
Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
| JavaScript Object Notation | |
|---|---|
The JSON logo is a Möbius strip | |
| Filename extension |
.json |
| Internet media type |
application/json |
| Type code | TEXT |
| Uniform Type Identifier (UTI) | public.json |
| Type of format | Data interchange |
| Extended from | JavaScript |
| Standard | STD 90 (RFC 8259), ECMA-404, ISO/IEC 21778:2017 |
| Open format? | Yes |
| Website | json |
JSON (JavaScript Object Notation, pronounced /ˈdʒeɪsən/ or /ˈdʒeɪˌsɒn/) is an open standard file format and data interchange format that uses human-readable text to store and transmit data objects consisting of name–value pairs and arrays (or other serializable values). It is a commonly used data format with diverse uses in electronic data interchange, including that of web applications with servers.
JSON is a language-independent data format. It was derived from JavaScript, but many modern programming languages include code to generate and parse JSON-format data. JSON filenames use the extension .json.
Douglas Crockford originally specified the JSON format in the early 2000s.[1] He and Chip Morningstar sent the first JSON message in April 2001.
Naming and pronunciation
[edit]The 2017 international standard (ECMA-404 and ISO/IEC 21778:2017) specifies that "JSON" is "pronounced /ˈdʒeɪ.sən/, as in 'Jason and The Argonauts'".[2][3] The first (2013) edition of ECMA-404 did not address the pronunciation.[4] Crockford said in 2011, "There's a lot of argument about how you pronounce that, but I strictly don't care."[1] /ˈdʒeɪˌsɒn/ is another common pronunciation.[5]
Standards
[edit]After RFC 4627 had been available as its "informational" specification since 2006, JSON was first standardized in 2013, as ECMA-404.[4] RFC 8259, published in 2017, is the current version of the Internet Standard STD 90, and it remains consistent with ECMA-404.[6] That same year, JSON was also standardized as ISO/IEC 21778:2017.[2] The ECMA and ISO/IEC standards describe only the allowed syntax, whereas the RFC covers some security and interoperability considerations.[7]
History
[edit]
JSON grew out of a need for a real-time server-to-browser session communication protocol without using browser plugins such as Flash or Java applets, the dominant methods used in the early 2000s.[8]
Crockford first specified and popularized the JSON format.[1] The acronym originated at State Software, a company cofounded by Crockford and others in March 2001. The cofounders agreed to build a system that used standard browser capabilities and provided an abstraction layer for Web developers to create stateful Web applications that had a persistent duplex connection to a Web server by holding two Hypertext Transfer Protocol (HTTP) connections open and recycling them before standard browser time-outs if no further data were exchanged. The cofounders had a round-table discussion and voted on whether to call the data format JSML (JavaScript Markup Language) or JSON (JavaScript Object Notation), as well as under what license type to make it available. The JSON.org[9] website was launched in 2001. In December 2005, Yahoo! began offering some of its Web services in JSON.[10]
A precursor to the JSON libraries was used in a children's digital asset trading game project named Cartoon Orbit at Communities.com [citation needed] which used a browser side plug-in with a proprietary messaging format to manipulate DHTML elements. Upon discovery of early Ajax capabilities, digiGroups, Noosh, and others used frames to pass information into the user browsers' visual field without refreshing a Web application's visual context, realizing real-time rich Web applications using only the standard HTTP, HTML, and JavaScript capabilities of Netscape 4.0.5+ and Internet Explorer 5+. Crockford then found that JavaScript could be used as an object-based messaging format for such a system. The system was sold to Sun Microsystems, Amazon.com, and EDS.
JSON was based on a subset of the JavaScript scripting language (specifically, Standard ECMA-262 3rd Edition—December 1999[11]) and is commonly used with JavaScript, but it is a language-independent data format. Code for parsing and generating JSON data is readily available in many programming languages. JSON's website lists JSON libraries by language.
In October 2013, Ecma International published the first edition of its JSON standard ECMA-404.[4] That same year, RFC 7158 used ECMA-404 as a reference. In 2014, RFC 7159 became the main reference for JSON's Internet uses, superseding RFC 4627 and RFC 7158 (but preserving ECMA-262 and ECMA-404 as main references). In November 2017, ISO/IEC JTC 1/SC 22 published ISO/IEC 21778:2017[2] as an international standard. On December 13, 2017, the Internet Engineering Task Force obsoleted RFC 7159 when it published RFC 8259, which is the current version of the Internet Standard STD 90.[12][13]
Crockford added a clause to the JSON license stating, "The Software shall be used for Good, not Evil", in order to open-source the JSON libraries while mocking corporate lawyers and those who are overly pedantic. On the other hand, this clause led to license compatibility problems of the JSON license with other open-source licenses since open-source software and free software usually imply no restrictions on the purpose of use.[14]
Syntax
[edit]The following example shows a possible JSON representation describing a person.
