
Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
FMA instruction set
View on WikipediaThe FMA instruction set is an extension to the 128- and 256-bit Streaming SIMD Extensions instructions in the x86 microprocessor instruction set to perform fused multiply–add (FMA) operations.[1] There are two variants:
- FMA4 is supported in AMD processors starting with the Bulldozer architecture. FMA4 was performed in hardware before FMA3 was. Support for FMA4 has been removed since Zen 1.[2]
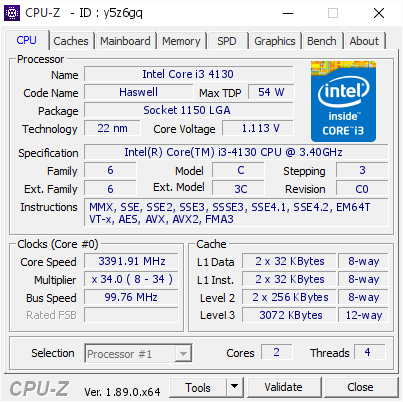
- FMA3 is supported in AMD processors starting with the Piledriver architecture and Intel starting with Haswell processors and Broadwell processors since 2014.
Instructions
[edit]FMA3 and FMA4 instructions have almost identical functionality, but are not compatible. Both contain fused multiply–add (FMA) instructions for floating-point scalar and SIMD operations, but FMA3 instructions have three operands, while FMA4 ones have four. The FMA operation has the form d = round(a · b + c), where the round function performs a rounding to allow the result to fit within the destination register if there are too many significant bits to fit within the destination.
The four-operand form (FMA4) allows a, b, c and d to be four different registers, while the three-operand form (FMA3) requires that d be the same register as a, b or c. The three-operand form makes the code shorter and the hardware implementation slightly simpler, while the four-operand form provides more programming flexibility.
See XOP instruction set for more discussion of compatibility issues between Intel and AMD.
FMA3 instruction set
[edit]CPUs with FMA3
[edit]- AMD
- Piledriver (2012) and newer microarchitectures[3]
- 2nd gen APUs, "Trinity" (32nm), May 15, 2012
- 2nd gen "Bulldozer" (bdver2) with Piledriver cores, October 23, 2012
- Piledriver (2012) and newer microarchitectures[3]
- Intel
Excerpt from FMA3
[edit]Supported commands include
| Mnemonic | Operation | Mnemonic | Operation |
|---|---|---|---|
| VFMADD | result = + a · b + c |
VFMADDSUB | result = a · b + c for i = 1, 3, ...result = a · b − c for i = 0, 2, ...
|
| VFNMADD | result = − a · b + c
| ||
| VFMSUB | result = + a · b − c |
VFMSUBADD | result = a · b − c for i = 1, 3, ...result = a · b + c for i = 0, 2, ...
|
| VFNMSUB | result = − a · b − c
|
- Note
- VFNMADD is
result = − a · b + c, notresult = − (a · b + c). - VFNMSUB generates a −0 when all inputs are zero.
Explicit order of operands is included in the mnemonic using numbers "132", "213", and "231":
| Postfix 1 |
Operation | possible memory operand |
overwrites |
|---|---|---|---|
| 132 | a = a · c + b |
c (factor) |
a (other factor)
|
| 213 | a = b · a + c |
c (summand) |
a (factor)
|
| 231 | a = b · c + a |
c (factor) |
a (summand)
|
as well as operand format (packed or scalar) and size (single or double).
| Postfix 2 |
precision | size | Postfix 2 |
precision | size |
|---|---|---|---|---|---|
| SS | Single | 32 bit | SD | Double | 64 bit |
| PSx | 4× 32 bit | PDx | 2× 64 bit | ||
| PSy | 8× 32 bit | PDy | 4× 64 bit | ||
| PSz | 16× 32 bit | PDz | 8× 64 bit |
This results in
| Encoding | Mnemonic | Operands | Operation |
|---|---|---|---|
VEX.256.66.0F38.W1 98 /r
|
VFMADD132PDy | ymm, ymm, ymm/m256 | a = a · c + b
|
VEX.256.66.0F38.W0 98 /r
|
VFMADD132PSy | ||
VEX.128.66.0F38.W1 98 /r
|
VFMADD132PDx | xmm, xmm, xmm/m128 | |
VEX.128.66.0F38.W0 98 /r
|
VFMADD132PSx | ||
VEX.LIG.66.0F38.W1 99 /r
|
VFMADD132SD | xmm, xmm, xmm/m64 | |
VEX.LIG.66.0F38.W0 99 /r
|
VFMADD132SS | xmm, xmm, xmm/m32 | |
VEX.256.66.0F38.W1 A8 /r
|
VFMADD213PDy | ymm, ymm, ymm/m256 | a = b · a + c
|
VEX.256.66.0F38.W0 A8 /r
|
VFMADD213PSy | ||
VEX.128.66.0F38.W1 A8 /r
|
VFMADD213PDx | xmm, xmm, xmm/m128 | |
VEX.128.66.0F38.W0 A8 /r
|
VFMADD213PSx | ||
VEX.LIG.66.0F38.W1 A9 /r
|
VFMADD213SD | xmm, xmm, xmm/m64 | |
VEX.LIG.66.0F38.W0 A9 /r
|
VFMADD213SS | xmm, xmm, xmm/m32 | |
VEX.256.66.0F38.W1 B8 /r
|
VFMADD231PDy | ymm, ymm, ymm/m256 | a = b · c + a
|
VEX.256.66.0F38.W0 B8 /r
|
VFMADD231PSy | ||
VEX.128.66.0F38.W1 B8 /r
|
VFMADD231PDx | xmm, xmm, xmm/m128 | |
VEX.128.66.0F38.W0 B8 /r
|
VFMADD231PSx | ||
VEX.LIG.66.0F38.W1 B9 /r
|
VFMADD231SD | xmm, xmm, xmm/m64 | |
VEX.LIG.66.0F38.W0 B9 /r
|
VFMADD231SS | xmm, xmm, xmm/m32 |
FMA4 instruction set
[edit]CPUs with FMA4
[edit]- AMD
- "Heavy Equipment" processors
- Bulldozer-based processors, October 12, 2011[6]
- Piledriver-based processors[7]
- Steamroller-based processors
- Excavator-based processors (including "v2")
- Zen: WikiChip's testing shows FMA4 still appears to work (under the conditions of the tests) despite not being officially supported and not even reported by CPUID. This has also been confirmed by Agner Fog.[8] But other tests gave wrong results.[9] AMD Official Web Site FMA4 Support Note ZEN CPUs = AMD ThreadRipper 1900x, R7 Pro 1800, 1700, R5 Pro 1600, 1500, R3 Pro 1300, 1200, R3 2200G, R5 2400G.[10][11][12]
- "Heavy Equipment" processors
- Intel
- Intel has not released CPUs with support for FMA4.
