
Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
Process mining
View on WikipediaProcess mining is a family of techniques for analyzing event data to understand and improve operational processes. Part of the fields of data science and process management, process mining is generally built on logs that contain case id, a unique identifier for a particular process instance; an activity, a description of the event that is occurring; a timestamp; and sometimes other information such as resources, costs, and so on.[1][2]
There are three main classes of process mining techniques: process discovery, conformance checking, and process enhancement. In the past, terms like workflow mining and automated business process discovery (ABPD)[3] were used.
Overview
[edit]Process mining techniques are often used when no formal description of the process can be obtained by other approaches, or when the quality of existing documentation is questionable.[4] For example, application of process mining methodology to the audit trails of a workflow management system, the transaction logs of an enterprise resource planning system, or the electronic patient records in a hospital can result in models describing processes of organizations.[5] Event log analysis can also be used to compare event logs with prior model(s) to understand whether the observations conform to a prescriptive or descriptive model. It is required that the event logs data be linked to a case ID, activities, and timestamps.[6][7]
Contemporary management trends such as BAM (business activity monitoring), BOM (business operations management), and BPI (business process intelligence) illustrate the interest in supporting diagnosis functionality in the context of business process management technology (e.g., workflow management systems and other process-aware information systems). Process mining is different from mainstream machine learning, data mining, and artificial intelligence techniques. For example, process discovery techniques in the field of process mining try to discover end-to-end process models that are able to describe sequential, choice relation, concurrent and loop behavior. Conformance checking techniques are closer to optimization than to traditional learning approaches. However, process mining can be used to generate machine learning, data mining, and artificial intelligence problems. After discovering a process model and aligning the event log, it is possible to create basic supervised and unsupervised learning problems. For example, to predict the remaining processing time of a running case or to identify the root causes of compliance problems.
The IEEE Task Force on Process Mining was established in October 2009 as part of the IEEE Computational Intelligence Society.[8] This is a vendor-neutral organization that aims to promote the research, development, education and understanding of process mining, make end-users, developers, consultants, and researchers aware of the state-of-the-art in process mining, promote the use of process mining techniques and tools and stimulate new applications, play a role in standardization efforts for logging event data (e.g., XES), organize tutorials, special sessions, workshops, competitions, panels, and develop material (papers, books, online courses, movies, etc.) to inform and guide people new to the field. The IEEE Task Force on Process Mining established the International Process Mining Conference (ICPM) series,[9] lead the development of the IEEE XES standard for storing and exchanging event data[10][11], and wrote the Process Mining Manifesto[12] which was translated into 16 languages.
History and place in data science
[edit]This section needs additional citations for verification. (February 2025) |
The term "process mining" was coined in a research proposal written by the Dutch computer scientist Wil van der Aalst.[13] By 1999, this new field of research emerged under the umbrella of techniques related to data science and process science at Eindhoven University. In the early days, process mining techniques were often studied with techniques used for workflow management. In 2000, the first practical algorithm for process discovery, "Alpha miner" was developed. The next year, research papers introduced "Heuristic miner" a much similar algorithm based on heuristics. More powerful algorithms such as inductive miner were developed for process discovery. 2004 saw the development of "Token-based replay" for conformance checking. Process mining branched out "performance analysis", "decision mining" and "organizational mining" in 2005 and 2006. In 2007, the first commercial process mining company "Futura Pi" was established. In 2009, the IEEE task force on PM governing body was formed to oversee the norms and standards related to process mining. Further techniques for conformance checking led in 2010 to alignment-based conformance checking". In 2011, the first process mining book was published. About 30 commercially available process mining tools were available in 2018[citation needed].
Categories
[edit]There are three categories of process mining techniques.
