
Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
Hotelling's T-squared distribution
View on Wikipedia| Hotelling's T2 distribution | |||
|---|---|---|---|
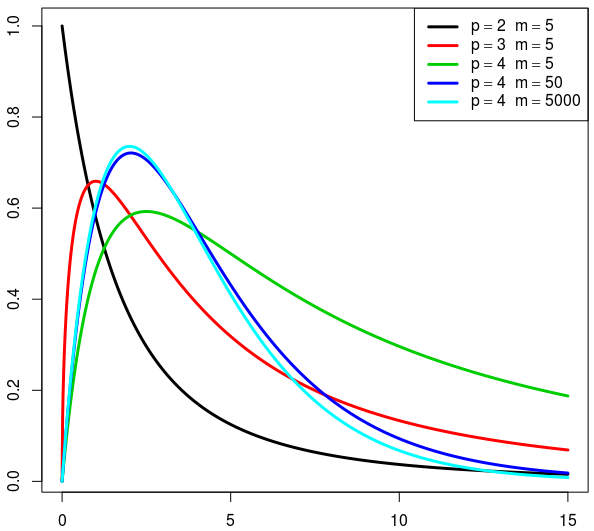
|
Probability density function  | |||
|
Cumulative distribution function  | |||
| Parameters |
p - dimension of the random variables m - related to the sample size | ||
| Support |
if otherwise. | ||



In statistics, particularly in hypothesis testing, the Hotelling's T-squared distribution (T2), proposed by Harold Hotelling,[1] is a multivariate probability distribution that is tightly related to the F-distribution and is most notable for arising as the distribution of a set of sample statistics that are natural generalizations of the statistics underlying the Student's t-distribution. The Hotelling's t-squared statistic (t2) is a generalization of Student's t-statistic that is used in multivariate hypothesis testing.[2]
Motivation
[edit]The distribution arises in multivariate statistics in undertaking tests of the differences between the (multivariate) means of different populations, where tests for univariate problems would make use of a t-test. The distribution is named for Harold Hotelling, who developed it as a generalization of Student's t-distribution.[1]
Definition
[edit]If the vector is Gaussian multivariate-distributed with zero mean and unit covariance matrix and is a random matrix with a Wishart distribution with unit scale matrix and m degrees of freedom, and d and M are independent of each other, then the quadratic form has a Hotelling distribution (with parameters and ):[3]









It can be shown that if a random variable X has Hotelling's T-squared distribution, , then:[1] where is the F-distribution with parameters p and m − p + 1.



Hotelling t-squared statistic
[edit]Let be the sample covariance:


where we denote transpose by an apostrophe. It can be shown that is a positive (semi) definite matrix and follows a p-variate Wishart distribution with n − 1 degrees of freedom.[4] The sample covariance matrix of the mean reads .[5]


The Hotelling's t-squared statistic is then defined as:[6]

which is proportional to the Mahalanobis distance between the sample mean and . Because of this, one should expect the statistic to assume low values if , and high values if they are different.


From the distribution,

where is the F-distribution with parameters p and n − p.

In order to calculate a p-value (unrelated to p variable here), note that the distribution of equivalently implies that


Then, use the quantity on the left hand side to evaluate the p-value corresponding to the sample, which comes from the F-distribution. A confidence region may also be determined using similar logic.
Motivation
[edit]Let denote a p-variate normal distribution with location and known covariance . Let



be n independent identically distributed (iid) random variables, which may be represented as column vectors of real numbers. Define


to be the sample mean with covariance . It can be shown that


where is the chi-squared distribution with p degrees of freedom.[7]

Proof
|
|---|
|
Proof
Every positive-semidefinite symmetric matrix has a positive-semidefinite symmetric square root , and if it is nonsingular, then its inverse has a positive-definite square root . Since , we have Consequently and this is simply the sum of squares of independent standard normal random variables. Thus its distribution is |




