

Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
JIS X 0201
View on Wikipedia JIS X 0201 8-bit code page | |
| MIME / IANA | 8-bit: JIS_X02017-bit Roman: JIS_C6220-1969-ro7-bit Kana: JIS_C6220-1969-jp |
|---|---|
| Alias(es) | JIS C 6220 8-bit: csHalfWidthKatakana Roman: ISO646-JP, iso-ir-14 Kana: iso-ir-13, x0201-7 |
| Languages | Japanese (basic support), English |
| Standard | JIS X 0201:1969 |
| Classification | ISO 646, Extended ISO 646 |
| Preceded by | Wabun code, JIS C 0803 |
| Succeeded by | Shift JIS |
| Other related encoding | N-byte Hangul code |
JIS X 0201, a Japanese Industrial Standard developed in 1969, was the first Japanese electronic character set to become widely used. The character set was initially known as JIS C 6220 before the JIS category reform. Its two forms were a 7-bit encoding or an 8-bit encoding, although the 8-bit form was dominant until Unicode (specifically UTF-8) replaced it. The full name of this standard is 7-bit and 8-bit coded character sets for information interchange (7ビット及び8ビットの情報交換用符号化文字集合).
The first 96 codes comprise an ISO 646 variant, mostly following ASCII with some differences, while the second 96 character codes represent the phonetic Japanese katakana signs. Since the encoding does not provide any way to express hiragana or kanji, it is only capable of expressing simplified written Japanese. Nevertheless, this simplification can represent the full range of sounds in the language. In the 1970s, this was acceptable for media such as text mode computer terminals, telegrams, receipts, or other electronically handled data.
JIS X 0201 was supplanted by subsequent encodings such as Shift JIS, which combines this standard and JIS X 0208, and later by Unicode.
History
[edit]The Comite Consultatif International Telephonique et Telegraphique (CCITT) introduced the International Telegraph Alphabet No.2 (ITA2) code as an international standard, which was the 5-bit Latin encoding. Most countries have their own national standards based on this. In Japan, the Agency of Industrial Science and Technology (AIST) standardized it as the 6-bit character codes of JIS C 0803-1961 (Keyboard layout and codes for teleprinters), which combined with katakana characters. However, it didn't match the industry requirements because the character map was small, and the code layout was impractical. The AIST considered a practical character encoding to replace various codes used in Japan.[1]
In 1963, ISO introduced a draft of ISO R 646 (6 and 7-bit coded character sets for information processing interchange). AIST committed the conjunction of ISO R 646 and katakana mapping to the Information Processing Society of Japan (IPSJ). IPSJ formed the code standardization committee. The committee didn't adopt the 6-bit form of ISO's draft because the katakana set couldn't fit into its character map. The early JIS draft mapped small katakana characters next to each of their normal katakana characters. It was considered to be convenient for sorting by Gojūon order (JIS X 0208:1978 chose this ordering). Some committee members criticized it would complicate the mechanic of keyboards which only handled normal katakana characters. The later draft mapped small katakana characters to positions 0xA7-0xAF.
The 1964 ISO draft reserved the positions 0x24 and 0x5c for first and second currency symbols to be assigned by each country, but it was considered too dangerous in international communications to use currency symbols that could be localized. The ISO committee had two options that to use a generic currency symbol (¤) or to give the dollar ($) and pound (£) signs permanent assignments. It was agreed that the dollar sign was assigned to position 0x24 and the pound sign was to position 0x23. The latter was not required in countries that did not need the pound sign.[2] The JIS committee decided to put the yen sign (¥) in 0x5c (one of national use positions).
JIS C 6220 (Codes for information interchange, 情報交換用符号) was published in 1969. Its number was changed to JIS X 0201 due to the JIS category reform in 1987, and the name was changed to 7-bit and 8-bit coded character sets for information interchange (7ビット及び8ビットの情報交換用符号化文字集合) in the 1990 edition.
The character set of JIS X 0201 had been widely used in Japan. The Nationwide Banking Data Communication System (全国銀行データ通信システム), the largest funds transfer system in Japan, was established in 1973. Transaction messages between banks used a subset of JIS X 0201. The system was used until 2018, and it was replaced by the ZEDI (The Nationwide Banking Electronic Data Interchange System, 全銀EDIシステム) which could handle hiragana and kanji characters.[3] In 1978, the JIS C 6226 (JIS X 0208) 2-byte character set was developed to express hiragana and kanji characters. It includes katakana characters, but their codes and layout are different from JIS X 0201. Computer manufacturers developed their own extensions of JIS X 0208 to retain compatibility with JIS X 0201. In 1982, the Microsoft Kanji encoding scheme (Codepage 932 of MS-DOS) and Digital Research's SJC26 (for Japanese CP/M-86) were developed to combine JIS X 0201 single-byte encoding and JIS X 0208 double byte encoding without shift out and shift in characters.[4] They were called Shift JIS, which became the industrial standard for personal computers.
