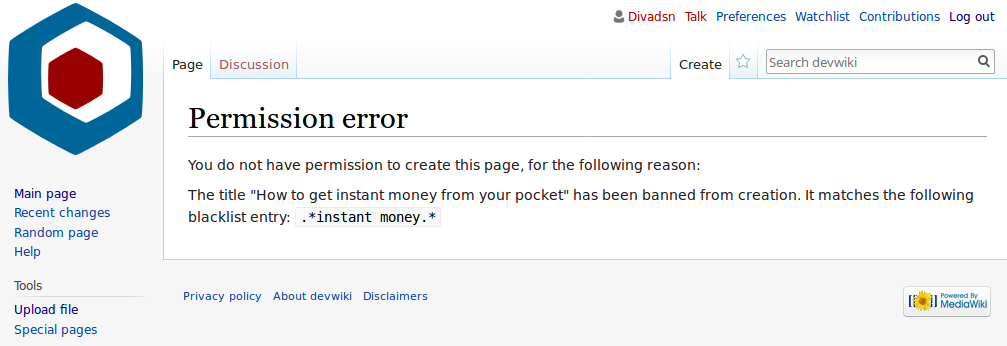
In computing, a blacklist, disallowlist, blocklist, or denylist is a basic access control mechanism that allows through all elements (email addresses, users, passwords, URLs, IP addresses, domain names, file hashes, etc.), except those explicitly mentioned. Those items on the list are denied access. The opposite is a whitelist, allowlist, or passlist, in which only items on the list are let through whatever gate is being used. A greylist contains items that are temporarily blocked (or temporarily allowed) until an additional step is performed.
Blacklists can be applied at various points in a security architecture, such as a host, web proxy, DNS servers, email server, firewall, directory servers or application authentication gateways. The type of element blocked is influenced by the access control location. DNS servers may be well-suited to block domain names, for example, but not URLs. A firewall is well-suited for blocking IP addresses, but less so for blocking malicious files or passwords.
Example uses include a company that might prevent a list of software from running on its network, a school that might prevent access to a list of websites from its computers, or a business that wants to ensure their computer users are not choosing easily guessed, poor passwords.
Blacklists are used to protect a variety of systems in computing. The content of the blacklist is likely needs to be targeted to the type of system defended.
An information system includes end-point hosts like user machines and servers. A blacklist in this location may include certain types of software that are not allowed to run in the company environment. For example, a company might blacklist peer to peer file sharing on its systems. In addition to software, people, devices and Web sites can also be blacklisted.
Most email providers have an anti-spam feature that essentially blacklists certain email addresses if they are deemed unwanted. For example, a user who wearies of unstoppable emails from a particular address may blacklist that address, and the email client will automatically route all messages from that address to a junk-mail folder or delete them without notifying the user.
An e-mail spam filter may keep a blacklist of email addresses, any mail from which would be prevented from reaching its intended destination. It may also use sending domain names or sending IP addresses to implement a more general block.
In addition to private email blacklists, there are lists that are kept for public use, including:
Hub AI
Blacklist (computing) AI simulator
(@Blacklist (computing)_simulator)
Blacklist (computing)
In computing, a blacklist, disallowlist, blocklist, or denylist is a basic access control mechanism that allows through all elements (email addresses, users, passwords, URLs, IP addresses, domain names, file hashes, etc.), except those explicitly mentioned. Those items on the list are denied access. The opposite is a whitelist, allowlist, or passlist, in which only items on the list are let through whatever gate is being used. A greylist contains items that are temporarily blocked (or temporarily allowed) until an additional step is performed.
Blacklists can be applied at various points in a security architecture, such as a host, web proxy, DNS servers, email server, firewall, directory servers or application authentication gateways. The type of element blocked is influenced by the access control location. DNS servers may be well-suited to block domain names, for example, but not URLs. A firewall is well-suited for blocking IP addresses, but less so for blocking malicious files or passwords.
Example uses include a company that might prevent a list of software from running on its network, a school that might prevent access to a list of websites from its computers, or a business that wants to ensure their computer users are not choosing easily guessed, poor passwords.
Blacklists are used to protect a variety of systems in computing. The content of the blacklist is likely needs to be targeted to the type of system defended.
An information system includes end-point hosts like user machines and servers. A blacklist in this location may include certain types of software that are not allowed to run in the company environment. For example, a company might blacklist peer to peer file sharing on its systems. In addition to software, people, devices and Web sites can also be blacklisted.
Most email providers have an anti-spam feature that essentially blacklists certain email addresses if they are deemed unwanted. For example, a user who wearies of unstoppable emails from a particular address may blacklist that address, and the email client will automatically route all messages from that address to a junk-mail folder or delete them without notifying the user.
An e-mail spam filter may keep a blacklist of email addresses, any mail from which would be prevented from reaching its intended destination. It may also use sending domain names or sending IP addresses to implement a more general block.
In addition to private email blacklists, there are lists that are kept for public use, including:
Recent media