![{\displaystyle {\begin{aligned}\operatorname {var} \left(\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}{\overline {\boldsymbol {x}}}\right)&=\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}{\Big (}\operatorname {var} \left({\overline {\boldsymbol {x}}}\right){\Big )}\left(\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}\right)^{T}\\[5pt]&=\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}{\Big (}\operatorname {var} \left({\overline {\boldsymbol {x}}}\right){\Big )}\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}{\text{ because }}\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}{\text{ is symmetric}}\\[5pt]&=\left(\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{1/2}\right)\left(\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{1/2}\mathbf {\Sigma } _{\overline {\boldsymbol {x}}}^{-1/2}\right)\\[5pt]&=\mathbf {I} _{p}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/233c43eefadbcf9abcdff40e73cff853019bee5e)



Alternatively, one can argue using density functions and characteristic functions, as follows.
Proof
|
|---|
|
Proof
To show this use the fact that and derive the characteristic function of the random variable . As usual, let denote the determinant of the argument, as in . By definition of characteristic function, we have:[8] There are two exponentials inside the integral, so by multiplying the exponentials we add the exponents together, obtaining: Now take the term off the integral, and multiply everything by an identity , bringing one of them inside the integral: But the term inside the integral is precisely the probability density function of a multivariate normal distribution with covariance matrix and mean , so when integrating over all , it must yield per the probability axioms.[clarification needed] We thus end up with: where is an identity matrix of dimension . Finally, calculating the determinant, we obtain: which is the characteristic function for a chi-square distribution with degrees of freedom. |




![{\displaystyle {\begin{aligned}\varphi _{\mathbf {y} }(\theta )&=\operatorname {E} e^{i\theta \mathbf {y} },\\[5pt]&=\operatorname {E} e^{i\theta ({\overline {\mathbf {x} }}-{\boldsymbol {\mu }})'({\mathbf {\Sigma } }/n)^{-1}({\overline {\mathbf {x} }}-{\boldsymbol {\mathbf {\mu } }})}\\[5pt]&=\int e^{i\theta ({\overline {\mathbf {x} }}-{\boldsymbol {\mu }})'n{\mathbf {\Sigma } }^{-1}({\overline {\mathbf {x} }}-{\boldsymbol {\mathbf {\mu } }})}(2\pi )^{-p/2}|{\boldsymbol {\Sigma }}/n|^{-1/2}\,e^{-(1/2)({\overline {\mathbf {x} }}-{\boldsymbol {\mu }})'n{\boldsymbol {\Sigma }}^{-1}({\overline {\mathbf {x} }}-{\boldsymbol {\mu }})}\,dx_{1}\cdots dx_{p}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4f7443b5a91e8899f181974528a7d34bf9e047a)




![{\displaystyle ({\boldsymbol {\Sigma }}^{-1}-2i\theta {\boldsymbol {\Sigma }}^{-1})^{-1}/n=\left[n({\boldsymbol {\Sigma }}^{-1}-2i\theta {\boldsymbol {\Sigma }}^{-1})\right]^{-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b2e30acda26292ba3fcf5d6d302141d34fcebce5)



![{\displaystyle {\begin{aligned}&=\left|({\boldsymbol {\Sigma }}^{-1}-2i\theta {\boldsymbol {\Sigma }}^{-1})^{-1}\cdot {\frac {1}{n}}\right|^{1/2}|{\boldsymbol {\Sigma }}/n|^{-1/2}\\&=\left|({\boldsymbol {\Sigma }}^{-1}-2i\theta {\boldsymbol {\Sigma }}^{-1})^{-1}\cdot {\frac {1}{\cancel {n}}}\cdot {\cancel {n}}\cdot {\boldsymbol {\Sigma }}^{-1}\right|^{1/2}\\&=\left|\left[({\cancel {{\boldsymbol {\Sigma }}^{-1}}}-2i\theta {\cancel {{\boldsymbol {\Sigma }}^{-1}}}){\cancel {\boldsymbol {\Sigma }}}\right]^{-1}\right|^{1/2}\\&=|\mathbf {I} _{p}-2i\theta \mathbf {I} _{p}|^{-1/2}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d7b99da9756cc4c6b0312d41367697e0aa53eaca)