Implementation details
[edit]

The first half (Roman set) of JIS X 0201 constitutes a Japanese variant of ISO 646, amounting to ASCII with backslash (\) and tilde (~) replaced by yen (¥) and overline (‾),[5] while the second half (Kana set) consists mainly of katakana. Control characters are specified in JIS X 0211.
In the 7-bit format, the shift out control character 0x0E switches to the Kana set and shift in (0x0F) switches to the Roman set.[6][7] In the 8-bit format, given in the chart below, bytes with the most significant bit set (i.e. 0x80–0xFF) are used for the Kana set and bytes with it unset (i.e. 0x00–0x7F) are used otherwise.
Names used specifically for the 7-bit Roman set include "JISCII",[8] "JIS Roman",[9] "ISO646-JP",[10][11] "JIS C6220-1969-ro",[11][10] "Japanese-Roman",[12] "Japan 7-Bit Latin",[13] and "ISO-IR-14",[10][11][7] whereas names used specifically for the 7-bit Kana set include "ISO-IR-13",[6][10][11] "JIS C6220-1969-jp"[10][11] and "x0201-7".[10][11]
The substitution of the yen symbol for backslash can make paths on DOS and Windows-based computers with Japanese support display strangely, like "C:¥Program Files¥", for example.[14] Another similar problem is C programming language's control characters of string literals, like printf("Hello, world.¥n");.
Codepage layout
[edit]The following table is the original 8-bit coded character set of JIS X 0201 (with the kana set indicated by bytes with the high bit set).[15][16]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x | C0 codes[a] | |||||||||||||||
| 1x | ||||||||||||||||
| 2x | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ¥ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ‾ | DEL |
| 8x | C1 codes or Empty Block[a] | |||||||||||||||
| 9x | ||||||||||||||||
| Ax | 。 | 「 | 」 | 、 | ・ | ヲ | ァ | ィ | ゥ | ェ | ォ | ャ | ュ | ョ | ッ | |
| Bx | ー | ア | イ | ウ | エ | オ | カ | キ | ク | ケ | コ | サ | シ | ス | セ | ソ |
| Cx | タ | チ | ツ | テ | ト | ナ | ニ | ヌ | ネ | ノ | ハ | ヒ | フ | ヘ | ホ | マ |
| Dx | ミ | ム | メ | モ | ヤ | ユ | ヨ | ラ | リ | ル | レ | ロ | ワ | ン | ゙ | ゚ |
| Ex | ||||||||||||||||
| Fx | ||||||||||||||||
As part of Shift JIS
[edit]Following is the mapping used for JIS X 0201 as part of Shift JIS,[17][18] i.e. showing the 8-bit form of JIS X 0201, and mapping the Katakana characters to the Halfwidth and Fullwidth Forms block (which in turn derives its half width kana layout from JIS X 0201).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x | ||||||||||||||||
| 1x | ||||||||||||||||
| 2x | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ¥ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ‾ | |
| 8x | ||||||||||||||||
| 9x | ||||||||||||||||
| Ax | 。 | 「 | 」 | 、 | ・ | ヲ | ァ | ィ | ゥ | ェ | ォ | ャ | ュ | ョ | ッ | |
| Bx | ー | ア | イ | ウ | エ | オ | カ | キ | ク | ケ | コ | サ | シ | ス | セ | ソ |
| Cx | タ | チ | ツ | テ | ト | ナ | ニ | ヌ | ネ | ノ | ハ | ヒ | フ | ヘ | ホ | マ |
| Dx | ミ | ム | メ | モ | ヤ | ユ | ヨ | ラ | リ | ル | レ | ロ | ワ | ン | ゙ | ゚ |
| Ex | ||||||||||||||||
| Fx |
Alternative mapping of katakana
[edit]The basic ISO-2022-JP profile does not permit the Kana set of JIS X 0201, only the Roman set and JIS X 0208 (although ISO 2022 / JIS X 0202 itself permits it). Accordingly, when converting JIS X 0201 katakana (or Unicode half-width kana, which use the same layout) to ISO-2022-JP, the following mapping or transformation is often used.[20] This allows the kana to be converted to JIS X 0208.
In theory, this mapping is equally correct, as JIS X 0201 itself does not specify display width, although in practice (and especially in duospaced environments) JIS X 0201 is used for half-width katakana.