Excerpt from FMA4
[edit]| Mnemonic (AT&T) | Operands | Operation |
|---|---|---|
| VFMADDPDx | xmm, xmm, xmm/m128, xmm/m128 | a = b·c + d |
| VFMADDPDy | ymm, ymm, ymm/m256, ymm/m256 | |
| VFMADDPSx | xmm, xmm, xmm/m128, xmm/m128 | |
| VFMADDPSy | ymm, ymm, ymm/m256, ymm/m256 | |
| VFMADDSD | xmm, xmm, xmm/m64, xmm/m64 | |
| VFMADDSS | xmm, xmm, xmm/m32, xmm/m32 |
History
[edit]The incompatibility between Intel's FMA3 and AMD's FMA4 is due to both companies changing plans without coordinating coding details with each other. AMD changed their plans from FMA3 to FMA4 while Intel changed their plans from FMA4 to FMA3 almost at the same time. The history can be summarized as follows:
- August 2007: AMD announces the SSE5 instruction set, which includes 3-operand FMA instructions. A new coding scheme (DREX) is introduced for allowing instructions to have three operands.[13]
- April 2008: Intel announces their AVX and FMA instruction sets, including 4-operand FMA instructions. The coding of these instructions uses the new VEX coding scheme,[14] which is more flexible than AMD's DREX scheme.
- December 2008: Intel changes the specification for their FMA instructions from 4-operand to 3-operand instructions. The VEX coding scheme is still used.[15]
- May 2009: AMD changes the specification of their FMA instructions from the 3-operand DREX form to the 4-operand VEX form, compatible with the April 2008 Intel specification rather than the December 2008 Intel specification.[16]
- October 2011: AMD Bulldozer processor supports FMA4.[17]
- January 2012: AMD announces FMA3 support in future processors codenamed Trinity and Vishera; they are based on the Piledriver architecture.[18]
- May 2012: AMD Piledriver processor supports both FMA3 and FMA4.[17]
- June 2013: Intel Haswell processor supports FMA3.[19]
- February 2017: The first generation of AMD Ryzen processors officially supports FMA3, but not FMA4 according to the CPUID instruction.[2] There has been confusion regarding whether FMA4 was implemented or not on this processor due to errata in the initial patch to the GNU Binutils package that has since been rectified.[20][21] One unconfirmed report of wrong results[9] led to some doubt, but Mysticial (Alexander Yee, developer of y-cruncher) debunked it:[22] FMA4 worked for bit-exact bignum calculations on his Zen 1 system for years, and the one report on Reddit never had any followup investigation to rule out mistakes in the testing software before being widely repeated. The initial Ryzen CPUs could be crashed by a particular sequence of FMA3 instructions, but updated CPU microcode fixes the problem.[23]
- July 2019: AMD Zen 2 and later Ryzen processors don't support FMA4 at all.[24] They continue to support FMA3. Only Zen 1 and Zen+ have unofficial FMA4 support.
Compiler and assembler support
[edit]Different compilers provide different levels of support for FMA:
- GCC supports FMA4 with -mfma4 since version 4.5.0[25] and FMA3 with -mfma since version 4.7.0.
- Microsoft Visual C++ 2010 SP1 supports FMA4 instructions.[26]
- Microsoft Visual C++ 2012 supports FMA3 instructions (if the processor also supports AVX2 instruction set extension).
- Microsoft Visual C++ since VC 2013
- PathScale supports FMA4 with -mfma.[27]
- LLVM 3.1 adds FMA4 support,[28] along with preliminary FMA3 support.[29]
- Open64 5.0 adds "limited support".
- Intel compilers support only FMA3 instructions.[25]
- NASM supports FMA3 instructions since version 2.03 and FMA4 instructions since 2.06.
- FASM supports both FMA3 and FMA4 instructions.
References
[edit]- ^ Woltmann, George (Prime95). "Intel AVX and GIMPS". mersenneforum.org. Great Internet Mersenne Prime Search (GIMPS) project. Retrieved 27 July 2011.
FMA3 and FMA4 are not instruction sets, they are individual instructions -- fused multiply add. They could be quite useful depending on how Intel and AMD implement them
{{cite web}}: CS1 maint: numeric names: authors list (link) - ^ a b "The microarchitecture of Intel, AMD and VIA CPUs An optimization guide for assembly programmers and compiler makers" (PDF). Retrieved 2017-05-02.
- ^ Maffeo, Robin (March 1, 2012). "AMD and the Visual Studio 11 Beta". AMD. Archived from the original on November 9, 2013. Retrieved 2018-11-07.
- ^ "CPU-Z - ID : y5z6gq". Retrieved 2022-05-01.
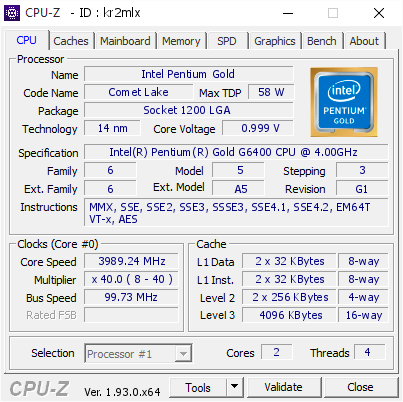
- ^ "CPU-Z - ID : kr2mlx". Retrieved 2022-05-01.
- ^ "AMD64 Architecture Programmer's Manual Volume 6: 128-Bit and 256-Bit XOP, FMA4 and CVT16 Instructions" (PDF). AMD. May 1, 2009.
- ^ "New "Bulldozer" and "Piledriver" Instructions A step forward for high performance software development" (PDF). AMD. October 2012.
- ^ "Agner's CPU blog - Test results for AMD Ryzen". 2017-05-02.
- ^ a b "Discussion – Ryzen has undocumented support for FMA4". Retrieved 2017-05-10.
- ^ "www.amd.com, FMA4 support model list".
- ^ "www.amd.com, FMA4 support model list".
- ^ "www.amd.com, FMA4 support model list".
- ^ "128-Bit SSE5 Instruction Set". AMD Developer Central. Archived from the original on 2008-01-15. Retrieved 2008-01-28.
- ^ "Intel Advanced Vector Extensions Programming Reference" (PDF). Intel. Retrieved 2008-04-05.[permanent dead link]
- ^ "Intel Advanced Vector Extensions Programming Reference". Intel. Retrieved 2009-05-06.
- ^ "Striking a balance". Dave Christie, AMD Developer blogs. May 6, 2009. Archived from the original on July 8, 2012. Retrieved 2018-11-07.
- ^ a b "New Bulldozer and Piledriver Instructions" (PDF). AMD. Retrieved 25 July 2013.
- ^ "Software Optimization Guide for AMD Family 15h Processors" (PDF). AMD. Retrieved 19 April 2012.
- ^ "Intel Architecture Instruction Set Extensions Programming Reference" (PDF). Intel. Retrieved 25 July 2013.
- ^ Gopalasubramanian, Ganesh (2015-03-10). "[PATCH] add znver1 processor". Retrieved 2022-05-01.
- ^ Pawar, Amit (2015-08-07). "[PATCH] Remove CpuFMA4 from Znver1 CPU Flags". Retrieved 2022-05-01.
- ^ "Stack Overflow comment by Mysticial". 2019-07-16. Archived from the original on 2019-08-22. Retrieved 2023-09-01.