Two-sample statistic
[edit]If and , with the samples independently drawn from two independent multivariate normal distributions with the same mean and covariance, and we define



as the sample means, and

as the respective sample covariance matrices. Then

is the unbiased pooled covariance matrix estimate (an extension of pooled variance).
Finally, the Hotelling's two-sample t-squared statistic is

Related concepts
[edit]It can be related to the F-distribution by[4]

The non-null distribution of this statistic is the noncentral F-distribution (the ratio of a non-central Chi-squared random variable and an independent central Chi-squared random variable) with where is the difference vector between the population means.



In the two-variable case, the formula simplifies nicely allowing appreciation of how the correlation, , between the variables affects . If we define and then Thus, if the differences in the two rows of the vector are of the same sign, in general, becomes smaller as becomes more positive. If the differences are of opposite sign becomes larger as becomes more positive.



![{\displaystyle t^{2}={\frac {n_{x}n_{y}}{(n_{x}+n_{y})(1-\rho ^{2})}}\left[\left({\frac {d_{1}}{s_{1}}}\right)^{2}+\left({\frac {d_{2}}{s_{2}}}\right)^{2}-2\rho \left({\frac {d_{1}}{s_{1}}}\right)\left({\frac {d_{2}}{s_{2}}}\right)\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98484fd561e69c414a3091e297e110b4c75fda03)