For ease of comparison with the chart above, the mapping is shown below over the JIS X 0201 katakana encoding and with the high bit set.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ax | 。 | 「 | 」 | 、 | ・ | ヲ | ァ | ィ | ゥ | ェ | ォ | ャ | ュ | ョ | ッ | |
| Bx | ー | ア | イ | ウ | エ | オ | カ | キ | ク | ケ | コ | サ | シ | ス | セ | ソ |
| Cx | タ | チ | ツ | テ | ト | ナ | ニ | ヌ | ネ | ノ | ハ | ヒ | フ | ヘ | ホ | マ |
| Dx | ミ | ム | メ | モ | ヤ | ユ | ヨ | ラ | リ | ル | レ | ロ | ワ | ン | ゛[b] | ゜[c] |
Variants and extensions
[edit]Shift JIS
[edit]IBM's implementations
[edit]Code page 897 is IBM's implementation of the 8-bit form of JIS X 0201. It includes several additional graphical characters in the C0 control characters area, and the code points in question may be used as control characters or graphical characters depending on the context,[23] similarly in concept to OEM-US, but with different graphical characters. The C0 rows are shown below. IBM also designate pure 8-bit JIS X 0201 without these control code replacements as Code page 1139.[24] Another variant, including a smaller subset of these C0 replacement graphics (including only the box drawing characters in 0x01–06, 0x10, 0x15–17 and 0x19 and the line/arrow characters in 0x1B–1F), but using a different style of up-arrow (U+21E7 ⇧ UPWARDS WHITE ARROW) at 0x1C, is designated Code page 1086.[25]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x | NUL | ╔ | ╗ | ╚ | ╝ | ║ | ═ | ↓ | BS | ○ | LF | 〿 | FF | CR | ■ | ☼ |
| 1x | ╬ | DC1 | ↕ | DC3 | ▓ | ╩ | ╦ | ╣ | CAN | ╠ | ░ | ↵ | ↑ | │ | → | ← |
IBM also implements the 7-bit Roman set of JIS X 0201 as Code page 895[31] and the 7-bit Kana set as Code page 896 for use as ISO 2022 or EUC-JP code-sets. Code page 896, in addition to standard JIS X 0201 assignments, defines five additional assignments, shown below.[32] Although use of these extended characters is not permitted by the associated CCSID 896,[33] they are permitted by the alternative CCSID 4992.[34]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6x | ¢ | £ | ¬ | \ | ~ |
IBM's Code page 1041 is an extended version of Code page 897, encoding these five IBM extended[35] characters in alternative locations which are compatible with Shift JIS (respectively 0x80, 0xA0, 0xFD, 0xFE and 0xFF).[36] Code page 911, another extended 8-bit JIS X 0201 implementation (which uses the same C0 replacement graphics as Code page 1086) encodes the pound (sterling) sign (£) at 0xE1, similarly to Code page 896 with the eight bit set, but differs by encoding the cent sign (¢) at 0xE2 and the not-sign (¬) at 0xE3.[37]
IBM's Code page 903 is encoded for use as the single byte component of certain simplified Chinese character encodings,[38] accompanying the ASCII-based Code page 904 used with traditional Chinese encodings.[39][40] Despite this, Code page 903 follows ISO 646-JP / the Roman half of JIS X 0201, in that it replaces the ASCII backslash 0x5C (rather than the ASCII dollar sign 0x24 as in GB 1988 / ISO 646-CN) with the yen/yuan sign. It also uses the same C0 replacement graphics as code page 897.[41] Code page 1042 extends code page 903 with the pound (sterling) sign at 0x80, and the not-sign, backslash and tilde at their Code page 1041 locations.[42]
Others
[edit]-
 NEC PC-8001 (1979) character set as rendered in the 8×8 pixel font
NEC PC-8001 (1979) character set as rendered in the 8×8 pixel font -

-



Footnotes
[edit]- ^ a b Control characters are specified in JIS X 0211.
- ^ Gets mapped to correspond to the JIS X 0208 character (mapped to U+309B), not compatibility normalization (which would be U+3099, the combining version).[22]
- ^ Gets mapped to correspond to the JIS X 0208 character (mapped to U+309C), not compatibility normalization (which would be U+309A, the combining version).[22]
References
[edit]- ^ 行政管理庁 (The Agency of Administrative Management) (1968). 行政における電子計算機の共同利用に関する調査研究報告書 (in Japanese). 行政事務機械化研究協会. pp. 108–113. OCLC 703804474.
- ^ Fischer, Eric N. (2000-06-20). "The Evolution of Character Codes, 1874–1968". ark:/13960/t07x23w8s. Retrieved 2023-11-02.
- ^ "経理部門の人材不足で悩む会社に朗報、金融EDI「ZEDI」が2018年稼働へ". Nikkei X-TECH. 2017-11-30. Retrieved 2019-07-24.
- ^ a b 西田, 憲正 (1983-12-19). "Unix風の機能を持ち込んだ日本語MS-DOS 2.0の機能と内部構造". 日経エレクトロニクス (in Japanese). Nikkei McGraw-Hill: 165–190. ISSN 0385-1680.
- ^ "3.1.1 Details of Problems". Problems and Solutions for Unicode and User/Vendor Defined Characters. The Open Group Japan. Archived from the original on 1999-02-03. Retrieved 2019-04-15.
- ^ a b Japanese Industrial Standards Committee. ISO-IR-13: The Japanese KATAKANA graphic set of characters (PDF). ITSCJ/IPSJ.
- ^ a b Japanese Industrial Standards Committee. ISO-IR-14: The Japanese Roman graphic set of characters (PDF). ITSCJ/IPSJ.