{{cite web}}: CS1 maint: bot: original URL status unknown (link) - ^ "AMD Ryzen Machine Crashes to a Sequence of FMA3 Instructions". 16 March 2017. Retrieved 2017-09-10.
- ^ "Stack Overflow comment by Mysticial". 2019-07-16. Retrieved 2023-09-01.
- ^ a b Latif, Lawrence (Nov 14, 2011). "AMD Bulldozer only FMA4 and XOP instructions are supported by GCC Intel still mute". The Inquirer. Archived from the original on November 17, 2011.
- ^ "FMA4 Intrinsics Added for Visual Studio 2010 SP1". 4 February 2013.
- ^ "EKOPath man doc". Archived from the original on 2016-06-23. Retrieved 2013-07-24.
- ^ "LLVM 3.1 Release Notes".
- ^ "Enable detection of AVX and AVX2 support through CPUID". LLVM. 2012-04-26. Archived from the original on 2014-07-26. Retrieved 2017-02-06.
{kind=link}
{kind=link}
FMA instruction set
View on GrokipediaFundamentals
Fused Multiply-Add Operation
The fused multiply-add (FMA) operation is a ternary floating-point arithmetic instruction that computes the expression (or variants such as ) as a single fused step, performing the multiplication and addition without an intermediate rounding after the multiplication.[2][9] This design, standardized in IEEE 754-2008, ensures the intermediate product maintains full precision before addition, with rounding applied only once at the end to the destination format.[10] Execution of the FMA typically proceeds through distinct stages in the processor pipeline: first, a multiplication stage computes the exact product using extended internal precision; second, an addition stage incorporates the third operand (or subtracts it in the variant case); and finally, a single rounding stage converts the accumulated result to the target precision.[2] This fused approach adheres to IEEE 754 compliance by treating the entire computation as if performed with unbounded range and precision, minimizing opportunities for rounding errors.[10] FMA supports common data types including single-precision (binary32, 32 bits), double-precision (binary64, 64 bits), and extended-precision formats (such as 80-bit) where hardware implementations provide them.[2][10] The operation is mathematically expressed in pseudocode as: where applies the active rounding mode—such as round-to-nearest (ties to even), round toward zero, round toward positive infinity, or round toward negative infinity—to fit the result into the destination format, fully aligning with IEEE 754 requirements.[2][9][10] In contrast to non-fused multiply-add sequences, which require two separate instructions (one for multiplication and one for addition) and thus incur additional latency from instruction dispatch and intermediate rounding, FMA consolidates the computation into one instruction, often achieving latency equivalent to a single multiply or add on capable processors.[11][2] This reduction in instruction count enhances throughput in compute-intensive applications while preserving or improving numerical accuracy.[9]Precision Benefits and Performance Advantages
The fused multiply-add (FMA) operation enhances numerical precision by performing the multiplication and addition in a single step, applying rounding only once to the final result rather than twice—once after multiplication and again after addition—as occurs with separate multiply and add instructions. This "fused" rounding preserves more significant bits from the intermediate product, reducing accumulated rounding errors, particularly in iterative computations where errors compound over multiple operations. According to IEEE 754-2008 standards, FMA guarantees a result correctly rounded as if computed with extra precision before the final rounding, making it especially valuable for algorithms sensitive to precision loss, such as those involving subtractive cancellation where small differences between large values can otherwise lead to catastrophic loss of accuracy.[9] A concrete illustration of this precision benefit appears in double-precision floating-point arithmetic. Consider computing where , , and . The exact mathematical result is 1.0. With separate multiply and add operations, the intermediate product rounds to because the unit in the last place (ulp) at is approximately , larger than 1, so adding results in 0.0. In contrast, FMA computes the product with extended precision (effectively doubling the mantissa bits before addition), preserving the +1, and after adding and a single rounding, yields 1.0—the correct result with full double-precision accuracy. This discrepancy highlights how FMA avoids the loss of up to half the precision bits that can occur in non-fused sequences.[9] Beyond precision, FMA offers significant performance advantages by fusing two operations into one instruction, reducing the total instruction count from two (multiply followed by add) to one, which lowers overhead in pipelined execution and improves code density. On modern x86 processors, FMA instructions typically exhibit a latency of 4-5 cycles for double-precision vector operations (e.g., 256-bit AVX2), compared to 8-12 cycles for dependent multiply-add sequences, while offering comparable or better throughput (e.g., 0.5-1 cycle per operation versus ~1 for separate ops). This efficiency is amplified in vector units, where dual FMA execution ports on Intel Haswell and later (or AMD Zen architectures) enable up to two fused operations per cycle, boosting overall throughput in SIMD-heavy workloads.[12] These benefits are particularly critical in applications reliant on repeated multiply-add patterns, such as linear algebra routines like matrix multiplication, where FMA accelerates the core saxpy (scalar multiply and add) operations central to algorithms like DGEMM in BLAS libraries. Similarly, polynomial evaluation benefits from FMA in Horner's method, reducing error accumulation across nested multiplications and additions; fast Fourier transforms (FFTs) leverage it for twiddle factor multiplications and accumulations in butterfly computations; and machine learning gradient computations, involving dot products and backpropagation updates, see improved speed and stability in frameworks like TensorFlow or PyTorch when using FMA-enabled hardware.[13] Despite these advantages, FMA has potential drawbacks, including slightly higher power consumption per operation due to the increased complexity of the fused arithmetic unit, which performs more computation in a single cycle compared to separate, simpler multiply and add units. Additionally, FMA provides no benefit—and may introduce issues—for non-associative expressions where the specific grouping enforced by (a × b) + c alters the computational order in ways that affect reproducibility or require separate operations to match a desired associativity pattern, as floating-point arithmetic is inherently non-associative.[9]FMA3 Instruction Set
Technical Description and Instructions