A univariate special case can be found in Welch's t-test.
More robust and powerful tests than Hotelling's two-sample test have been proposed in the literature, see for example the interpoint distance based tests which can be applied also when the number of variables is comparable with, or even larger than, the number of subjects.[9][10]
See also
[edit]- Student's t-test in univariate statistics
- Student's t-distribution in univariate probability theory
- Multivariate Student distribution
- F-distribution (commonly tabulated or available in software libraries, and hence used for testing the T-squared statistic using the relationship given above)
- Wilks's lambda distribution (in multivariate statistics, Wilks's Λ is to Hotelling's T2 as Snedecor's F is to Student's t in univariate statistics)
References
[edit]- ^ a b c Hotelling, H. (1931). "The generalization of Student's ratio". Annals of Mathematical Statistics. 2 (3): 360–378. doi:10.1214/aoms/1177732979.
- ^ Johnson, R.A.; Wichern, D.W. (2002). Applied multivariate statistical analysis. Vol. 5. Prentice hall.
- ^ Eric W. Weisstein, MathWorld
- ^ a b Mardia, K. V.; Kent, J. T.; Bibby, J. M. (1979). Multivariate Analysis. Academic Press. ISBN 978-0-12-471250-8.
- ^ Fogelmark, Karl; Lomholt, Michael; Irbäck, Anders; Ambjörnsson, Tobias (3 May 2018). "Fitting a function to time-dependent ensemble averaged data". Scientific Reports. 8 (1): 6984. doi:10.1038/s41598-018-24983-y. PMC 5934400. Retrieved 19 August 2024.
- ^ "6.5.4.3. Hotelling's T squared".
- ^ End of chapter 4.2 of Johnson, R.A. & Wichern, D.W. (2002)
- ^ Billingsley, P. (1995). "26. Characteristic Functions". Probability and measure (3rd ed.). Wiley. ISBN 978-0-471-00710-4.
- ^ Marozzi, M. (2016). "Multivariate tests based on interpoint distances with application to magnetic resonance imaging". Statistical Methods in Medical Research. 25 (6): 2593–2610. doi:10.1177/0962280214529104. PMID 24740998.
- ^ Marozzi, M. (2015). "Multivariate multidistance tests for high-dimensional low sample size case-control studies". Statistics in Medicine. 34 (9): 1511–1526. doi:10.1002/sim.6418. PMID 25630579.
External links
[edit]- Prokhorov, A.V. (2001) [1994], T2-distribution "Hotelling T2-distribution", Encyclopedia of Mathematics, EMS Press
Hotelling's T-squared distribution
View on GrokipediaIntroduction and Motivation
Historical Background
Hotelling's T-squared distribution originated in the context of early 20th-century advancements in multivariate statistical analysis, which sought to extend univariate techniques to handle correlated multiple variables. P. C. Mahalanobis advanced the field by developing measures of group divergence, including the generalized distance statistic known as Mahalanobis' D², first proposed in his 1930 paper "On Tests of Significance in Anthropometry" and further elaborated in 1936.[5] Harold Hotelling built upon this emerging framework in 1931 by introducing the T² distribution as a multivariate generalization of Student's t-ratio, specifically for testing hypotheses about the mean vector of a multivariate normal distribution.[1] In his seminal paper published in the Annals of Mathematical Statistics, Hotelling derived the distribution of the statistic formed by the sample mean and covariance matrix, enabling inference in higher dimensions.[1] This work marked a pivotal step in multivariate hypothesis testing, bridging univariate and multidimensional statistical theory. Later, Ronald A. Fisher contributed foundational ideas through his 1936 paper on the use of multiple measurements in taxonomic problems, introducing linear discriminant analysis to classify observations using multiple measurements.[6]Relation to Univariate Distributions
The univariate Student's t-statistic is employed to test hypotheses concerning the mean of a single normally distributed variable when the population variance is unknown and estimated from the sample, yielding a distribution that accounts for the additional uncertainty in variance estimation. This approach is fundamental for one-dimensional inference under normality. Hotelling's T-squared distribution generalizes this framework to multivariate settings, where the goal is to test hypotheses about a vector of population means while incorporating the full covariance structure among the variables. Unlike the univariate case, which ignores correlations, the T-squared statistic adjusts for the dependencies via the sample covariance matrix, providing a unified measure of deviation that respects the multidimensional nature of the data. This extension is essential for analyzing vector-valued observations, such as in principal component analysis or profile monitoring, where univariate tests would overlook inter-variable relationships.[1] In the special case where the dimension , Hotelling's T-squared statistic simplifies to , where follows the univariate Student's t-distribution with degrees of freedom, and this quantity follows an F random variable with parameters 1 and . For large sample sizes , the T-squared distribution further approximates a chi-squared distribution with degrees of freedom, mirroring the asymptotic convergence of the squared univariate t-statistic to a chi-squared with 1 degree of freedom and underscoring the distributional continuity between univariate and multivariate paradigms.[1][2]Mathematical Definition
Parameters and Support