- ^ "IBM-943 and IBM-932", IBM Knowledge Center, IBM
- ^ "kUnicodeForceASCIIRangeMask", Apple Developer Documentation, Apple Inc
- ^ a b c d e f RFC 1345
- ^ a b c d e f "Character Sets". IANA.
- ^ da Cruz, Frank (2010-04-02), "Kermit and MIME Character-Set Names", Kermit Project, Columbia University
- ^ "CP 00895", IBM Globalization — Code page identifiers, IBM, 9 November 2020
- ^ Kaplan, Michael S. (2005-09-17). "When is a backslash not a backslash?".
- ^ JIS X 0201-1997 (in Japanese). Japanese Standards Association. 1997-02-28. p. 17.
- ^ Unicode Consortium (2015-12-02). "JIS X 0201 (1976) to Unicode 1.1 Table". unicode.org. Retrieved 2021-10-01.
- ^ "ibm-943_P130-1999". ICU Demonstration - Converter Explorer. International Components for Unicode.
- ^ Apple, Inc (2005-04-05) [1995-04-15]. "JAPANESE.TXT: Map (external version) from Mac OS Japanese encoding to Unicode 2.1 and later". Unicode Consortium.
- ^ van Kesteren, Anne (2019-02-11). "12.2.2. ISO-2022-JP encoder". Encoding Standard. WHATWG.
- ^ The WHATWG Encoding Standard, for instance, uses it as a transformation when encoding Unicode half-width kana data to ISO-2022-JP.[19]
- ^ van Kesteren, Anne (2018-01-06). "Index ISO-2022-JP Katakana". Encoding Standard. WHATWG.
- ^ a b van Kesteren, Anne (2019-02-11). "5. Indexes". Encoding Standard. WHATWG.
- ^ "Code page identifiers - CP 00897". IBM Globalization. IBM. Archived from the original on 2016-03-17.
- ^ "Code Page 01139" (PDF). IBM. Archived from the original (PDF) on 2015-07-08. Retrieved 2021-10-22.
- ^ "Code Page 01086" (PDF). IBM. Archived from the original (PDF) on 2015-07-08. Retrieved 2021-10-22.
- ^ "CP00897.pdf" (PDF). IBM.
- ^ "CP00897.txt". IBM.
- ^ "Converter Explorer - ibm-943_P130-1999". ICU Demonstration. International Components for Unicode.
- ^ "Coded character set identifiers - CCSID 943". IBM Globalization. IBM. Archived from the original on 2016-03-15.
- ^ Graphics are listed per CP00897.pdf and CP00897.txt provided by IBM.[26][27] Controls are listed, in absence of graphical function or where they differ from ASCII, per the ibm-943_P130-1999 codec provided by IBM to International Components for Unicode[28] (IBM-943 is a Code page 897 superset).[29] SUB is assigned to 0x7F.
- ^ "CP00895.pdf" (PDF). IBM.
- ^ a b "CP00896.pdf" (PDF). IBM.
- ^ "Coded character set identifiers - CCSID 896". IBM Globalization. IBM. Archived from the original on 2016-03-26.
- ^ "Coded character set identifiers - CCSID 4992". IBM Globalization. IBM. Archived from the original on 2016-03-27.
- ^ "11.2 - IBM Extended SBCS Set" (PDF). IBM Japanese Graphic Character Set for Extended UNIX Code (EUC). IBM. p. 315.
- ^ "CP01041.pdf" (PDF). IBM.
- ^ "Code Page 00911" (PDF). IBM. Archived from the original (PDF) on 2015-07-08. Retrieved 2021-10-22.
- ^ "Code page identifiers - CP 903". IBM Globalization. IBM. Archived from the original on 2016-03-17.
- ^ "Coded character set identifiers - CCSID 904". IBM Globalization. IBM. Archived from the original on 2016-03-27.
- ^ "CP00904.pdf" (PDF). IBM.
- ^ "CP00903.pdf" (PDF). IBM.
- ^ "Code Page 01042" (PDF). IBM. Archived (PDF) from the original on 2015-07-08.