{
"first_name": "John",
"last_name": "Smith",
"is_alive": true,
"age": 27,
"address": {
"street_address": "21 2nd Street",
"city": "New York",
"state": "NY",
"postal_code": "10021-3100"
},
"phone_numbers": [
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "office",
"number": "646 555-4567"
}
],
"children": [
"Catherine",
"Thomas",
"Trevor"
],
"spouse": null
}
Character encoding
[edit]Although Crockford originally asserted that JSON is a strict subset of JavaScript and ECMAScript,[15] his specification actually allows valid JSON documents that are not valid JavaScript; JSON allows the Unicode line terminators U+2028 LINE SEPARATOR and U+2029 PARAGRAPH SEPARATOR to appear unescaped in quoted strings, while ECMAScript 2018 and older do not.[16][17] This is a consequence of JSON disallowing only "control characters". For maximum portability, these characters are backslash-escaped.
JSON exchange in an open ecosystem must be encoded in UTF-8.[6] The encoding supports the full Unicode character set, including those characters outside the Basic Multilingual Plane (U+0000 to U+FFFF). However, if escaped, those characters must be written using UTF-16 surrogate pairs. For example, to include the Emoji character U+1F610 😐 NEUTRAL FACE in JSON:
{ "face": "😐" }
// or
{ "face": "\uD83D\uDE10" }
JSON became a strict subset of ECMAScript as of the language's 2019 revision.[17][18]
Data types
[edit]JSON's basic data types are:
- Number: a signed decimal number that may contain a fractional part and may use exponential E notation but cannot include non-numbers such as NaN. The format makes no distinction between integer and floating-point. JavaScript uses IEEE-754 double-precision floating-point format for all its numeric values (later also supporting BigInt[19]), but other languages implementing JSON may encode numbers differently.
- String: a sequence of zero or more Unicode characters. Strings are delimited with double quotation marks and support a backslash escaping syntax.
- Boolean: either of the values
trueorfalse - Array: an ordered list of zero or more elements, each of which may be of any type. Arrays use square bracket notation with comma-separated elements.
- Object: a collection of name–value pairs where the names (also called keys) are strings. The current ECMA standard states, "The JSON syntax does not impose any restrictions on the strings used as names, does not require that name strings be unique, and does not assign any significance to the ordering of name/value pairs."[20] Objects are delimited with curly brackets and use commas to separate each pair, while within each pair, the colon ":" character separates the key or name from its value.
null: an empty value, using the wordnull
Whitespace is allowed and ignored around or between syntactic elements (values and punctuation, but not within a string value). Four specific characters are considered whitespace for this purpose: space, horizontal tab, line feed, and carriage return. In particular, the byte order mark must not be generated by a conforming implementation (though it may be accepted when parsing JSON). JSON does not provide syntax for comments.[21]
Early versions of JSON (such as specified by RFC 4627) required that a valid JSON text must consist of only an object or an array type, which could contain other types within them. This restriction was dropped in RFC 7158, where a JSON text was redefined as any serialized value.
Numbers in JSON are agnostic with regard to their representation within programming languages. While this allows for numbers of arbitrary precision to be serialized, it may lead to portability issues. For example, since no differentiation is made between integer and floating-point values, some implementations may treat 42, 42.0, and 4.2E+1 as the same number, while others may not. The JSON standard makes no requirements regarding implementation details such as overflow, underflow, loss of precision, rounding, or signed zeros, but it does recommend expecting no more than IEEE 754 binary64 precision for "good interoperability". There is no inherent precision loss in serializing a machine-level binary representation of a floating-point number (like binary64) into a human-readable decimal representation (like numbers in JSON) and back; there exist published algorithms to do this conversion exactly and optimally.[22]
Comments were intentionally excluded from JSON. In 2012, Douglas Crockford described his design decision thus: "I removed comments from JSON because I saw people were using them to hold parsing directives, a practice which would have destroyed interoperability."[21]
JSON disallows "trailing commas", a comma after the last value inside a data structure.[23] Trailing commas are a common feature of JSON derivatives to improve ease of use.[24]
Interoperability
[edit]RFC 8259 describes certain aspects of JSON syntax that, while legal per the specifications, can cause interoperability problems.
- Certain JSON implementations only accept JSON texts representing an object or an array. For interoperability, applications interchanging JSON should transmit messages that are objects or arrays.
- The specifications allow JSON objects that contain multiple members with the same name. The behavior of implementations processing objects with duplicate names is unpredictable. For interoperability, applications should avoid duplicate names when transmitting JSON objects.
- The specifications specifically say that the order of members in JSON objects is not significant. For interoperability, applications should avoid assigning meaning to member ordering even if the parsing software makes that ordering visible.