Hotelling's distribution is a multivariate generalization of the distribution, parameterized by two positive integers: , the dimension of the underlying multivariate normal random vector (corresponding to the number of variates or the degrees of freedom in the numerator of the related distribution), and , the degrees of freedom associated with the Wishart-distributed sample covariance matrix (often for a sample of size ). These parameters arise in the context of testing hypotheses about the mean of a -dimensional normal distribution based on independent observations, where the sample covariance matrix provides an unbiased estimate of the population covariance with degrees of freedom.[1] The random variable is defined through the quadratic form where is a standard -dimensional normal vector and is an independent Wishart random matrix with scale matrix and degrees of freedom. This form captures the scaled Mahalanobis distance between the sample mean and a hypothesized mean, adjusted by the inverse sample covariance.[7] The support of is the non-negative real line, , reflecting its origin as a squared distance measure that is zero only if the vector is exactly at the origin (which occurs with probability zero). The distribution is well-defined for positive integer values and , the latter condition ensuring that the Wishart matrix is almost surely positive definite, allowing the inverse to exist and the quadratic form to be properly defined.[7][8]Probability Density Function
The probability density function of Hotelling's distribution, parameterized by the dimensionality and degrees of freedom , is given by where denotes the gamma function. This density is derived from the construction of the statistic as , where is a -dimensional standard multivariate normal random vector and is an independent Wishart-distributed random matrix with degrees of freedom and scale matrix . The joint density of and is integrated over the transformation yielding , leveraging the known densities of the normal and Wishart distributions to obtain the marginal form for . This density can be derived from the relation , or equivalently, where . Alternative representations of the density facilitate computational evaluation, particularly through the gamma functions in the normalizing constant, which relate to integrals expressible via the multivariate beta function for cumulative probabilities or series expansions involving zonal polynomials.[9]Properties
Relation to Other Distributions
Hotelling's distribution is fundamentally connected to the distribution, serving as its multivariate generalization analogous to how the distribution relates to the univariate . For a random variable following the central Hotelling's distribution, where is the dimension and is the degrees of freedom, the transformation follows an distribution with and degrees of freedom, respectively.[10] This equivalence, derived from the ratio of quadratic forms in multivariate normal variables, enables practical computation of critical values and p-values using standard tables, mirroring the univariate case where . In the noncentral case, where the underlying multivariate normal distribution has a non-zero mean vector, follows a noncentral Hotelling's distribution, with noncentrality parameter related to the squared Mahalanobis distance. A scaled version of this noncentral follows a noncentral distribution, where , extending the central relation and accounting for deviations from the null hypothesis.[10] When the population covariance matrix is known, the Hotelling's statistic simplifies to , which follows a distribution exactly under the multivariate normal assumption. Asymptotically, as the sample size (with ), .[2][10] The derivation of these relations stems from the structure of as a quadratic form: if and are independent, then follows Hotelling's . This leverages properties of the Wishart distribution (generalizing the chi-squared) and the independence of normal quadratic forms, leading to the transformation via the beta distribution linkage between chi-squared variates.Moments and Characteristic Function
The expected value of a random variable following Hotelling's distribution with parameters (dimension) and (degrees of freedom) is given by This expression arises from the distributional properties of the statistic under the multivariate normal assumption and can be verified using its relation to the distribution.[2] The variance of is for . This formula accounts for the dependence structure in the multivariate setting and ensures the variance is finite when the degrees of freedom exceed the dimension plus three. Higher moments of can be computed using hypergeometric functions, such as the confluent hypergeometric function, or through recursive relations derived from the matrix variate representations of the distribution. These approaches leverage the connection to Wishart matrices and provide explicit expressions for cumulants beyond the second order, though they become increasingly complex for orders greater than four. As , converges in distribution to , illustrating the asymptotic normality and providing a basis for large-sample approximations in multivariate inference.[2]Hotelling's T-squared Statistic
One-Sample Formulation