The FMA3 instruction set, introduced as part of the AVX2 extension, provides three-operand fused multiply-add operations for floating-point arithmetic in x86-64 processors. These instructions compute expressions of the form (A × B) ± C in a single operation, fusing the multiplication and addition (or subtraction) steps to minimize rounding errors and improve computational efficiency compared to separate multiply and add instructions. This fusion ensures that the intermediate product is not rounded before addition, preserving precision equivalent to a single extended-precision operation rounded once to the destination format. FMA3 supports both single-precision (32-bit) and double-precision (64-bit) floating-point data, operating on 128-bit, 256-bit, and (in AVX-512 contexts) 512-bit vector registers, enabling SIMD parallelism across multiple elements.[14] The instructions use VEX (for AVX/AVX2) or EVEX (for AVX-512) encoding prefixes to specify vector lengths, operand orders, and additional features like writemasking. In VEX encoding, a 2- or 3-byte prefix (e.g., C4H or C5H) is followed by an opcode from the 0F 38H range, a ModR/M byte for operand addressing, and optional SIB or displacement for memory access. The three operands are DEST (which is both read and written), SRC1, and SRC2, with the result overwriting DEST; this design allows in-place computation but requires careful register management to avoid data corruption. EVEX encoding extends this with a 4-byte prefix supporting 512-bit vectors, embedded writemasks (k registers), zeroing/merging behavior, broadcast from memory, and embedded rounding control bits (SAE for suppressed exceptions). All FMA3 instructions raise SIMD floating-point exceptions (#XM) for invalid operations, denormals, overflows, underflows, and inexact results, controlled by the MXCSR register or EVEX.SAE. They also generate general-protection (#GP) exceptions for unaligned memory accesses unless aligned or using appropriate flags.[14] FMA3 includes variants for different operation signs and patterns, all following the general fused multiply-add paradigm. The core instructions are prefixed with "V" to indicate vector operation and suffixed to denote precision and type (PD for packed double-precision, PS for packed single-precision, SD/SS for scalar double/single). Negated and subtract variants use "N" or "SUB" suffixes. For example, VFMADDPD computes packed double-precision (A × B) + C, where A, B, and C are vectors of four 64-bit elements in 256-bit registers. The operation is defined mathematically as: for each element , using the current rounding mode (from MXCSR or EVEX.RC). Similarly, VFMSUBPD performs (A × B) - C, and VFNMADDPD computes -((A × B) + C). Alternating add/subtract patterns are handled by VFMADDSUBPD/PS, which applies + to even-indexed elements and - to odd-indexed ones in the vector. Scalar versions like VFMADDSD operate only on the low-order element of XMM registers. In AVX2 (VEX encoding), scalar operations on XMM registers zero the upper 128 bits of the YMM register. In AVX-512 (EVEX encoding), behavior can be controlled with merging or zeroing via writemasks.[14]| Instruction | Operation | Precision | Vector Size | Key Notes |
|---|---|---|---|---|
| VFMADDPD/PS | (SRC1 × SRC2) + DEST | Double/Single (packed) | 128/256/512-bit | Standard add variant; supports memory operand for SRC2. |
| VFMADDSD/SS | (SRC1 × SRC2) + DEST (low element only) | Double/Single (scalar) | 128-bit (XMM) | Upper bits zeroed in legacy SSE; merged in VEX. |
| VFMSUBPD/PS | (SRC1 × SRC2) - DEST | Double/Single (packed) | 128/256/512-bit | Subtract variant; useful for difference computations. |
| VFMSUBSD/SS | (SRC1 × SRC2) - DEST (low element only) | Double/Single (scalar) | 128-bit (XMM) | Scalar subtract; exceptions same as packed. |
| VFMADDSUBPD/PS | Alternating (SRC1 × SRC2) + DEST (even), - DEST (odd) | Double/Single (packed) | 128/256/512-bit | For complex or paired operations; index-based signing. |
| VFNMADDPD/PS | -( (SRC1 × SRC2) + DEST ) | Double/Single (packed) | 128/256/512-bit | Negated multiply-add; inverts sign post-fusion. |
| VFNMSUBPD/PS | -( (SRC1 × SRC2) - DEST ) | Double/Single (packed) | 128/256/512-bit | Negated multiply-subtract; common in polynomial evaluation. |
| VFNMSUBSD/SS | -( (SRC1 × SRC2) - DEST ) (low element only) | Double/Single (scalar) | 128-bit (XMM) | Scalar negated subtract. |
VFMADDPD ymm0, ymm1, ymm2, ymm3, computing (ymm1 × ymm2) + ymm3 and storing in ymm0. Intrinsics in C/C++ (via <immintrin.h>) mirror this, such as _mm256_fmadd_pd(a, b, c) for VFMADDPD. Detection requires CPUID function 01H, ECX bit 12 (FMA) set to 1, with support on Intel Haswell and later, and AMD Piledriver and later architectures.[14]
Advanced variants like V4FMADDPS (introduced in Knights Landing for AVX-512) perform four sequential single-precision FMAs in a 512-bit operation, useful for matrix multiplications, but are not core to baseline FMA3. All instructions maintain IEEE 754 compliance for exceptions and rounding, with EVEX.SAE suppressing #XM for faster execution in non-critical paths. Performance characteristics vary by microarchitecture; for instance, on Intel Haswell, a 256-bit VFMADDPD has a latency of 5 cycles and throughput of 0.5 cycles per element, fusing operations to boost FLOPS rates in vectorized code.[14][12]
Supported Processors
The FMA3 instruction set, which provides three-operand fused multiply-add operations as an extension to AVX2, was first introduced in Intel's Haswell microarchitecture in 2013. It is supported across all subsequent Intel client and server processor families, including Broadwell (2014), Skylake (2015), and later generations such as Alder Lake, Raptor Lake, Meteor Lake, and Granite Rapids. Specific examples include the 4th-generation Core i7-4770K desktop processor and the Xeon E5-2600 v3 family for servers, with support verified through CPUID leaf 07H EBX bit 5 for AVX2, which encompasses FMA3. Low-end models like certain Pentium and Celeron processors from these generations may lack full AVX2/FMA3 support due to cost optimizations, but mainstream Core i3/i5/i7/i9 and Xeon lines include it universally.[15][16] AMD introduced FMA3 support starting with its Piledriver microarchitecture in 2012, alongside continued support for the earlier FMA4 variant, enabling compatibility with both three- and four-operand operations. This extends to all later AMD architectures, including Steamroller (2014), Excavator (2015), Zen (2017), and subsequent Zen 2 through Zen 5 families as of 2025. Representative processors include the FX-8350 from the Piledriver-based FX series and modern examples like the Ryzen 9 7950X (Zen 4) and EPYC 9755 (Zen 5), where FMA3 is enumerated via CPUID function 01H ECX bit 12. AMD's implementation ensures backward compatibility with x86-64 standards, enhancing floating-point performance in high-performance computing workloads.[17][18]Implementation Examples
FMA3 instructions enable efficient implementation of fused multiply-add operations in both assembly and higher-level languages via intrinsics, particularly for vectorized computations in scientific and numerical applications. These instructions, part of the AVX2 extension, operate on 128-bit (XMM) or 256-bit (YMM) registers, performing operations like with a single rounding step for improved precision and reduced latency compared to separate multiply and add instructions.[19] Implementations typically target processors supporting AVX2, such as Intel Haswell and later, where FMA3 achieves a latency of 3-5 cycles and throughput of 0.5 cycles per operation on floating-point units.[20] In C/C++, FMA3 is accessed through intrinsics defined in<immintrin.h>, allowing developers to write portable vector code without inline assembly. For example, the _mm_fmadd_ps intrinsic multiplies two packed single-precision floating-point vectors and adds a third, storing the result in a 128-bit vector. A basic usage for computing a scalar fused multiply-add on the lowest elements might appear as follows:
#include <immintrin.h>
__m128 a = _mm_set_ps1(2.0f); // Vector with all elements 2.0
__m128 b = _mm_set_ps1(3.0f); // Vector with all elements 3.0
__m128 c = _mm_set_ps1(1.0f); // Vector with all elements 1.0
__m128 result = _mm_fmadd_ps(a, b, c); // Computes a * b + c element-wise
float scalar_result = _mm_cvtss_f32(result); // Extract lowest element: 7.0
#include <immintrin.h>
__m128 a = _mm_set_ps1(2.0f); // Vector with all elements 2.0
__m128 b = _mm_set_ps1(3.0f); // Vector with all elements 3.0
__m128 c = _mm_set_ps1(1.0f); // Vector with all elements 1.0
__m128 result = _mm_fmadd_ps(a, b, c); // Computes a * b + c element-wise
float scalar_result = _mm_cvtss_f32(result); // Extract lowest element: 7.0
_mm256_fmadd_ps extends this to eight single-precision elements, ideal for matrix operations. Similar variants like _mm_fmsub_ps (for ) and _mm_fnmadd_ps (for ) support diverse arithmetic patterns. Compilation requires flags such as -mavx2 -mfma in GCC to enable code generation.[19]
Assembly-level implementations provide finer control, especially in performance-critical kernels like the DAXPY (y = a * x + y) algorithm for double-precision vectors. On Intel processors, FMA3 uses instructions like vfmadd231pd (multiply and add to accumulator), which update the destination register non-destructively. The following assembly snippet implements a loop for DAXPY on 128-bit XMM registers, processing two double-precision elements per iteration and achieving 1-2 cycles per iteration on Haswell and later microarchitectures:
section .text
extern n ; Number of elements
extern X ; Input array X
extern Y ; Input/output array Y
extern DA ; Scalar multiplier a
DAXPY:
mov rax, [n] ; Load n (assume even for simplicity)
shl rax, 3 ; Convert to bytes (8 bytes per double)
lea rsi, [X + rax] ; Point to end of X
lea rdi, [Y + rax] ; Point to end of Y
neg rax ; Negative offset for backward loop
vmovddup xmm2, [DA] ; Broadcast scalar a to xmm2
L1:
vmovapd xmm1, [rdi + rax] ; Load two doubles from Y
vfmadd231pd xmm1, xmm2, [rsi + rax] ; Y[i] = Y[i] + a * X[i]
vmovapd [rdi + rax], xmm1 ; Store back to Y
add rax, 16 ; Advance by 16 bytes (two doubles)
jl L1
ret
section .text
extern n ; Number of elements
extern X ; Input array X
extern Y ; Input/output array Y
extern DA ; Scalar multiplier a
DAXPY:
mov rax, [n] ; Load n (assume even for simplicity)
shl rax, 3 ; Convert to bytes (8 bytes per double)
lea rsi, [X + rax] ; Point to end of X
lea rdi, [Y + rax] ; Point to end of Y
neg rax ; Negative offset for backward loop
vmovddup xmm2, [DA] ; Broadcast scalar a to xmm2
L1:
vmovapd xmm1, [rdi + rax] ; Load two doubles from Y
vfmadd231pd xmm1, xmm2, [rsi + rax] ; Y[i] = Y[i] + a * X[i]
vmovapd [rdi + rax], xmm1 ; Store back to Y
add rax, 16 ; Advance by 16 bytes (two doubles)
jl L1
ret
vfmadd231pd fusing the multiply and add in one instruction. For wider 256-bit YMM registers, replace xmm with ymm and adjust strides to 32 bytes, processing four doubles per iteration. Such implementations are common in linear algebra libraries, where FMA3 reduces instruction count by up to 50% in multiply-accumulate heavy workloads compared to SSE2.[20]
Beyond basic arithmetic, FMA3 facilitates advanced patterns like alternating add/subtract for pairwise computations, using intrinsics such as _mm_fmaddsub_ps which applies across vector lanes. In practice, these are integrated into optimized routines for dot products or convolutions, where chaining multiple FMA units (e.g., two per core on Haswell) sustains high throughput. Developers must ensure runtime CPU detection (e.g., via __builtin_cpu_supports("avx2") in GCC) to fallback to non-FMA code on older hardware.[19]
FMA4 Instruction Set
Technical Description and Instructions
The FMA4 instruction set, introduced by AMD as part of the XOP extension, provides four-operand fused multiply-add operations for floating-point arithmetic in x86-64 processors. These instructions compute expressions of the form DEST = (SRC1 × SRC2) ± SRC3 in a single operation, fusing the multiplication and addition (or subtraction) steps to minimize rounding errors and improve computational efficiency compared to separate multiply and add instructions. Unlike the three-operand FMA3, FMA4 uses a dedicated destination register, allowing non-destructive updates to source operands and more flexible programming. This fusion ensures that the intermediate product is not rounded before addition, preserving precision equivalent to a single extended-precision operation rounded once to the destination format. FMA4 supports both single-precision (32-bit) and double-precision (64-bit) floating-point data, operating on 128-bit XMM and 256-bit YMM vector registers, enabling SIMD parallelism across multiple elements.[21] The instructions use XOP or VEX encoding prefixes to specify vector lengths, operand orders, and additional features. In XOP encoding, a three-byte prefix (8F RXB.mmmmm W.vvvv.L.pp) is followed by an opcode from the 0F 01 range (e.g., C9H for VFMADDPD), a ModR/M byte for operand addressing, and optional SIB or displacement for memory access. The four operands are DEST (written), SRC1, SRC2, and SRC3 (read), with the result stored in DEST without overwriting sources; this design supports in-place accumulation without temporary registers. VEX encoding (C4/C5 prefixes) is also supported for compatibility. All FMA4 instructions raise SIMD floating-point exceptions (#XF) for invalid operations, denormals, overflows, underflows, divides-by-zero, and inexact results, controlled by the MXCSR register. They also generate general-protection (#GP) exceptions for unaligned memory accesses unless aligned or using appropriate flags.[21] FMA4 includes variants for different operation signs and patterns, all following the general fused multiply-add paradigm with four operands. The core instructions are prefixed with "V" to indicate vector operation and suffixed to denote precision and type (PD for packed double-precision, PS for packed single-precision, SD/SS for scalar double/single). Negated and subtract variants use "N" or "SUB" suffixes. For example, VFMADDPD computes packed double-precision DEST = (SRC1 × SRC2) + SRC3, where SRC1, SRC2, and SRC3 are vectors of four 64-bit elements in 256-bit registers. The operation is defined mathematically as: for each element , using the current rounding mode (from MXCSR). Similarly, VFMSUBPD performs DEST = (SRC1 × SRC2) - SRC3, and VFNMADDPD computes DEST = -((SRC1 × SRC2) + SRC3). Alternating add/subtract patterns are handled by VFMADDSUBPD/PS, which applies + to even-indexed elements and - to odd-indexed ones in the vector. Scalar versions like VFMADDSD operate only on the low-order element of XMM registers, zeroing upper bits.[21]| Instruction | Operation | Precision | Vector Size | Key Notes |
|---|---|---|---|---|
| VFMADDPD/PS | DEST = (SRC1 × SRC2) + SRC3 | Double/Single (packed) | 128/256-bit | Standard add variant; supports memory operand for SRC3. |
| VFMADDSD/SS | DEST = (SRC1 × SRC2) + SRC3 (low element only) | Double/Single (scalar) | 128-bit (XMM) | Upper bits zeroed. |