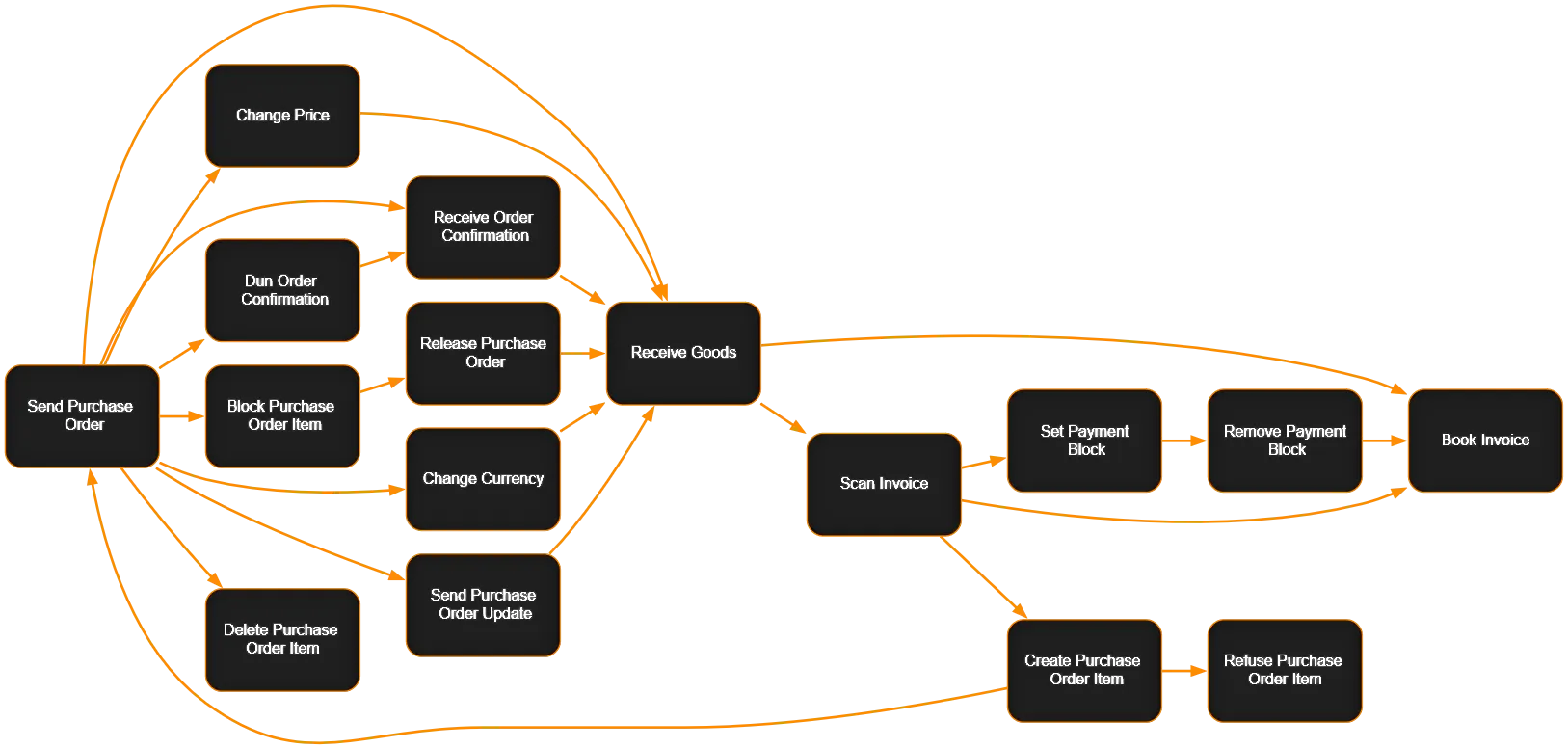
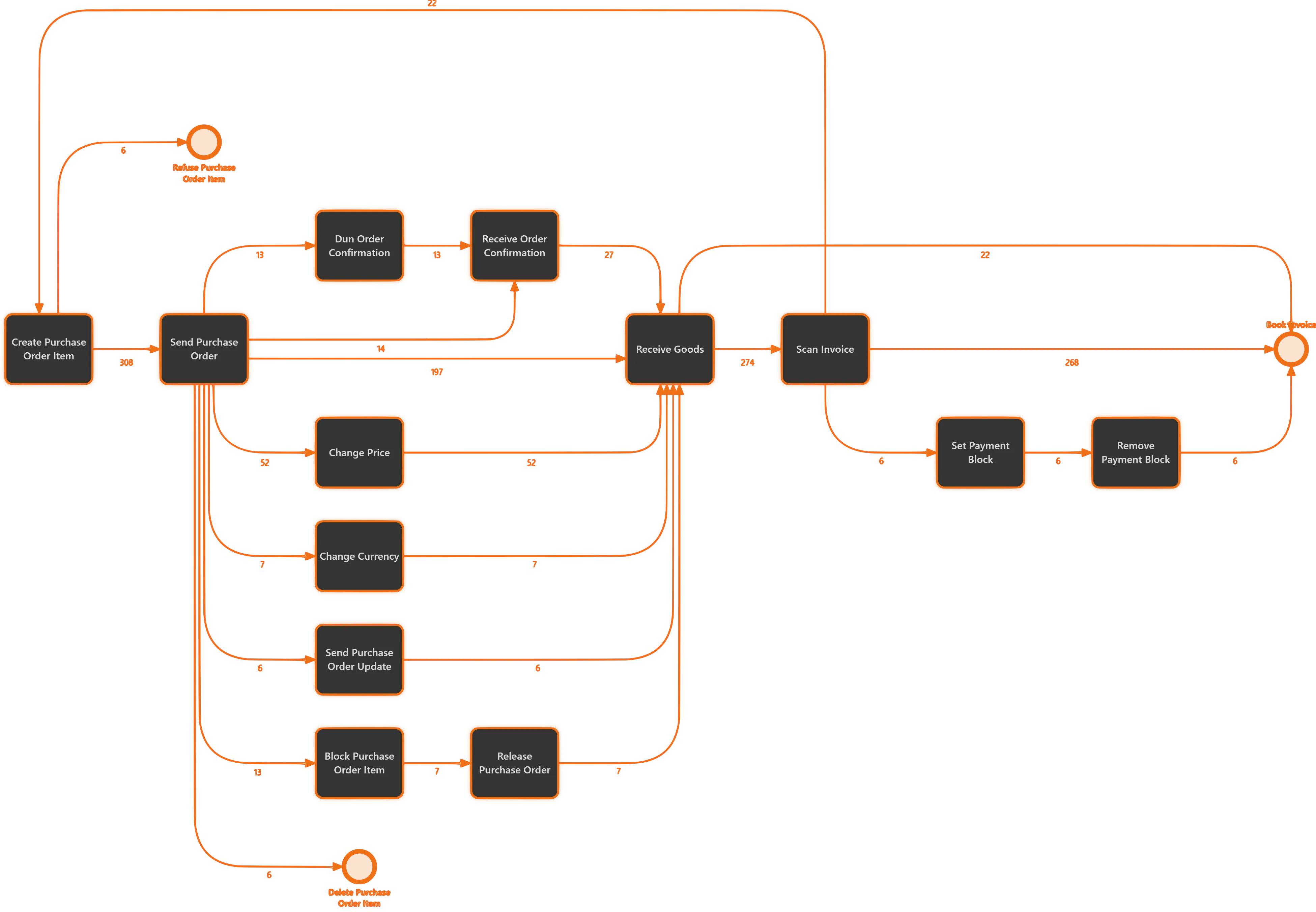
- Process discovery: The first step in process mining. The main goal of process discovery is to transform the event log into a process model. An event log can come from any data storage system that records the activities in an organisation along with the timestamps for those activities. Such an event log is required to contain a case id (a unique identifier to recognise the case to which activity belongs), activity description (a textual description of the activity executed), and timestamp of the activity execution. The result of process discovery is generally a process model which is representative of the event log. Such a process model can be discovered, for example, using techniques such as alpha algorithm (a didactically driven approach), heuristic miner, or inductive miner.[14] Many established techniques exist for automatically constructing process models (for example, Petri nets, BPMN diagrams, activity diagrams, State diagrams, and EPCs) based on an event log.[14][15][16][17][18] Recently, process mining research has started targeting other perspectives (e.g., data, resources, time, etc.). One example is the technique described in (Aalst, Reijers, & Song, 2005),[19] which can be used to construct a social network. Nowadays, techniques such as "streaming process mining" are being developed to work with continuous online data that has to be processed on the spot.