External links
[edit]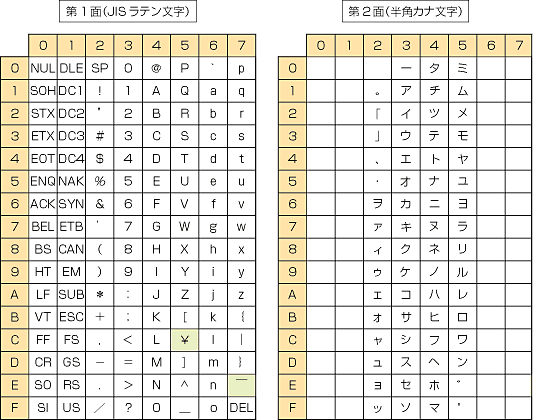{kind=link}
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |
JIS X 0201
View on GrokipediaHistory and Development
Origins as JIS C 6220
In 1969, the Japanese Industrial Standards Committee (JISC) developed JIS C 6220 to meet the growing demand for standardized computer processing of Japanese text within the constraints of limited 7-bit environments prevalent in early computing systems.[5] This standard emerged as a response to the rapid adoption of computers in Japan following the economic expansion of the post-1960s era, where the American Standard Code for Information Interchange (ASCII) proved inadequate for handling katakana characters commonly used in business reports, technical documentation, and telecommunications.[6] Originally designated as JIS C 6220 and first published in 1969, with a revision in 1976,[3] the standard prioritized compatibility with international norms such as ISO 646 while integrating essential Japanese-specific characters to facilitate data interchange across diverse systems.[7] It defined a single-byte encoding scheme consisting of a 7-bit code for Roman and control characters, with an optional 8-bit extension for half-width katakana, enabling rudimentary support for mixed-language text without requiring multi-byte solutions.[3] From its inception, JIS C 6220 introduced key deviations from ASCII to align with Japanese conventions, notably reassigning the byte 0x5C from the backslash () to the yen sign (¥) for currency representation in financial and commercial applications, and mapping 0x7E from the tilde (~) to the overline (¯) to better accommodate typographic needs in technical printing.[6] These modifications ensured seamless integration with global standards while addressing local requirements, laying the groundwork for subsequent enhancements in Japanese character encoding.[3]Key Revisions and Standardization
In 1987, as part of a broader reorganization of the Japanese Industrial Standards (JIS) categories to establish Division X for information processing, the standard was renumbered from JIS C 6220 to JIS X 0201, retaining its core content without substantive changes. The standard was reaffirmed in 1984 without substantive changes.[3] The standard was reaffirmed in 1989 without changes to the character set.[3] The 1997 revision marked the final major update, aligning the standard more closely with the rising adoption of Unicode by providing precise definitions for escape sequences used in mode switching between 7-bit and 8-bit forms, ensuring smoother integration with multi-script environments while maintaining backward compatibility.[8] Following the 1997 revision, JIS X 0201 saw no further updates, entering a phase of deprecation in favor of Unicode-based encodings by the early 2000s, though it remained in use for legacy systems and specific applications requiring single-byte efficiency.[9]Encoding Forms and Structure
7-Bit Roman and Katakana Encoding
JIS X 0201 specifies a 7-bit encoding scheme compliant with ISO/IEC 2022, which employs the GL (G0) and GR (G1) areas to accommodate two distinct 94-character sets within a total of 128 code points per byte.[1] This structure allows for the representation of either Roman or half-width katakana characters using single 7-bit bytes, with control characters occupying positions 0x00–0x1F and 0x7F, while graphic characters fill 0x21–0x7E. The encoding relies on escape sequences to designate and switch between the character sets, enabling stateful mode transitions in data streams. To enter Roman mode, the sequence ESC ( J (hexadecimal 0x1B 0x28 0x4A) designates the JIS Roman set (ISO-IR 14) to the G0 area for use in the GL positions; similarly, ESC ( I (0x1B 0x28 0x49) designates the half-width katakana set (ISO-IR 13) to G0.[10][11] For simultaneous access to both sets, one can designate Roman to G0 and katakana to G1 using ESC ) I, then invoke GR via shift-out (SO, 0x0E) or locking-shift one (LS1, ESC n), though simple mode switching via repeated designations to G0 is common in practice.[12][3] In Roman mode, the 94 graphic characters include decimal digits, uppercase and lowercase Latin letters, and common symbols, forming a Japanese-adjusted variant of ISO 646 (specifically ISO 646-JP).[13] The katakana mode provides 94 half-width katakana characters, each occupying a single byte for compact phonetic representation in Japanese text.[1] This 7-bit form lacks support for kanji or hiragana, limiting it to basic Latin and katakana needs, and was primarily designed for resource-constrained environments such as early teletype terminals and minicomputers in the late 1960s and 1970s.[3] It serves as a foundational subset compatible with ISO 646-JP, incorporating adjustments like reassigning the backslash to yen symbol (¥) and overline to tilde (¯).[10]8-Bit Extension for Full Coverage