| VFMSUBPD/PS | DEST = (SRC1 × SRC2) - SRC3 | Double/Single (packed) | 128/256-bit | Subtract variant; useful for difference computations. |
| VFMSUBSD/SS | DEST = (SRC1 × SRC2) - SRC3 (low element only) | Double/Single (scalar) | 128-bit (XMM) | Scalar subtract; exceptions same as packed. |
| VFMADDSUBPD/PS | DEST = alternating (SRC1 × SRC2) + SRC3 (even), - SRC3 (odd) | Double/Single (packed) | 128/256-bit | For complex or paired operations; index-based signing. |
| VFNMADDPD/PS | DEST = -((SRC1 × SRC2) + SRC3) | Double/Single (packed) | 128/256-bit | Negated multiply-add; inverts sign post-fusion. |
| VFNMSUBPD/PS | DEST = -((SRC1 × SRC2) - SRC3) | Double/Single (packed) | 128/256-bit | Negated multiply-subtract; common in polynomial evaluation. |
| VFNMSUBSD/SS | DEST = -((SRC1 × SRC2) - SRC3) (low element only) | Double/Single (scalar) | 128-bit (XMM) | Scalar negated subtract. |
| VFMSUBADDPD/PS | DEST = alternating (SRC1 × SRC2) - SRC3 (even), + SRC3 (odd) | Double/Single (packed) | 128/256-bit | Inverse alternating pattern. |
vfmaddpd ymm0, ymm1, ymm2, ymm3, computing (ymm1 × ymm2) + ymm3 and storing in ymm0. Intrinsics in C/C++ (via fma4intrin.h) mirror this, such as _mm256_macc_pd(a, b, c) for VFMADDPD. Detection requires CPUID function 8000_0001H, ECX bit 16 (FMA4) set to 1, with support on AMD Bulldozer and later architectures.[21][17]
Advanced integer variants like VPMACSDD perform fused operations on packed integers but are not core to floating-point FMA4. All instructions maintain IEEE 754 compliance for exceptions and rounding. Performance characteristics vary by microarchitecture; for instance, on AMD Bulldozer, FMA4 operations have low latency, fusing to boost FLOPS in vectorized code.[21]
Supported Processors
The FMA4 instruction set, providing four-operand fused multiply-add operations as an extension to XOP, was first introduced in AMD's Bulldozer microarchitecture in 2011. It is supported in subsequent architectures including Piledriver (2012), Steamroller (2014), and Excavator (2015). Starting with Zen (2017) and later generations such as Zen 2 through Zen 5 (as of 2025), FMA4 is implemented in hardware but not exposed via CPUID for software detection, requiring manual enabling or OS-specific handling for use. Representative processors include the FX-8150 from the Bulldozer-based FX series, the FX-8350 (Piledriver), APU models like the A10-7870K (Kaveri/Exacavator), and modern examples like the Ryzen 9 7950X (Zen 4) and EPYC 9755 (Zen 5), where hardware support exists despite non-advertisement. FMA4 is enumerated via CPUID function 8000_0001H ECX bit 16 on supported pre-Zen architectures, enhancing floating-point performance in high-performance computing workloads. Intel processors do not support FMA4.[21][17][22]Implementation Examples
FMA4 instructions enable efficient implementation of fused multiply-add operations in both assembly and higher-level languages via intrinsics, particularly for vectorized computations in scientific and numerical applications. These instructions, part of the XOP extension, operate on 128-bit (XMM) or 256-bit (YMM) registers, performing operations like with a single rounding step for improved precision and reduced latency compared to separate multiply and add instructions.[17] Implementations typically target processors supporting XOP/FMA4, such as AMD Bulldozer and later, where FMA4 achieves low latency and high throughput on floating-point units. In C/C++, FMA4 is accessed through intrinsics defined in <fma4intrin.h>, allowing developers to write portable vector code without inline assembly. For example, the_mm_macc_ps intrinsic multiplies two packed single-precision floating-point vectors and adds a third, storing the result in a destination vector. A basic usage for computing a scalar fused multiply-add on the lowest elements might appear as follows:
#include <fma4intrin.h>
__m128 a = _mm_set_ps1(2.0f); // Vector with all elements 2.0
__m128 b = _mm_set_ps1(3.0f); // Vector with all elements 3.0
__m128 c = _mm_set_ps1(1.0f); // Vector with all elements 1.0
__m128 dest = _mm_setzero_ps(); // Initialize destination
__m128 result = _mm_macc_ps(a, b, dest, c); // Computes dest = a * b + c element-wise
float scalar_result = _mm_cvtss_f32(result); // Extract lowest element: 7.0
#include <fma4intrin.h>
__m128 a = _mm_set_ps1(2.0f); // Vector with all elements 2.0
__m128 b = _mm_set_ps1(3.0f); // Vector with all elements 3.0
__m128 c = _mm_set_ps1(1.0f); // Vector with all elements 1.0
__m128 dest = _mm_setzero_ps(); // Initialize destination
__m128 result = _mm_macc_ps(a, b, dest, c); // Computes dest = a * b + c element-wise
float scalar_result = _mm_cvtss_f32(result); // Extract lowest element: 7.0
_mm256_macc_ps extends this to eight single-precision elements, ideal for matrix operations. Similar variants like _mm_msub_ps (for ) and _mm_nmacc_ps (for ) support diverse arithmetic patterns. Compilation requires flags such as -mxop -mfma4 in GCC to enable code generation.[17]
Assembly-level implementations provide finer control, especially in performance-critical kernels like the DAXPY (y = a * x + y) algorithm for double-precision vectors. On AMD processors, FMA4 uses instructions like vfmadd231pd (multiply and add to accumulator, with operand permutation) or vfnmadd231pd (fused negate-multiply-add). The following assembly snippet implements a loop for DAXPY on 128-bit XMM registers, processing two double-precision elements per iteration:
section .text
extern n ; Number of elements
extern X ; Input [array](/page/Array) X
extern Y ; Input/output [array](/page/Array) Y
extern DA ; Scalar multiplier a
DAXPY:
mov rax, [n] ; Load n (assume even for simplicity)
shl rax, 3 ; Convert to bytes (8 bytes per double)
lea rsi, [X + rax] ; Point to end of X
lea rdi, [Y + rax] ; Point to end of Y
neg rax ; Negative offset for backward loop
vmovddup xmm2, [DA] ; Broadcast scalar a to xmm2
L1:
vmovapd xmm0, [rdi + rax] ; Load two doubles from Y to dest
vmovapd xmm1, [rsi + rax] ; Load two doubles from X to src1
vfmadd231pd xmm0, xmm1, xmm2 ; Y[i] = Y[i] + a * X[i]
vmovapd [rdi + rax], xmm0 ; Store back to Y
add rax, 16 ; Advance by 16 bytes (two doubles)
jl L1
ret
section .text
extern n ; Number of elements
extern X ; Input [array](/page/Array) X
extern Y ; Input/output [array](/page/Array) Y
extern DA ; Scalar multiplier a
DAXPY:
mov rax, [n] ; Load n (assume even for simplicity)
shl rax, 3 ; Convert to bytes (8 bytes per double)
lea rsi, [X + rax] ; Point to end of X
lea rdi, [Y + rax] ; Point to end of Y
neg rax ; Negative offset for backward loop
vmovddup xmm2, [DA] ; Broadcast scalar a to xmm2
L1:
vmovapd xmm0, [rdi + rax] ; Load two doubles from Y to dest
vmovapd xmm1, [rsi + rax] ; Load two doubles from X to src1
vfmadd231pd xmm0, xmm1, xmm2 ; Y[i] = Y[i] + a * X[i]
vmovapd [rdi + rax], xmm0 ; Store back to Y
add rax, 16 ; Advance by 16 bytes (two doubles)
jl L1
ret
vfmadd231pd fusing the multiply and add in one instruction using the four-operand model. For wider 256-bit YMM registers, replace xmm with ymm and adjust strides to 32 bytes, processing four doubles per iteration. Such implementations are common in linear algebra libraries, where FMA4 reduces instruction count in multiply-accumulate heavy workloads compared to SSE2.[21]