- Conformance checking: Helps in comparing an event log with an existing process model to analyse the discrepancies between them. Such a process model can be constructed manually or with the help of a discovery algorithm. For example, a process model may indicate that purchase orders of more than 1 million euros require two checks. Another example is the checking of the so-called "four-eyes" principle. Conformance checking may be used to detect deviations (compliance checking), or evaluate the discovery algorithms, or enrich an existing process model. An example is the extension of a process model with performance data, i.e., some a priori process model is used to project the potential bottlenecks. Another example is the decision miner described in (Rozinat & Aalst, 2006b),[20] which takes an a priori process model and analyses every choice in the process model. The event log is consulted for each option to see which information is typically available the moment the choice is made. Conformance checking has various techniques such as "token-based replay", "streaming conformance checking" that are used depending on the system needs.Then classical data mining techniques are used to see which data elements influence the choice. As a result, a decision tree is generated for each choice in the process.
- Performance analysis: Used when there is an a priori model. The model is extended with additional performance information such as processing times, cycle times, waiting times, costs, etc., so that the goal is not to check conformance, but rather to improve the performance of the existing model with respect to certain process performance measures. An example is the extension of a process model with performance data, i.e., some prior process model dynamically annotated with performance data. It is also possible to extend process models with additional information such as decision rules and organisational information (e.g., roles).
Process mining software
[edit]Process mining software helps organizations analyze and visualize their business processes based on data extracted from various sources, such as transaction logs or event data. This software can identify patterns, bottlenecks, and inefficiencies within a process, enabling organizations to improve their operational efficiency, reduce costs, and enhance their customer experience. In 2025, Gartner listed 40 tools in its process mining platform review category.[21]
See also
[edit]References
[edit]- ^ van der Aalst, Wil (2016). Process Mining: Data Science in Action.
- ^ van der Aalst, Wil (2011). Process Mining: Data Science in Action.
- ^ "Automated Business Process Discovery (ABPD)". Gartner.com. Gartner, Inc. 2015. Retrieved 6 January 2015.Gartner Definition.
- ^ "Gartner Top 10 Strategic Technology Trends for 2020". Gartner.
- ^ Kirchmer, M., Laengle, S., & Masias, V. (2013). Transparency-Driven Business Process Management in Healthcare Settings [Leading Edge]. Technology and Society Magazine, IEEE, 32(4), 14-16.
- ^ Luis M. Camarinha-Matos, Frederick Benaben, Willy Picard (2015). Risks and Resilience of Collaborative Networks
- ^ Symeon Christodoulou, Raimar Scherer (2016). eWork and eBusiness in Architecture, Engineering and Construction: ECPPM 2016
- ^ "IEEE Task Force on Process Mining". Home page of the task force on process mining. IEEE Task Force on Process Mining. Retrieved 10 January 2021.
- ^ "International Process Mining Conference (ICPM) series". Home page of the ICPM conference series. IEEE Task Force on Process Mining. Retrieved 10 January 2021.
- ^ IEEE Standard for eXtensible Event Stream (XES) for Achieving Interoperability in Event Logs and Event Streams. ieee. 11 November 2016. doi:10.1109/IEEESTD.2016.7740858. ISBN 978-1-5044-2421-9.
- ^ "eXtensible Event Stream (XES)". eXtensible Event Stream (XES). IEEE Task Force on Process Mining. 11 November 2016. Retrieved 10 January 2021.
