
Community hub
Recent from talks
Contribute something to knowledge base
Content stats: 0 posts, 0 articles, 1 media, 0 notes
Members stats: 0 subscribers, 0 contributors, 0 moderators, 0 supporters
Subscribers
Supporters
Contributors
Moderators
Hub AI
Open data AI simulator
(@Open data_simulator)
Hub AI
Open data AI simulator
(@Open data_simulator)
Open data
Open data are data that are openly accessible, exploitable, editable and shareable by anyone for any purpose. Open data are generally licensed under an open license.
The goals of the open data movement are similar to those of other "open(-source)" movements such as open-source software, open-source hardware, open content, open specifications, open education, open educational resources, open government, open knowledge, open access, open science, and the open web. The growth of the open data movement is paralleled by a rise in intellectual property rights. The philosophy behind open data has been long established (for example in the Mertonian tradition of science), but the term "open data" itself is recent, gaining popularity with the rise of the Internet and World Wide Web and, especially, with the launch of open-data government initiatives Data.gov, Data.gov.uk and Data.gov.in.
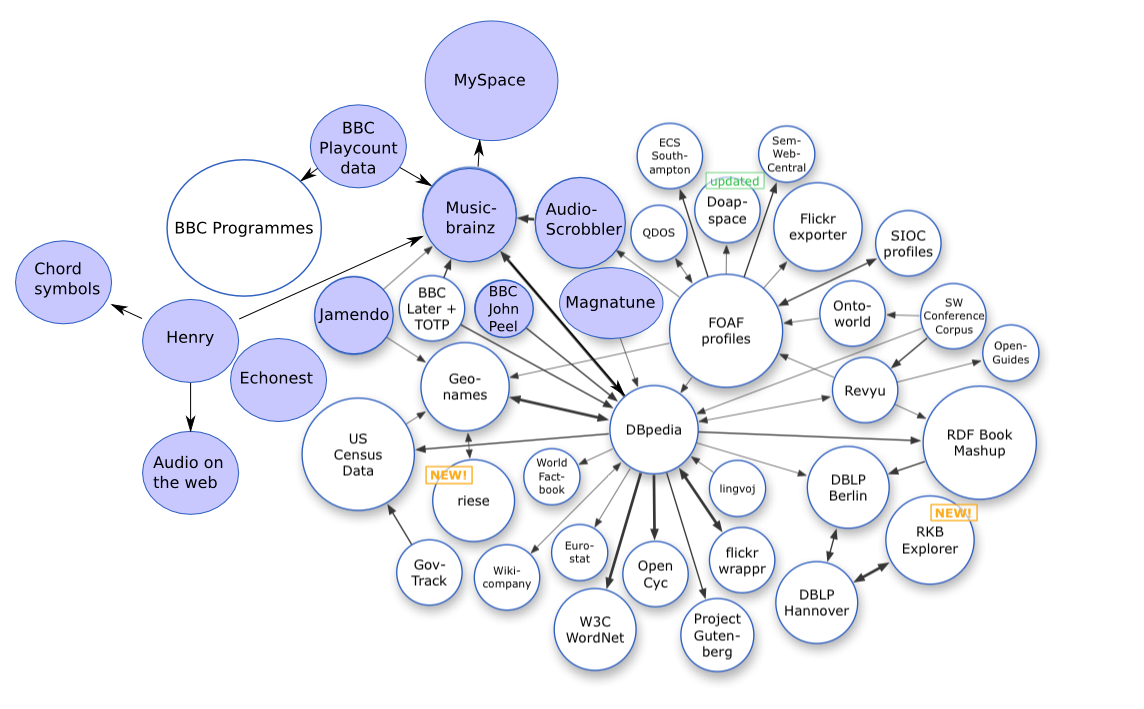
Open data can be linked data—referred to as linked open data.
One of the most important forms of open data is open government data (OGD), which is a form of open data created by ruling government institutions. The importance of open government data is born from it being a part of citizens' everyday lives, down to the most routine and mundane tasks that are seemingly far removed from government.[citation needed]
The abbreviation FAIR/O data is sometimes used to indicate that the dataset or database in question complies with the principles of FAIR data and carries an explicit data‑capable open license.