Beyond basic arithmetic, FMA4 facilitates advanced patterns like alternating add/subtract for pairwise computations, using intrinsics such as _mm_maddsub_ps which applies across vector lanes. In practice, these are integrated into optimized routines for dot products or convolutions, sustaining high throughput on AMD FP units. Developers must ensure runtime CPU detection (e.g., via CPUID checks) or manual enabling on Zen and later for fallback to non-FMA code on unsupported hardware.[17][22]
Historical Development
Origins and Early Proposals
The conceptual foundations of the fused multiply-add (FMA) operation emerged in the mid-20th century amid efforts to optimize floating-point arithmetic for scientific computing. During the IBM Stretch project in the 1950s, designers proposed a "cumulative multiply" instruction that fused multiplication and addition into a single operation, expanding the traditional three-register datapath with a dedicated "factor" register to enable efficient matrix multiplications and other iterative calculations. This early idea, formalized by 1956 through contributions from engineers like Gene Amdahl, aimed to reduce instruction counts in high-performance scientific applications, though the Stretch system was delivered in 1961 after significant delays.[23] By the late 1980s, renewed interest in fused operations arose from the need to minimize rounding errors in floating-point computations, particularly as processor designs evolved toward reduced instruction set computing (RISC). The first commercial hardware implementation of FMA debuted in 1990 with IBM's POWER1 processor (also known as RS/6000), where it was integrated into a second-generation RISC floating-point unit capable of executing the operation—a × b + c—with a single final rounding step, improving both speed and accuracy for common algorithms like polynomial evaluation. This design, which supported IEEE 754-compliant single- and double-precision formats, marked a pivotal shift by demonstrating FMA's potential to execute up to twice as many floating-point operations per cycle compared to separate multiply and add instructions. Hewlett-Packard followed with experimental support in its PA-RISC architecture during the 1990s, notably in the PA-8000 processor released in 1996, which featured two fused multiply-accumulate (FMAC) units for handling floating-point and integer multiply instructions in a superscalar pipeline.[24] Standardization efforts gained momentum in the 1990s through revisions to floating-point standards, emphasizing operations that preserved accuracy by limiting intermediate roundings. Discussions within the IEEE 754 revision committee, which began in earnest after the 1985 standard, highlighted FMA's role in reducing error propagation, leading to its formal inclusion in IEEE 754-2008 as the fusedMultiplyAdd operation, defined to compute (x × y) + z with unbounded intermediate precision and a single rounding to the destination format.[2] Early adopters beyond IBM and HP included the Intel Itanium architecture (2001) and MIPS64, extending FMA to EPIC and other RISC designs. The entry of FMA into the x86 ecosystem occurred in the late 2000s, spurred by competitive proposals: AMD announced the SSE5 extension in August 2007, incorporating FMA4 instructions with 4-operand syntax to accelerate multimedia and high-performance computing workloads, while Intel responded in early 2008 with a 4-operand FMA proposal as part of its Advanced Vector Extensions (AVX), enabling more flexible operand handling without overwriting inputs.[25][26]Evolution and Industry Adoption
The development of FMA instructions during the 2010s reflected a pivotal shift in x86 architecture, as Intel and AMD navigated competing extensions before aligning on a unified approach. Initially, Intel considered SSE5 extensions in 2008, which included early FMA concepts, but canceled these in favor of the AVX framework to streamline vector processing. This pivot culminated in 2013 with the introduction of FMA3 alongside AVX2 in the Haswell microarchitecture, providing hardware support for three-operand fused multiply-add operations to boost floating-point throughput in scientific and engineering applications.[27][28][29] AMD pursued a parallel path by announcing FMA4 in 2010 as part of its Bulldozer microarchitecture, aiming to enhance SIMD capabilities with four-operand FMA variants integrated into SSE5. Despite its potential for higher flexibility in certain computations, FMA4 experienced low industry adoption due to compatibility challenges, primarily because Intel did not implement it, resulting in limited software optimization and ecosystem fragmentation.[30] Industry convergence accelerated when AMD first implemented FMA3 in 2012 with the Piledriver microarchitecture (e.g., Trinity APUs), bridging the gap with Intel's offerings and promoting cross-vendor compatibility. This trend solidified in 2017 with AMD's Zen microarchitecture, which standardized FMA3 support across its processor lineup, enabling seamless integration in shared software bases. The broader impact extended to software ecosystems, with FMA inclusion in OpenMP 4.0 (2013) facilitating vectorized parallel programming, CUDA 6.0 (2014) enabling GPU-accelerated FMA for heterogeneous computing, and ARMv8-A (2013) incorporating FMA to expand its utility in diverse architectures.[31][32][33][34] From a 2025 perspective, FMA serves as a foundational element in AI and high-performance computing pipelines, where its precision-preserving operations underpin matrix multiplications and neural network training. Extensions in Intel's AVX-512 further amplify FMA capabilities with 512-bit vectors for massive parallelism, while AMD's Zen 5 microarchitecture refines FMA execution for energy-efficient scaling in data centers and edge devices.[35]Software Support
Compiler and Intrinsic Support
Compilers provide support for the Fused Multiply-Add (FMA) instruction set through command-line flags that enable instruction generation and optimization passes that automatically insert FMA operations where beneficial. In the GNU Compiler Collection (GCC), the-mfma flag explicitly enables the use of FMA instructions, targeting processors that support the FMA3 extension, such as Intel Haswell and later architectures.[36] This flag allows GCC to generate FMA instructions during code optimization, particularly when combined with architecture-specific options like -march=haswell. Additionally, GCC can automatically contract floating-point expressions into FMA operations under certain optimization levels, such as with -ffp-contract=fast or -ffast-math, which permit reassociation for performance gains while potentially altering strict IEEE 754 compliance.[37]
The Clang compiler, part of the LLVM project, offers compatible support for FMA through flags mirroring GCC's, including -mfma to enable FMA3 instructions on supported targets.[38] Like GCC, Clang generates FMA operations automatically in optimized code when targeting FMA-capable architectures (e.g., via -march=native on compatible hardware) and with floating-point contraction enabled via -ffp-contract=on or -ffast-math. This integration ensures portability across GCC and Clang toolchains for x86-64 environments. For Intel-specific compilation, the Intel C++ Compiler (ICC, now part of oneAPI DPC++/C++ Compiler) supports FMA via -xCORE-AVX2 or higher, which includes FMA3, and provides aggressive auto-vectorization that frequently inserts FMA for multiply-add patterns in loops.[39]