- ^ "Process Mining Manifesto". Process Mining Manifesto. IEEE Task Force on Process Mining. 2011. Retrieved 10 January 2021.
- ^ Aalst, van der, W. M. P. (2000). Process design by discovery : Harvesting workflow knowledge from ad-hoc executions (Abstract). In M. Jarke, D. E. O'Leary, & R. Studer (Eds.), Knowledge Management: An Interdisciplinary Approach (Dagstuhl Seminar 00281, July 9-14, 2000) (Dagstuhl Seminar Proceedings; Vol. 281).
- ^ a b Aalst, W. van der, Weijters, A., & Maruster, L. (2004). Workflow Mining: Discovering Process Models from Event Logs. IEEE Transactions on Knowledge and Data Engineering, 16 (9), 1128–1142.
- ^ Agrawal, R., Gunopulos, D., & Leymann, F. (1998). Mining Process Models from Workflow Logs. In Sixth international conference on extending database technology (pp. 469–483).
- ^ Cook, J., & Wolf, A. (1998). Discovering Models of Software Processes from Event-Based Data. ACM Transactions on Software Engineering and Methodology, 7 (3), 215–249.
- ^ Datta, A. (1998). Automating the Discovery of As-Is Business Process Models: Probabilistic and Algorithmic Approaches. Information Systems Research, 9 (3), 275–301.
- ^ Weijters, A., & Aalst, W. van der (2003). Rediscovering Workflow Models from Event-Based Data using Little Thumb. Integrated Computer-Aided Engineering, 10 (2), 151–162.
- ^ Aalst, W. van der, Beer, H., & Dongen, B. van (2005). Process Mining and Verification of Properties: An Approach based on Temporal Logic. In R. Meersman & Z. T. et al. (Eds.), On the Move to Meaningful Internet Systems 2005: CoopIS, DOA, and ODBASE: OTM Confederated International Conferences, CoopIS, DOA, and ODBASE 2005 (Vol. 3760, pp. 130–147). Springer-Verlag, Berlin.
- ^ Rozinat, A., & Aalst, W. van der (2006a). Conformance Testing: Measuring the Fit and Appropriateness of Event Logs and Process Models. In C. Bussler et al. (Ed.), BPM 2005 Workshops (Workshop on Business Process Intelligence) (Vol. 3812, pp. 163–176). Springer-Verlag, Berlin.
- ^ "Best Process Mining Platforms Reviews 2025 | Gartner Peer Insights". www.gartner.com. Retrieved 2025-04-29.
Further reading
[edit]- Aalst, W. van der (2016). Process Mining: Data Science in Action. Springer Verlag, Berlin (ISBN 978-3-662-49850-7).
- Reinkemeyer, L. (2020). Process Mining in Action: Principles, Use Cases and Outlook. Springer Verlag, Berlin (ISBN 978-3-030-40171-9).
- Carmona, J., van Dongen, B.F., Solti, A., Weidlich, M. (2018). Conformance Checking: Relating Processes and Models. Springer Verlag, Berlin (ISBN 978-3-319-99413-0).
- Aalst, W. van der (2011). Process Mining: Discovery, Conformance and Enhancement of Business Processes. Springer Verlag, Berlin (ISBN 978-3-642-19344-6).
- Aalst, W. van der, Dongen, B. van, Herbst, J., Maruster, L., Schimm, G., & Weijters, A. (2003). Workflow Mining: A Survey of Issues and Approaches. Data and Knowledge Engineering, 47 (2), 237–267.
- Aalst, W. van der, Reijers, H., & Song, M. (2005). Discovering Social Networks from Event Logs. Computer Supported Cooperative work, 14 (6), 549–593.