The one-sample Hotelling's test assesses whether the population mean vector of a -variate normally distributed random sample equals a specified vector . This test generalizes the univariate one-sample -test to the multivariate setting, accounting for correlations among the variables. The null hypothesis is against the alternative . The test relies on a random sample drawn independently from an MVN distribution, where the covariance matrix is positive definite but unknown. Under these assumptions, the sample mean vector follows an MVN distribution. The sample covariance matrix is defined as and follows a Wishart distribution. The Hotelling's statistic for the one-sample test is given by \begin{equation} T^2 = n (\bar{\mathbf{x}} - \boldsymbol{\mu}_0)^\top \mathbf{S}^{-1} (\bar{\mathbf{x}} - \boldsymbol{\mu}_0). \end{equation} This statistic measures the squared Mahalanobis distance between the sample mean and the hypothesized mean, scaled by the sample size and weighted by the inverse sample covariance. Under , follows a Hotelling's distribution with parameters (dimension) and (degrees of freedom), denoted . To conduct the test at significance level , the rejection region is determined using the known relationship between the distribution and the distribution: \begin{equation} \frac{(n-p) T^2}{p (n-1)} \sim F(p, n-p) \end{equation} under . The null hypothesis is rejected if where is the upper quantile of the distribution with and degrees of freedom. This transformation allows practical computation using standard -tables or software. As an illustrative example, consider testing whether the mean vector of heights, weights, and BMIs in a population equals specified values cm, kg, and kg/m², respectively, using a sample of individuals (). Compute and from the data, form , and compare the transformed statistic to the critical value at the desired to decide on .Sampling Distribution
Under the null hypothesis , where is the population mean vector, the one-sample Hotelling's statistic follows a central Hotelling's distribution with parameters (the dimension of the random vector) and (where is the sample size), denoted . This distribution arises under the assumption of multivariate normality for the observations.[2] The central distribution is closely related to the central distribution through the transformation where denotes the central distribution with and degrees of freedom. This equivalence facilitates the use of tables for critical values and p-value computation in hypothesis testing.[2] Under the alternative hypothesis , the statistic follows a noncentral Hotelling's distribution, , with noncentrality parameter , where and is the population covariance matrix. This noncentral distribution corresponds to a noncentral distribution via a similar scaling, with degrees of freedom and , and the same noncentrality parameter .[11] For large , the distribution of under approximates a central chi-squared distribution with degrees of freedom, . P-values under are typically obtained from distribution tables or cumulative distribution functions, while under the alternative, they involve numerical integration of the noncentral density or Monte Carlo simulation.[2][11]Two-Sample Test
Formulation and Assumptions
The two-sample Hotelling's T-squared test assesses whether the mean vectors of two independent multivariate populations differ, serving as a multivariate analogue to the univariate two-sample t-test for comparing means under the assumption of equal covariances.[12] Consider two independent random samples: one of size drawn from a -variate normal distribution , , and another of size from , , where the covariance matrix is common to both populations.[12] The null hypothesis is , with the alternative .[13] The test statistic is given by where and are the sample mean vectors, and and are the sample covariance matrices from the respective samples.[12] This formulation incorporates a pooled estimate of the covariance matrix, , which weights the individual sample covariances by their respective degrees of freedom.[12] Under the normality assumption, and , ensuring that .[13] Under , the statistic follows a Hotelling's T-squared distribution with degrees of freedom and scale parameter , denoted .[12] This relates to the general Hotelling's T-squared distribution as an extension for comparing two samples. For practical inference, is often transformed to an F statistic analogous to the one-sample case but with adjusted degrees of freedom: [13] Key assumptions include multivariate normality for both populations, independence between samples, and homogeneity of the covariance matrix across groups; violations, particularly of normality or equal covariances, can affect the test's validity.[12]Power and Limitations
The power of the two-sample Hotelling's test is determined by the noncentrality parameter , where represents the difference between the population mean vectors and is the common covariance matrix.[14] This parameter quantifies the magnitude of the mean difference relative to the variability, scaled by the effective sample size .[15] As increases with larger sample sizes or greater effect sizes (larger in the metric defined by ), the test's power to detect true differences improves, approaching 1 for sufficiently large .[16] A key limitation of the test arises from its sensitivity to violations of the multivariate normality assumption, which can lead to distorted Type I error rates and reduced power, particularly under heavy-tailed or skewed distributions.[17] Similarly, the assumption of equal covariance matrices across groups is critical; when violated, the test suffers from the multivariate analog of the Behrens-Fisher problem, resulting in liberal or conservative p-values depending on the discrepancy.[18] In such scenarios, alternatives like robust estimators or permutation-based methods are often recommended over standard Hotelling's .[19] The test also faces challenges in high-dimensional settings where the number of variables approaches or exceeds the total sample size , causing the pooled covariance matrix to become singular and the test undefined.[20] To address non-normality or unequal covariances, bootstrapping procedures provide a robust alternative by empirically estimating the sampling distribution without relying on parametric assumptions, though they increase computational demands.[17] Unlike performing separate univariate t-tests on each variable, which ignore correlations and can inflate the family-wise error rate or miss joint effects, the Hotelling's test explicitly accounts for inter-variable dependencies through the covariance structure, yielding more powerful and coherent inference for multivariate data.[21]Applications and Extensions