The 8-bit extension of JIS X 0201 was introduced in 1976 as a superset of the original 7-bit standard, providing a fixed single-byte encoding that integrates both Roman and katakana characters without requiring dynamic mode switching via escape sequences. In this structure, Roman characters occupy the byte range 0x00 to 0x7F, preserving compatibility with international reference versions of ASCII, while half-width katakana characters are assigned to the range 0xA1 to 0xDF; the intervening range 0x80 to 0x9F remains undefined or reserved for control functions.[14][3][15] This extension's design aimed to enable seamless 8-bit processing in computing environments such as MS-DOS, where the absence of escape sequences streamlined text handling and reduced overhead for Japanese input and output operations. By fixing the character positions in a single 256-byte table, it supported more efficient software and hardware implementations compared to the 7-bit variant's state-dependent approach, particularly in resource-constrained systems.[16][17] The encoding accommodates 157 printable characters in total—94 from the Roman set and 63 half-width katakana—alongside standard control characters to manage formatting and transmission. Katakana characters are derived from the 7-bit katakana codes by setting the high bit (i.e., byte = 0x80 + 7-bit code for positions 0x21 to 0x5F corresponding to the 63 characters), guaranteeing separation from the lower ASCII-compatible bytes.[3][15] During the 1980s, this 8-bit form gained widespread adoption in early Japanese computing applications, including word processors and video display terminals, where it facilitated practical phonetic text representation in environments transitioning from 7-bit to 8-bit architectures.[17][3]Character Set Composition
ASCII-Compatible Control and Graphic Characters
The ASCII-compatible portion of JIS X 0201, also known as the Roman set, occupies the 7-bit code range from 0x00 to 0x7F and forms the foundation for handling Latin-based text and symbols in Japanese computing environments.[18] This set aligns closely with the international standard ISO/IEC 646, ensuring broad compatibility with Western systems while incorporating minor adaptations for Japanese conventions.[4] It enables seamless integration of English alphanumeric content into documents that may also include Japanese elements, serving as a universal base layer in encodings like ISO-2022-JP.[18] Control characters in JIS X 0201 span positions 0x00 through 0x1F and 0x7F, mirroring the C0 controls and delete character defined in ISO/IEC 646 (equivalent to US-ASCII in this regard).[4] These include standard functions such as NUL (0x00) for null termination, BEL (0x07) for audible alerts, CR (0x0D) and LF (0x0A) for carriage return and line feed, and DEL (0x7F) for deletion, with no Japan-specific modifications.[18] Their unchanged adoption from ISO/IEC 646 facilitates consistent control signaling in mixed-language data streams, supporting operations like text formatting and device communication without requiring additional translation.[4] The graphic characters occupy the 94 positions from 0x20 (space) to 0x7E, encompassing uppercase and lowercase letters (A-Z, a-z), digits (0-9), and common punctuation and symbols, totaling 95 printable characters when including space.[18] Most mappings remain identical to US-ASCII; for instance, left bracket [ at 0x5B, right bracket ] at 0x5D, left brace { at 0x7B, and right brace } at 0x7D are unchanged, preserving compatibility for programming and markup.[3] However, two positions deviate to accommodate Japanese typography: 0x5C maps to the yen sign ¥ instead of backslash , and 0x7E maps to the overline ¯ (macron) instead of tilde ~.[18] These substitutions reflect practical needs in Japanese contexts, where the yen symbol is essential for financial notation and the overline serves as a diacritic for long vowels in romanized text, while backslash and tilde have less frequent standalone use.[3] Overall, the limited differences—only these two graphic character variants—minimize interoperability issues with ASCII-based systems, allowing JIS X 0201 to function as a drop-in replacement for basic Latin script in bilingual applications.[4]Half-Width Katakana Characters
The half-width katakana characters defined in JIS X 0201 form a dedicated subset for representing the Japanese katakana syllabary in a compact manner, comprising 94 graphic characters that encompass the basic modern katakana sounds, including voiced (dakuten) and semi-voiced (handakuten) forms, as well as essential combinations such as small tsu (ッ), small ya (ャ), small yu (ュ), and small yo (ョ). These characters are drawn from the ISO-IR-13 registry, which specifies the katakana set aligned with JIS requirements for phonetic notation in information interchange. In the 7-bit encoding form of JIS X 0201, these 94 characters occupy positions 0x21 through 0x7E in the graphic character area (GR), activated via the escape sequence ESC ) I (0x1B 0x29 0x49) to designate the katakana set to G1 (GR) per ISO 2022 protocols, with the Roman set designated to G0 (GL) via ESC ( J (0x1B 0x28 0x4A), allowing seamless switching between the Roman (GL) and katakana (GR) areas within a 7-bit stream. This arrangement supports full coverage of the syllabary, with precomposed glyphs for voiced and semi-voiced variants positioned systematically in the 94-cell layout—for instance, the basic ア at 0x44, ガ (voiced ka) at 0x54, and パ (semi-voiced ha) at 0x64. The 8-bit encoding extension of JIS X 0201 relocates a core subset of these characters to the fixed range 0xA1 through 0xDF, totaling 63 positions that prioritize frequently used elements: six punctuation and symbols (e.g., 。 at 0xA1, ・ at 0xA5, ー at 0xB0), 46 basic unvoiced katakana (e.g., ア at 0xB1, イ at 0xB2, ン at 0xDD), nine small katakana variants (e.g., ァ at 0xA7, ィ at 0xA8, ッ at 0xAF), and two diacritic marks (voiced sound mark ゙ at 0xDE, semi-voiced sound mark ゚ at 0xDF). Unlike the 7-bit form, voiced and semi-voiced katakana here require post-composition with the marks, rather than dedicated precomposed codes.