- While the specifications place no limits on the magnitude or precision of JSON number literals, the widely used JavaScript implementation stores them as IEEE754 "binary64" quantities. For interoperability, applications should avoid transmitting numbers that cannot be represented in this way, for example, 1E400 or 3.141592653589793238462643383279.
- While the specifications do not constrain the character encoding of the Unicode characters in a JSON text, the vast majority of implementations assume UTF-8 encoding; for interoperability, applications should always and only encode JSON messages in UTF-8.
- The specifications do not forbid transmitting byte sequences that incorrectly represent Unicode characters. For interoperability, applications should transmit messages containing no such byte sequences.
- The specification does not constrain how applications go about comparing Unicode strings. For interoperability, applications should always perform such comparisons code unit by code unit.
In 2015, the IETF published RFC 7493, describing the "I-JSON Message Format", a restricted profile of JSON that constrains the syntax and processing of JSON to avoid, as much as possible, these interoperability issues.
Semantics
[edit]While JSON provides a syntactic framework for data interchange, unambiguous data interchange also requires agreement between producer and consumer on the semantics of specific use of the JSON syntax.[25] One example of where such an agreement is necessary is the serialization of data types that are not part of the JSON standard, for example, dates and regular expressions.
Metadata and schema
[edit]The official MIME type for JSON text is application/json,[26] and most modern implementations have adopted this. Legacy MIME types include text/json, text/x-json, and text/javascript.[27] The standard filename extension is .json.[28]
JSON Schema specifies a JSON-based format to define the structure of JSON data for validation, documentation, and interaction control. It provides a contract for the JSON data required by a given application and how that data can be modified.[29] JSON Schema is based on the concepts from XML Schema (XSD) but is JSON-based. As in XSD, the same serialization/deserialization tools can be used both for the schema and data, and it is self-describing. It is specified in an Internet Draft at the IETF, with the latest version as of 2024 being "Draft 2020-12".[30] There are several validators available for different programming languages,[31] each with varying levels of conformance.
The JSON standard does not support object references, but an IETF draft standard for JSON-based object references exists.[32]
Uses
[edit]JSON-RPC is a remote procedure call (RPC) protocol built on JSON, as a replacement for XML-RPC or SOAP. It is a simple protocol that defines only a handful of data types and commands. JSON-RPC lets a system send notifications (information to the server that does not require a response) and multiple calls to the server that can be answered out of order.
Asynchronous JavaScript and JSON (or AJAJ) refers to the same dynamic web page methodology as Ajax, but instead of XML, JSON is the data format. AJAJ is a web development technique that provides for the ability of a web page to request new data after it has loaded into the web browser. Typically, it renders new data from the server in response to user actions on that web page. For example, what the user types into a search box, client-side code then sends to the server, which immediately responds with a drop-down list of matching database items.
JSON has seen ad hoc usage as a configuration language. However, it does not support comments. In 2012, Douglas Crockford, JSON creator, had this to say about comments in JSON when used as a configuration language: "I know that the lack of comments makes some people sad, but it shouldn't. Suppose you are using JSON to keep configuration files, which you would like to annotate. Go ahead and insert all the comments you like. Then pipe it through JSMin[33] before handing it to your JSON parser."[21]
MongoDB uses JSON-like data for its document-oriented database.
Some relational databases have added support for native JSON data types, such as JSONB in PostgreSQL[34] and JSON in MySQL.[35] This allows developers to insert JSON data directly without having to convert it to another format.
Safety
[edit]JSON being a subset of JavaScript can lead to the misconception that it is safe to pass JSON texts to the JavaScript eval() function. This is not safe, due to certain valid JSON texts, specifically those containing U+2028 LINE SEPARATOR or U+2029 PARAGRAPH SEPARATOR, not being valid JavaScript code until JavaScript specifications were updated in 2019, and so older engines may not support it.[36] To avoid the many pitfalls caused by executing arbitrary code from the Internet, a new function, JSON.parse(), was first added to the fifth edition of ECMAScript,[37] which as of 2017 is supported by all major browsers. For non-supported browsers, an API-compatible JavaScript library is provided by Douglas Crockford.[38] In addition, the TC39 proposal "Subsume JSON" made ECMAScript a strict JSON superset as of the language's 2019 revision.[17][18] Various JSON parser implementations have suffered from denial-of-service attack and mass assignment vulnerability.[39][40]
Alternatives
[edit]JSON is promoted as a low-overhead alternative to XML as both of these formats have widespread support for creation, reading, and decoding in the real-world situations where they are commonly used.[41] Apart from XML, examples could include CSV and supersets of JSON. Google Protocol Buffers can fill this role, although it is not a data interchange language. CBOR has a superset of the JSON data types, but it is not text-based. Ion is also a superset of JSON, with a wider range of primary types, annotations, comments, and allowing trailing commas.[42]
XML
[edit]XML has been used to describe structured data and to serialize objects. Various XML-based protocols exist to represent the same kind of data structures as JSON for the same kind of data interchange purposes. Data can be encoded in XML in several ways. The most expansive form using tag pairs results in a much larger (in character count) representation than JSON, but if data is stored in attributes and short tag form where the closing tag is replaced with />, the representation is often about the same size as JSON or just a little larger. However, an XML attribute can only have a single value and each attribute can appear at most once on each element.