Microsoft Visual C++ (MSVC) enables FMA support through the /arch:AVX2 option, which activates FMA3 instructions alongside 256-bit AVX2 vector operations, available since Visual Studio 2013 Update 2.[40] MSVC's optimizer can generate FMA instructions automatically for expressions like a * b + c under /O2 or higher, though this behavior may be influenced by floating-point model settings such as /fp:fast, which allows contraction similar to -ffast-math in GCC/Clang. Under the strict /fp:precise model, MSVC historically avoided FMA to preserve exact IEEE semantics, though recent versions (e.g., Visual Studio 2019) may insert them selectively. Starting with Visual Studio 2022, the /fp:contract option provides explicit control over contraction generation under /fp:precise, defaulting to allowing contractions unless set to off.[41][42]
Intrinsic functions provide low-level access to FMA instructions, allowing developers to explicitly invoke them without inline assembly. For FMA3, the Intel Intrinsics Guide lists a comprehensive set of functions in <immintrin.h>, such as _mm_fmadd_ps for single-precision packed floats (performing a * b + c on 128-bit vectors) and _mm256_fmadd_pd for double-precision 256-bit vectors.[19] These are supported across GCC, Clang, ICC, and MSVC when the appropriate headers are included and target flags are set, enabling portable SIMD code for FMA3 operations. GCC extends this with built-in functions like __builtin_ia32_vfmaddpd for FMA3 variants.[43]
For the AMD-specific FMA4 extension, support is more limited but available in GCC via the -mfma4 flag, which enables dedicated built-in functions such as __builtin_ia32_vfmaddps for 128-bit and 256-bit vectors, generating FMA4 instructions on compatible hardware like Bulldozer and Piledriver processors.[43] AMD provides intrinsics in fma4intrin.h, including _mm_madd_ps and variants for multiply-add/subtract, as documented in their instruction set reference. Clang supports FMA4 intrinsics through LLVM's backend, though adoption is rare due to FMA4's deprecation in favor of FMA3 in modern AMD architectures like Zen. MSVC does not natively expose distinct FMA4 intrinsics, relying instead on general AVX headers that map to FMA3 on supported targets. Runtime detection of FMA support, such as via __builtin_cpu_supports("fma") in GCC or CPUID checks, is recommended to ensure portability across FMA3 and FMA4 hardware.[43]
Support for FMA extends beyond x86 to other architectures, such as ARM. GCC and Clang provide FMA intrinsics for ARMv8-A NEON SIMD units via flags like -mfma (though primarily for AArch64 with SVE or NEON extensions), generating fused operations in optimized code. ARM's intrinsics, documented in the ACLE (ARM C Language Extensions), include functions like vfmaddq_f32 for quad-word single-precision vectors.[4]
Assembler and Low-Level Usage
The Fused Multiply-Add (FMA) instructions can be directly invoked in x86 assembly language using specific mnemonics, enabling low-level programmers to perform high-precision floating-point operations without intermediate rounding. In assembly code, FMA instructions are typically written with operands specifying registers (e.g., XMM, YMM, or ZMM) or memory locations, and they require appropriate prefixes like VEX or EVEX for vector extensions. Support must be verified at runtime using CPUID function 01H with ECX bit 12 for FMA3 (Intel standard) or extended function 8000_0001H with ECX bit 16 for FMA4 (AMD variant).[44][21] FMA3 instructions, part of Intel's AVX, AVX2, and AVX-512 extensions, use a three-operand format where the destination register also serves as one source, and the numeric suffix (132, 213, or 231) indicates the computation order: for example, VFMADD132PD computes dest = (dest * src2) + src3. These instructions support packed single-precision (PS), packed double-precision (PD), scalar single-precision (SS), and scalar double-precision (SD) operations, with vector lengths of 128, 256, or 512 bits depending on the register size. A basic assembly example for packed double-precision fused multiply-add using YMM registers is:vfmadd132pd ymm0, ymm1, ymm2 ; ymm0 = (ymm0 * ymm1) + ymm2
vfmadd132pd ymm0, ymm1, ymm2 ; ymm0 = (ymm0 * ymm1) + ymm2
vfmadd132pd zmm0 {k1}{z}, zmm1, zmm2 ; Conditional fused multiply-add with zeroing
vfmadd132pd zmm0 {k1}{z}, zmm1, zmm2 ; Conditional fused multiply-add with zeroing
vfmaddps xmm0, xmm1, xmm2, xmm3 ; xmm0 = (xmm1 * xmm2) + xmm3
vfmaddps xmm0, xmm1, xmm2, xmm3 ; xmm0 = (xmm1 * xmm2) + xmm3
Library and Framework Integration
The Fused Multiply-Add (FMA) instruction set is integrated into various mathematical libraries, particularly those implementing the Basic Linear Algebra Subprograms (BLAS) and LAPACK standards, to enhance floating-point performance in vector and matrix operations. OpenBLAS, an open-source BLAS library, leverages FMA instructions on supported architectures such as Intel Haswell processors with AVX2, enabling fused operations in Level-2 and Level-3 BLAS routines for improved throughput in multiply-accumulate tasks common in linear algebra. Similarly, Intel's oneAPI Math Kernel Library (oneMKL) utilizes FMA for optimized vector scaling and addition, such as in thecblas_daxpy routine, where it performs a * x + y with a single rounding step to reduce error accumulation when the target CPU supports the instructions. ATLAS, another auto-tuned BLAS implementation, detects FMA availability during code generation and incorporates it into kernel optimizations for dense linear algebra, though its usage depends on the host architecture's capabilities.
Higher-level scientific computing libraries build on these BLAS backends to indirectly benefit from FMA acceleration. NumPy, a foundational Python library for numerical computing, employs SIMD optimizations including FMA3 in its universal function (ufunc) loops, such as for dot products and element-wise multiplications, with runtime CPU dispatch to select FMA paths on compatible x86_64 systems. This integration, outlined in NumPy Enhancement Proposal 38, ensures portable performance gains while maintaining numerical stability within 1-3 units in the last place (ULPs). SciPy, extending NumPy for advanced scientific routines, inherits FMA support through its reliance on optimized BLAS implementations like OpenBLAS or oneMKL, particularly in sparse linear algebra and optimization modules where fused operations reduce computational overhead.
In machine learning frameworks, FMA integration focuses on accelerating tensor operations and neural network training. TensorFlow can be compiled with compiler flags like -mfma to enable FMA instructions in performance-critical paths, such as matrix multiplications via its Eigen backend or oneDNN primitives, yielding performance improvements in CPU inference on supported hardware. PyTorch similarly exploits FMA through its ATen library and optional Intel Extension for PyTorch (IPEX), which uses oneDNN for fused multiply-add in bfloat16 (BF16) accumulations on Intel Xeon processors, enhancing deep learning workloads with minimal precision loss. Both frameworks warn users if the binary lacks FMA compilation when the CPU supports it, recommending source builds for optimal utilization.References
- https://en.wikichip.org/wiki/amd/microarchitectures/zen