[19] This half-width design was intentionally narrower in glyph aspect ratio (approximately 1:2) to optimize space in fixed-width monospaced fonts, facilitating efficient text display and transmission on resource-constrained 1980s-era terminals, teleprinters, and early digital systems where bandwidth and screen real estate were limited.[3] Key limitations include the lack of precomposed dakuten and handakuten across the entire set in the 8-bit form, reliance on combining marks that can complicate rendering in non-supporting environments, and deliberate exclusion of rare, obsolete, or extended katakana (e.g., historical variants like ヰ or ヱ in non-standard positions) to maintain focus on everyday modern usage.Codepage Layout and Mappings
Standard Byte Layout
The 8-bit encoding of JIS X 0201 defines a complete 256-byte codepage that integrates the 7-bit Roman (ISO-IR 14) and Katakana (ISO-IR 13) sets, enabling direct single-byte representation of Latin characters, controls, and half-width katakana without requiring escape sequences.[3] Bytes 0x00–0x7F encompass control codes (0x00–0x1F and 0x7F) and 94 graphic characters in the Roman set (0x20–0x7E), providing ASCII compatibility with modifications for Japanese usage.[13] The upper range includes 63 half-width katakana and punctuation characters from 0xA1–0xDF, while bytes 0x80–0xA0 and 0xE0–0xFF remain undefined or reserved for controls, ensuring no overlap with the defined sets.[3] This layout supports a one-to-one byte-to-character mapping, where each valid byte directly encodes its assigned glyph in single-byte streams, distinguishing it from multi-byte standards like JIS X 0208.[19] In the Roman portion, the encoding mirrors ISO 646 except for key substitutions: 0x5C encodes the yen sign (¥) instead of backslash (), and 0x7E encodes the overline (‾ U+203E) instead of tilde (~), which is sometimes rendered as a macron (¯ U+00AF) in certain legacy systems or fonts, reflecting adaptations for Japanese typography and currency notation.[13] Representative mappings include 0x21 to exclamation mark (!), 0x2F to solidus (/), and 0x7B to left curly brace ({).[19] The half-width katakana occupy 0xA1–0xDF, rendering compact forms suitable for early computer displays and terminals, with separate codes for base letters, voiced (dakuten) and semi-voiced (handakuten) marks applied as combining elements in some implementations.[3] Examples of mappings are 0xA1 to half-width ideographic full stop (。), 0xB1 to half-width katakana letter a (ア), 0xC0 to half-width katakana letter ta (タ), and 0xDF to half-width katakana semi-voiced sound mark (゚).[19] The JIS X 0201:1997 standard illustrates this arrangement in a tabular diagram with 16 rows (high nibble 0–F) and 16 columns (low nibble 0–F), indexing positions by hexadecimal byte values for precise reference.[3] Undefined bytes, particularly 0x80–0x9F and 0xE0–0xFF, often cause display issues in mismatched encoding environments, where they may render as mojibake—garbled text such as extended Latin characters in Windows-1252 interpreters—or be replaced by substitution glyphs, complicating data exchange between Japanese and international systems.[3]| Hex Byte | Character (Unicode Equivalent) | Description |
|---|---|---|
| 0x21 | ! (U+0021) | Exclamation mark |
| 0x5C | ¥ (U+00A5) | Yen sign |
| 0x7E | ‾ (U+203E) | Overline |
| 0xA1 | 。 (U+FF61) | Half-width ideographic full stop |
| 0xB1 | ア (U+FF71) | Half-width katakana letter a |
| 0xDF | ゚ (U+FF9F) | Half-width katakana semi-voiced sound mark |
Alternative Katakana Arrangements
In the Windows-31J encoding, a Microsoft extension of Shift JIS that incorporates elements of JIS X 0201, the half-width katakana and related punctuation use the identical mappings as JIS X 0201 from 0xA1 to 0xDF (U+FF61 through U+FF9F), with 0xA0 remaining undefined. This alignment facilitates consistent rendering in Microsoft environments with Unicode's half-width and full-width forms block.[20][21] Early terminal and computer adaptations, particularly on the NEC PC-98 series, introduced shifts in katakana placement to accommodate hardware limitations and enhance display capabilities. These systems extended JIS X 0201 by utilizing the C1 control range (0x80–0x9F) for non-standard characters like progress bars and box-drawing elements, while incorporating half-width diacritic katakana forms into row 10 of the related JIS X 0208 standard, effectively relocating some katakana representations to double-byte sequences (e.g., via lead bytes in 0x80–0xBF ranges) for optimized 8x8 pixel font rendering on limited ROM.[22] The ISO 2022-JP encoding, designed for 7-bit transmission, handles JIS X 0201 katakana through escape sequence-based mode switches to the ISO-IR 13 (7-bit katakana) designation, where characters are temporarily mapped across the printable GL range (0x21–0x7E, excluding controls) in a linear arrangement differing from the fixed 8-bit upper-half positioning of the core standard. This approach allows dynamic invocation of katakana without dedicating a full byte plane, prioritizing bandwidth efficiency in networked or serial communications.[23] These alternative arrangements emerged primarily from hardware constraints in 1980s Japan, such as constrained font memory in terminals and the need for backward compatibility with evolving software ecosystems, including DOS variants and proprietary architectures that required flexible code point allocation.[22][3] The proliferation of such variants contributed to interoperability issues, including mismatched character rendering and data corruption during cross-system transfers, which were mitigated by the 1997 revision of JIS X 0201 that refined mappings for greater consistency with emerging internet standards and reduced reliance on vendor-specific extensions.[18]Variants and Implementations
