")
Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
Crash (computing)
View on Wikipedia
This article needs additional citations for verification. (December 2013) |

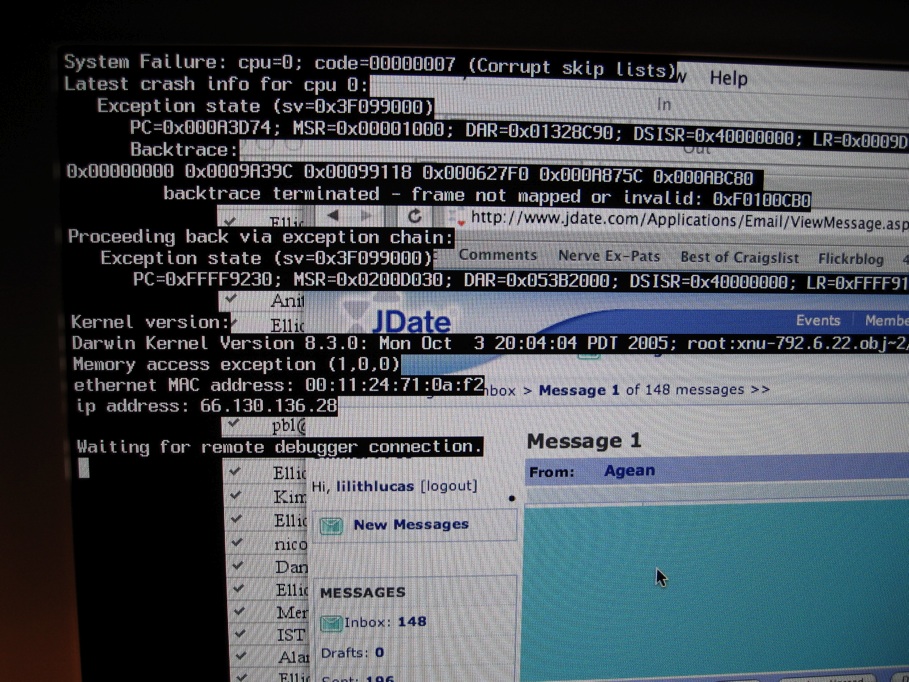
In computing, a crash, or system crash, occurs when a computer program such as a software application or an operating system stops functioning properly and exits. On some operating systems or individual applications, a crash reporting service will report the crash and any details relating to it (or give the user the option to do so), usually to the developer(s) of the application. If the program is a critical part of the operating system, the entire system may crash or hang, often resulting in a kernel panic or fatal system error.
Most crashes are the result of a software bug. Typical causes include accessing invalid memory addresses,[a] incorrect address values in the program counter, buffer overflow, overwriting a portion of the affected program code due to an earlier bug, executing invalid machine instructions (an illegal or unauthorized opcode), or triggering an unhandled exception. The original software bug that started this chain of events is typically considered to be the cause of the crash, which is discovered through the process of debugging. The original bug can be far removed from the code that actually triggered the crash.
In early personal computers, attempting to write data to hardware addresses outside the system's main memory could cause hardware damage. Some crashes are exploitable and let a malicious program or hacker execute arbitrary code, allowing the replication of viruses or the acquisition of data which would normally be inaccessible.
Application crashes
[edit]
An application typically crashes when it performs an operation that is not allowed by the operating system. The operating system then triggers an exception or signal in the application. Unix applications traditionally responded to the signal by dumping core. Most Windows and Unix GUI applications respond by displaying a dialogue box (such as the one shown in the accompanying image on the right) with the option to attach a debugger if one is installed. Some applications attempt to recover from the error and continue running instead of exiting.
An application can also contain code to crash[b] after detecting a severe error.
Typical errors that result in application crashes include:
- attempting to read or write memory that is not allocated for reading or writing by that application (e.g., segmentation fault, x86-specific general protection fault)
- attempting to execute privileged or invalid instructions
- attempting to perform I/O operations on hardware devices to which it does not have permission to access
- passing invalid arguments to system calls
- attempting to access other system resources to which the application does not have permission to access
- attempting to execute machine instructions with bad arguments (depending on CPU architecture): divide by zero, operations on denormal number or NaN (not a number) values, memory access to unaligned addresses, etc.
Crash to desktop
[edit]A "crash to desktop" (CTD) is said to occur when a program (commonly a video game) unexpectedly quits, abruptly taking the user back to the desktop. Usually, the term is applied only to crashes where no error is displayed, hence all the user sees as a result of the crash is the desktop. Many times there is no apparent action that causes a crash to desktop. During normal function, the program may freeze for a shorter period of time, and then close by itself. Also during normal function, the program may become a black screen and repeatedly play the last few seconds of sound (depending on the size of the audio buffer) that was being played before it crashes to desktop. Other times it may appear to be triggered by a certain action, such as loading an area.