Use in Multivariate Analysis
Hotelling's T-squared statistic serves as a key test statistic in multivariate analysis of variance (MANOVA), where it evaluates overall differences in mean vectors across multiple groups for several dependent variables simultaneously. In this framework, the statistic extends the univariate t-test to multivariate settings, allowing researchers to assess whether group means differ significantly while accounting for correlations among variables, under assumptions of multivariate normality and homogeneity of covariance matrices. This application is particularly valuable when analyzing complex datasets where univariate tests might overlook inter-variable relationships, as demonstrated in foundational developments linking T-squared to MANOVA procedures.[22][23] In chemometrics, Hotelling's T-squared is widely applied to test multivariate means in high-dimensional spectral data, such as near-infrared spectroscopy for quality assurance in pharmaceuticals or food analysis. For instance, it detects deviations in spectral profiles from reference means, enabling outlier identification and process monitoring in multivariate control charts derived from principal component analysis. These applications leverage T-squared's sensitivity to Mahalanobis distances, providing robust assessments of batch-to-batch variability in chemical processes. In behavioral sciences, the statistic tests differences in multivariate profiles like IQ subscores and achievement measures across groups, such as comparing cognitive performance in children with ADHD versus those with low working memory. Such analyses reveal group effects on composite IQ vectors, informing interventions by highlighting correlated deficits in verbal and performance domains.[24][4][25][26] Extensions of Hotelling's T-squared facilitate the construction of simultaneous confidence intervals for multivariate means, forming ellipsoidal regions that bound plausible parameter values with joint coverage probabilities. These T-squared-based ellipsoids ensure control over family-wise error rates, offering a geometric visualization of uncertainty in mean estimates superior to separate univariate intervals, especially when variables are correlated.[27][28]Computational Implementations
In statistical software, Hotelling's statistic can be computed using dedicated functions in packages for R, Python, and MATLAB, facilitating one-sample and two-sample tests under multivariate normal assumptions.[29][30] In R, the ICSNP package provides theHotellingsT2 function for parametric Hotelling's tests in one- and two-sample cases, serving as a reference for nonparametric extensions.[31] Alternatively, the base manova function can perform equivalent tests by framing the problem as a multivariate analysis of variance with a single group or factor. For a one-sample test against a hypothesized mean vector , the DescTools package offers HotellingsT2Test with straightforward usage:
library(DescTools)
# Assume x is an n x p matrix of multivariate [data](/page/Data)
result <- HotellingsT2Test(x, mu = 0)
print(result)
library(DescTools)
# Assume x is an n x p matrix of multivariate [data](/page/Data)
result <- HotellingsT2Test(x, mu = 0)
print(result)
test_mvmean for one-sample cases and test_mvmean_2indep for two independent samples, often in conjunction with MANOVA frameworks for broader hypothesis testing.[33] For simulations to assess power or generate data under the null, SciPy's multivariate_normal can sample observations, paired with wishart.rvs from the same library to draw sample covariance matrices from a Wishart distribution. The dedicated hotelling package provides direct implementations like T2test_1samp for one-sample tests:
from hotelling import T2test_1samp
import numpy as np
# Assume x is n x p array of data, mu0 is p x 1 hypothesized mean
stat, pval = T2test_1samp(x, mu0=np.zeros(x.shape[1]))
print(f"T2 statistic: {stat}, p-value: {pval}")
from hotelling import T2test_1samp
import numpy as np
# Assume x is n x p array of data, mu0 is p x 1 hypothesized mean
stat, pval = T2test_1samp(x, mu0=np.zeros(x.shape[1]))
print(f"T2 statistic: {stat}, p-value: {pval}")
HotellingT2 function from the File Exchange for one-sample, two independent-sample (homoscedastic or heteroscedastic), and paired-sample tests, returning test statistics, p-values, and confidence intervals.[30] For example, in a one-sample case:
% Assume X is n x p data matrix, mu0 is 1 x p hypothesized mean
[h, p, ci, stats] = HotellingT2(X, mu0, 'type', 'one');
fprintf('T2 statistic: %f, p-value: %f\n', stats.T2, p);
% Assume X is n x p data matrix, mu0 is 1 x p hypothesized mean
[h, p, ci, stats] = HotellingT2(X, mu0, 'type', 'one');
fprintf('T2 statistic: %f, p-value: %f\n', stats.T2, p);