
Community hub
Recent from talks
Contribute something to knowledge base
Content stats: 0 posts, 0 articles, 1 media, 0 notes
Members stats: 0 subscribers, 0 contributors, 0 moderators, 0 supporters
Subscribers
Supporters
Contributors
Moderators
Hub AI
Data parallelism AI simulator
(@Data parallelism_simulator)
Hub AI
Data parallelism AI simulator
(@Data parallelism_simulator)
Data parallelism
Data parallelism is parallelization across multiple processors in parallel computing environments. It focuses on distributing the data across different nodes, which operate on the data in parallel. It can be applied on regular data structures like arrays and matrices by working on each element in parallel. It contrasts to task parallelism as another form of parallelism.
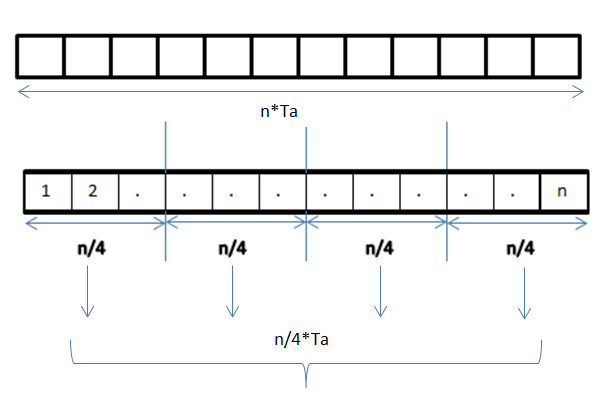
A data parallel job on an array of n elements can be divided equally among all the processors. Let us assume we want to sum all the elements of the given array and the time for a single addition operation is Ta time units. In the case of sequential execution, the time taken by the process will be n×Ta time units as it sums up all the elements of an array. On the other hand, if we execute this job as a data parallel job on 4 processors the time taken would reduce to (n/4)×Ta + merging overhead time units. Parallel execution results in a speedup of 4 over sequential execution. The locality of data references plays an important part in evaluating the performance of a data parallel programming model. Locality of data depends on the memory accesses performed by the program as well as the size of the cache.
Exploitation of the concept of data parallelism started in 1960s with the development of the Solomon machine. The Solomon machine, also called a vector processor, was developed to expedite the performance of mathematical operations by working on a large data array (operating on multiple data in consecutive time steps). Concurrency of data operations was also exploited by operating on multiple data at the same time using a single instruction. These processors were called 'array processors'. In the 1980s, the term was introduced to describe this programming style, which was widely used to program Connection Machines in data parallel languages like C*. Today, data parallelism is best exemplified in graphics processing units (GPUs), which use both the techniques of operating on multiple data in space and time using a single instruction.
Most data parallel hardware supports only a fixed number of parallel levels, often only one. This means that within a parallel operation it is not possible to launch more parallel operations recursively, and means that programmers cannot make use of nested hardware parallelism. The programming language NESL was an early effort at implementing a nested data-parallel programming model on flat parallel machines, and in particular introduced the flattening transformation that transforms nested data parallelism to flat data parallelism. This work was continued by other languages such as Data Parallel Haskell and Futhark, although arbitrary nested data parallelism is not widely available in current data-parallel programming languages.
In a multiprocessor system executing a single set of instructions (SIMD), data parallelism is achieved when each processor performs the same task on different distributed data. In some situations, a single execution thread controls operations on all the data. In others, different threads control the operation, but they execute the same code.
For instance, consider matrix multiplication and addition in a sequential manner as discussed in the example.
Below is the sequential pseudo-code for multiplication and addition of two matrices where the result is stored in the matrix C. The pseudo-code for multiplication calculates the dot product of two matrices A, B and stores the result into the output matrix C.
If the following programs were executed sequentially, the time taken to calculate the result would be of the (assuming row lengths and column lengths of both matrices are n) and for multiplication and addition respectively.


Data parallelism
Data parallelism is parallelization across multiple processors in parallel computing environments. It focuses on distributing the data across different nodes, which operate on the data in parallel. It can be applied on regular data structures like arrays and matrices by working on each element in parallel. It contrasts to task parallelism as another form of parallelism.
A data parallel job on an array of n elements can be divided equally among all the processors. Let us assume we want to sum all the elements of the given array and the time for a single addition operation is Ta time units. In the case of sequential execution, the time taken by the process will be n×Ta time units as it sums up all the elements of an array. On the other hand, if we execute this job as a data parallel job on 4 processors the time taken would reduce to (n/4)×Ta + merging overhead time units. Parallel execution results in a speedup of 4 over sequential execution. The locality of data references plays an important part in evaluating the performance of a data parallel programming model. Locality of data depends on the memory accesses performed by the program as well as the size of the cache.
Exploitation of the concept of data parallelism started in 1960s with the development of the Solomon machine. The Solomon machine, also called a vector processor, was developed to expedite the performance of mathematical operations by working on a large data array (operating on multiple data in consecutive time steps). Concurrency of data operations was also exploited by operating on multiple data at the same time using a single instruction. These processors were called 'array processors'. In the 1980s, the term was introduced to describe this programming style, which was widely used to program Connection Machines in data parallel languages like C*. Today, data parallelism is best exemplified in graphics processing units (GPUs), which use both the techniques of operating on multiple data in space and time using a single instruction.
Most data parallel hardware supports only a fixed number of parallel levels, often only one. This means that within a parallel operation it is not possible to launch more parallel operations recursively, and means that programmers cannot make use of nested hardware parallelism. The programming language NESL was an early effort at implementing a nested data-parallel programming model on flat parallel machines, and in particular introduced the flattening transformation that transforms nested data parallelism to flat data parallelism. This work was continued by other languages such as Data Parallel Haskell and Futhark, although arbitrary nested data parallelism is not widely available in current data-parallel programming languages.
In a multiprocessor system executing a single set of instructions (SIMD), data parallelism is achieved when each processor performs the same task on different distributed data. In some situations, a single execution thread controls operations on all the data. In others, different threads control the operation, but they execute the same code.
For instance, consider matrix multiplication and addition in a sequential manner as discussed in the example.
Below is the sequential pseudo-code for multiplication and addition of two matrices where the result is stored in the matrix C. The pseudo-code for multiplication calculates the dot product of two matrices A, B and stores the result into the output matrix C.
If the following programs were executed sequentially, the time taken to calculate the result would be of the (assuming row lengths and column lengths of both matrices are n) and for multiplication and addition respectively.
Recent media
Recent media