Integration in Shift JIS
Shift JIS, a variable-width character encoding for Japanese text, integrates JIS X 0201 as its single-byte component to ensure compatibility with existing 8-bit systems. Specifically, the Roman characters from JIS X 0201 (bytes 0x20–0x7E) are used directly in Shift JIS, mapping to ASCII equivalents with minor exceptions such as 0x5C for the yen sign (U+00A5) and 0x7E for the overline (U+203E). The half-width katakana characters from JIS X 0201 occupy bytes 0xA1–0xDF, mirroring the exact layout to allow seamless representation of these glyphs without alteration.[24][25] This integration extends JIS X 0201 by incorporating double-byte characters from JIS X 0208, using lead bytes in the ranges 0x81–0x9F and 0xE0–0xEF followed by trail bytes to encode kanji and other symbols, while avoiding overlap with the single-byte JIS X 0201 slots. Developed in 1982 by ASCII Corporation in collaboration with Microsoft to address limitations in escape-sequence-based encodings, Shift JIS was later formalized as an informative specification in Appendix 1 of the JIS X 0208:1997 standard. The design reuses unoccupied code points in JIS X 0201's upper half for lead bytes, enabling mixed single- and double-byte text streams without explicit shift sequences, which improves efficiency in processing Japanese documents on early personal computers.[25][22] The exact mirroring of JIS X 0201's katakana block in Shift JIS facilitates backward compatibility, allowing legacy 8-bit JIS X 0201 data—common in early Japanese computing—to be parsed as valid Shift JIS without modification, supporting upgrades to fuller kanji support. This compatibility was a key benefit, as it preserved data from systems using JIS X 0201's 8-bit extension while expanding to over 6,000 kanji via JIS X 0208. Shift JIS became the dominant encoding for Japanese text in Microsoft Windows environments from the 1980s through the early 2000s, powering applications and web content until the widespread adoption of UTF-8 for broader international support.[24][25][22]IBM and Other Proprietary Adaptations
IBM developed EBCDIC-JP, also known as code page 290 or CCSID 290, as a single-byte encoding for mainframe systems to support Japanese text processing. This adaptation maps characters from JIS X 0201 to EBCDIC positions in the hexadecimal range 0x40 to 0xFE, including half-width katakana characters primarily in the 0x41 to 0xD9 range, enabling compatibility with EBCDIC-based environments while incorporating JIS X 0201's Roman and katakana sets for data interchange in Japanese enterprise applications.[26][27] IBM Code Page 943 (IBM-943 or CCSID 943) extends JIS X 0201 within a Shift JIS-like framework for OS/2 and other IBM platforms, designating single-byte positions 0x20–0x7E and 0xA1–0xDF for JIS X 0201's ASCII-compatible and half-width katakana characters, respectively, with minor exceptions for variant mappings. It incorporates custom control characters and reserves ranges like 0x81–0x9F and 0xE0–0xFC for double-byte lead bytes, allowing seamless integration of single-byte JIS X 0201 elements into multibyte Japanese text handling on IBM systems.[28] Apple's MacJapanese encoding, registered as x-mac-japanese, builds on JIS X 0201 as the foundation for its single-byte components, utilizing the half-width katakana set in positions 0xA1–0xDF while introducing vendor-specific extensions for additional katakana forms and punctuation to support Macintosh applications in Japanese locales. This adaptation ensures compatibility with JIS X 0201's core structure but modifies certain mappings for Apple's text rendering and input methods.[29][30] NEC's variants for the PC-9800 series incorporate JIS X 0201 compliance through dedicated font sets, featuring high-resolution and low-resolution half-width katakana glyphs tailored for the system's 8x8 and 16x16 pixel displays, with font-specific adjustments to enhance readability in early Japanese computing environments. These implementations maintained JIS X 0201's standard layout but optimized half-width characters for NEC's hardware, including optional kanji ROM expansions.[31] Proprietary extensions to JIS X 0201 often repurposed the undefined 0x80–0x9F range for additional controls or symbols; for instance, IBM variants in code pages like 943 assigned positions such as 0x80 to the yen sign or other non-standard characters, while post-1997 updates in some systems added the Euro symbol (0x80) to accommodate currency changes without disrupting legacy data. These modifications were common in IBM environments to bridge gaps in international standards.[22][28] These IBM and other proprietary adaptations of JIS X 0201 were extensively used in enterprise and mainframe systems throughout the 1980s and 1990s, powering Japanese data processing in sectors like finance and manufacturing until the widespread adoption of Unicode in the early 2000s facilitated global migration.[26][4]References
- https://en.wikibooks.org/wiki/Character_Encodings/Code_Tables/EBCDIC/EBCDIC_290