CTD bugs are considered particularly problematic for users. Since they frequently display no error message, it can be very difficult to track down the source of the problem, especially if the times they occur and the actions taking place right before the crash do not appear to have any pattern or common ground. One way to track down the source of the problem for games is to run them in windowed-mode. Certain operating system versions may feature one or more tools to help track down causes of CTD problems.
Some computer programs such as StepMania and BBC's Bamzooki also crash to desktop if in full-screen, but display the error in a separate window when the user has returned to the desktop.
Web server crashes
[edit]The software running the web server behind a website may crash, rendering it inaccessible entirely or providing only an error message instead of normal content.
For example, if a site is using an SQL database (such as MySQL) for a script (such as PHP) and that SQL database server crashes, then PHP will display a connection error.
Operating system crashes
[edit]

An operating system crash commonly occurs when a hardware exception occurs that cannot be handled. Operating system crashes can also occur when internal sanity-checking logic within the operating system detects that the operating system has lost its internal self-consistency.
Modern multi-tasking operating systems, such as Linux, and macOS, usually remain unharmed when an application program crashes.
Some operating systems, e.g., z/OS, have facilities for Reliability, availability and serviceability (RAS) and the OS can recover from the crash of a critical component, whether due to hardware failure, e.g., uncorrectable ECC error, or to software failure, e.g., a reference to an unassigned page.
Abnormal end
[edit]An Abnormal end or ABEND is an abnormal termination of software, or a program crash. Errors or crashes on the Novell NetWare network operating system are usually called ABENDs. Communities of NetWare administrators sprang up around the Internet, such as abend.org.
This usage derives from the ABEND macro on IBM OS/360, ..., z/OS operating systems. Usually capitalized, but may appear as "abend". Some common ABEND codes are System ABEND 0C7 (data exception) and System ABEND 0CB (division by zero).[1][2][3] Abends can be "soft" (allowing automatic recovery) or "hard" (terminating the activity).[4] The term is jocularly claimed to be derived from the German word "Abend" meaning "evening".[5]
Security and privacy implications of crashes
[edit]Depending on the application, the crash may contain the user's sensitive and private information.[6] Moreover, many software bugs which cause crashes are also exploitable for arbitrary code execution and other types of privilege escalation.[7][8] For example, a stack buffer overflow can overwrite the return address of a subroutine with an invalid value, which will cause, e.g., a segmentation fault, when the subroutine returns. However, if an exploit overwrites the return address with a valid value, the code in that address will be executed.
Crash reproduction
[edit]When crashes are collected in the field using a crash reporter, the next step for developers is to be able to reproduce them locally. For this, several techniques exist: STAR uses symbolic execution,[9] EvoCrash performs evolutionary search.[10]
See also
[edit]Notes
[edit]- ^ Types of invalid addresses include:
- Invalid real address
- Invalid segment number
- Invalid page number
- Address not on correct boundary (alignment error)
- ^ In OS/360 and successors the application normally uses an ABEND macro with a user completion code.
References
[edit]- ^ "ABEND" (PDF). OS Release 21 – System/360 Operating System – Supervisor Services and Macro Instructions (PDF) (Eighth ed.). IBM. September 1974. pp. 97–99. GC28-6646-7. Retrieved 8 July 2023.
- ^ "0Cx – z/OS MVS System Codes". IBM.
- ^ List of ABEND codes Archived 2018-09-16 at the Wayback Machine on madisoncollege.edu
- ^ Parziale, Lydia (2008). z/VM and Linux Operations for z/OS System Programmers. IBM Redbooks. ISBN 9780738431598. page 352
- ^ "Abend" Archived 29 September 2011 at the Wayback Machine on dictionary.die.net
- ^ Satvat, Kiavash; Saxena, Nitesh (2018). "Crashing Privacy: An Autopsy of a Web Browser's Leaked Crash Reports". arXiv:1808.01718 [cs.CR].
- ^ "Analyze Crashes to Find Security Vulnerabilities in Your Apps". Msdn.microsoft.com. 26 April 2007. Archived from the original on 11 December 2011. Retrieved 26 June 2014.
- ^ "Jesse Ruderman » Memory safety bugs in C++ code". Squarefree.com. 1 November 2006. Archived from the original on 11 December 2013. Retrieved 26 June 2014.
- ^ Chen, Ning; Kim, Sunghun (2015). "STAR: Stack Trace Based Automatic Crash Reproduction via Symbolic Execution". IEEE Transactions on Software Engineering. 41 (2): 198–220. Bibcode:2015ITSEn..41..198C. doi:10.1109/TSE.2014.2363469. ISSN 0098-5589. S2CID 6299263.
- ^ Soltani, Mozhan; Panichella, Annibale; van Deursen, Arie (2017). "A Guided Genetic Algorithm for Automated Crash Reproduction". 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE). pp. 209–220. doi:10.1109/ICSE.2017.27. ISBN 978-1-5386-3868-2. S2CID 199514177. Archived from the original on 25 January 2022. Retrieved 21 December 2020.