- Jans, M., van der Werf, J.M., Lybaert, N., Vanhoof, K. (2011) A business process mining application for internal transaction fraud mitigation, Expert Systems with Applications, 38 (10), 13351–13359
- Dongen, B. van, Medeiros, A., Verbeek, H., Weijters, A., & Aalst, W. van der (2005). The ProM framework: A New Era in Process Mining Tool Support. In G. Ciardo & P. Darondeau (Eds.), Application and Theory of Petri Nets 2005 (Vol. 3536, pp. 444–454). Springer-Verlag, Berlin.
- Aalst, W. van der. A Practitioner's Guide to Process Mining: Limitations of the Directly-Follows Graph. In International Conference on Enterprise Information Systems (Centeris 2019), volume 164 of Procedia Computer Science, pages 321-328. Elsevier, 2019.
- Grigori, D., Casati, F., Castellanos, M., Dayal, U., Sayal, M., & Shan, M. (2004). Business Process Intelligence. Computers in Industry, 53 (3), 321–343.
- Grigori, D., Casati, F., Dayal, U., & Shan, M. (2001). Improving Business Process Quality through Exception Understanding, Prediction, and Prevention. In P. Apers, P. Atzeni, S. Ceri, S. Paraboschi, K. Ramamohanarao, & R. Snodgrass (Eds.), Proceedings of 27th international conference on Very Large Data Bases (VLDB’01) (pp. 159–168). Morgan Kaufmann.
- IDS Scheer. (2002). ARIS Process Performance Manager (ARIS PPM): Measure, Analyze and Optimize Your Business Process Performance (whitepaper).
- Ingvaldsen, J.E., & J.A. Gulla. (2006). Model Based Business Process Mining. Journal of Information Systems Management, Vol. 23, No. 1, Special Issue on Business Intelligence, Auerbach Publications
- Kirchmer, M., Laengle, S., & Masias, V. (2013). Transparency-Driven Business Process Management in Healthcare Settings [Leading Edge]. Technology and Society Magazine, IEEE, 32(4), 14-16.
- zur Muehlen, M. (2004). Workflow-based Process Controlling: Foundation, Design and Application of workflow-driven Process Information Systems. Logos, Berlin.
- zur Muehlen, M., & Rosemann, M. (2000). Workflow-based Process Monitoring and Controlling – Technical and Organizational Issues. In R. Sprague (Ed.), Proceedings of the 33rd Hawaii international conference on system science (HICSS-33) (pp. 1–10). IEEE Computer Society Press, Los Alamitos, California.
- Rozinat, A., & Aalst, W. van der (2006b). Decision Mining in ProM. In S. Dustdar, J. Faideiro, & A. Sheth (Eds.), International Conference on Business Process Management (BPM 2006) (Vol. 4102, pp. 420–425). Springer-Verlag, Berlin.
- Sayal, M., Casati, F., Dayal, U., & Shan, M. (2002). Business Process Cockpit. In Proceedings of 28th international conference on very large data bases (VLDB’02) (pp. 880–883). Morgan Kaufmann.
- Huser V, Starren JB, EHR Data Pre-processing Facilitating Process Mining: an Application to Chronic Kidney Disease. AMIA Annu Symp Proc 2009 link
- Ross-Talbot S, The importance and potential of descriptions to our industry. Keynote at The 10th International Federated Conference on Distributed Computing Techniques [1]
- Garcia, Cleiton dos Santos; Meincheim, Alex; et al. (2019). Process mining techniques and applications – A systematic mapping study». Expert Systems with Applications. 133: 260–295. ISSN 0957-4174. doi:10.1016/j.eswa.2019.05.003 [2]
- van der Aalst, W.M.P. and Berti A. Discovering Object-Centric Petri Nets. Fundamenta Informaticae, 175(1-4):1-40, 2020. doi:10.3233/FI-2020-1946 [3]
External links
[edit]- International Process Mining Conference is the annual international process mining conference organized by the IEEE Task Force on Process Mining.
- Process mining research at Eindhoven University of Technology, the Netherlands.
- Process mining research at Ghent University, Belgium.
- Process mining research at University of Padua, Italy.