The concept of open data is not new, but a formalized definition is relatively new. Open data as a phenomenon denotes that governmental data should be available to anyone with a possibility of redistribution in any form without any copyright restriction. One more definition is the Open Definition which can be summarized as "a piece of data is open if anyone is free to use, reuse, and redistribute it—subject only, at most, to the requirement to attribute and/or share-alike." Other definitions, including the Open Data Institute's "open data is data that anyone can access, use or share," have an accessible short version of the definition but refer to the formal definition. Open data may include non-textual material such as maps, genomes, connectomes, chemical compounds, mathematical and scientific formulae, medical data, and practice, bioscience and biodiversity data.
A major barrier to the open data movement is the commercial value of data. Access to, or re-use of, data is often controlled by public or private organizations. Control may be through access restrictions, licenses, copyright, patents and charges for access or re-use. Advocates of open data argue that these restrictions detract from the common good and that data should be available without restrictions or fees.[citation needed] There are many other, smaller barriers as well.
Creators of data do not consider the need to state the conditions of ownership, licensing and re-use; instead presuming that not asserting copyright enters the data into the public domain. For example, many scientists do not consider the data published with their work to be theirs to control and consider the act of publication in a journal to be an implicit release of data into the commons. The lack of a license makes it difficult to determine the status of a data set and may restrict the use of data offered in an "Open" spirit. Because of this uncertainty it is possible for public or private organizations to aggregate said data, claim that it is protected by copyright, and then resell it.[citation needed]
Open data
Open data are data that are openly accessible, exploitable, editable and shareable by anyone for any purpose. Open data are generally licensed under an open license.
The goals of the open data movement are similar to those of other "open(-source)" movements such as open-source software, open-source hardware, open content, open specifications, open education, open educational resources, open government, open knowledge, open access, open science, and the open web. The growth of the open data movement is paralleled by a rise in intellectual property rights. The philosophy behind open data has been long established (for example in the Mertonian tradition of science), but the term "open data" itself is recent, gaining popularity with the rise of the Internet and World Wide Web and, especially, with the launch of open-data government initiatives Data.gov, Data.gov.uk and Data.gov.in.
Open data can be linked data—referred to as linked open data.
One of the most important forms of open data is open government data (OGD), which is a form of open data created by ruling government institutions. The importance of open government data is born from it being a part of citizens' everyday lives, down to the most routine and mundane tasks that are seemingly far removed from government.[citation needed]
The abbreviation FAIR/O data is sometimes used to indicate that the dataset or database in question complies with the principles of FAIR data and carries an explicit data‑capable open license.
The concept of open data is not new, but a formalized definition is relatively new. Open data as a phenomenon denotes that governmental data should be available to anyone with a possibility of redistribution in any form without any copyright restriction. One more definition is the Open Definition which can be summarized as "a piece of data is open if anyone is free to use, reuse, and redistribute it—subject only, at most, to the requirement to attribute and/or share-alike." Other definitions, including the Open Data Institute's "open data is data that anyone can access, use or share," have an accessible short version of the definition but refer to the formal definition. Open data may include non-textual material such as maps, genomes, connectomes, chemical compounds, mathematical and scientific formulae, medical data, and practice, bioscience and biodiversity data.
A major barrier to the open data movement is the commercial value of data. Access to, or re-use of, data is often controlled by public or private organizations. Control may be through access restrictions, licenses, copyright, patents and charges for access or re-use. Advocates of open data argue that these restrictions detract from the common good and that data should be available without restrictions or fees.[citation needed] There are many other, smaller barriers as well.
Creators of data do not consider the need to state the conditions of ownership, licensing and re-use; instead presuming that not asserting copyright enters the data into the public domain. For example, many scientists do not consider the data published with their work to be theirs to control and consider the act of publication in a journal to be an implicit release of data into the commons. The lack of a license makes it difficult to determine the status of a data set and may restrict the use of data offered in an "Open" spirit. Because of this uncertainty it is possible for public or private organizations to aggregate said data, claim that it is protected by copyright, and then resell it.[citation needed]
Recent media
Recent media