XML separates data from metadata (via the use of elements and attributes), while JSON does not have such a concept.
Another key difference is the addressing of values. JSON has objects with a simple key-to-value mapping, whereas in XML addressing happens on nodes, each of which receives a unique ID via the XML processor. Additionally, the XML standard defines a common attribute xml:id, that can be used by the user, to set an ID explicitly.
XML tag names cannot contain any of the characters !"#$%&'()*+,/;<=>?@[\]^`{|}~, nor a space character, and cannot begin with -, ., or a numeric digit, whereas JSON keys can (even if quotation mark and backslash must be escaped).[43]
XML values are strings of characters, with no built-in type safety. XML has the concept of schema, that permits strong typing, user-defined types, predefined tags, and formal structure, allowing for formal validation of an XML stream. JSON has several types built-in and has a similar schema concept in JSON Schema.
Supersets
[edit]Support for comments and other features have been deemed useful, which has led to several nonstandard JSON supersets being created. Among them are HJSON,[45] HOCON, and JSON5 (which despite its name, is not the fifth version of JSON).[46][47]
YAML
[edit]YAML version 1.2 is a superset of JSON; prior versions were not strictly compatible. For example, escaping a slash / with a backslash \ is valid in JSON, but was not valid in YAML.[48] YAML supports comments, while JSON does not.[48][46][21]
CSON
[edit]CSON ("CoffeeScript Object Notation") uses significant indentation and unquoted keys, and assumes an outer object declaration. It was used for configuring GitHub's Atom text editor.[49][50][51]
There is also an unrelated project called CSON ("Cursive Script Object Notation") that is more syntactically similar to JSON.[52]
HOCON
[edit]HOCON ("Human-Optimized Config Object Notation") is a format for human-readable data, and a superset of JSON.[53] The uses of HOCON are:
- It is used mostly along with the Play Framework,[54] and is developed by Lightbend.
- It is also supported as a configuration format for .NET projects via Akka.NET[55][56] and Puppet.[57]
- TIBCO Streaming:[58] HOCON is the primary configuration file format for the TIBCO Streaming[59] family of products (StreamBase, LiveView, and Artifact Management Server) as of TIBCO Streaming Release 10.[60]
- It is also the primary configuration file format for several subsystems of Exabeam Advanced Analytics.[61]
- Jitsi uses it as the "new" config system and .properties-Files as fallback[62][63]
JSON5
[edit]JSON5 ("JSON5 Data Interchange Format") is an extension of JSON syntax that, like JSON, is also valid JavaScript syntax. The specification was started in 2012 and finished in 2018 with version 1.0.0.[64] The main differences to JSON syntax are:
- Optional trailing commas
- Unquoted object keys
- Single quoted and multiline strings
- Additional number formats
- Comments
JSON5 syntax is supported in some software as an extension of JSON syntax, for instance in SQLite.[65]
JSONC
[edit]JSONC (JSON with Comments) is a subset of JSON5 used in Microsoft's Visual Studio Code:[66]
- supports single-line comments (
//) and block comments (/* */) - accepts trailing commas, but they are discouraged and the editor will display a warning
Derivatives
[edit]Several serialization formats have been built on or from the JSON specification. Examples include
- JSON-LD, a method of encoding linked data using JSON[69][70]
- JSON-RPC, a remote procedure call protocol encoded in JSON[71]
- JsonML, a lightweight markup language used to map between XML and JSON[72][73]
- Smile (data interchange format)[74][75]
- UBJSON, a binary computer data interchange format imitating JSON, but requiring fewer bytes of data[76][77]
- Jsonnet is a prototype-based domain-specific language that produces JSON files. All JSON documents are valid Jsonnet programs that will be emitted unchanged when run. Jsonnet extends JSON by supporting variables, imports, loops, comments, etc.[78][79] Jsonnet is used as a configuration language for cloud infrastructure engineering.[80]
See also
[edit]- BSON
- Comparison of data serialization formats
- Extensible Data Notation
- Amazon Ion – a superset of JSON (though limited to UTF-8, like JSON for interchange, unlike general JSON)
- Jackson (API)
- jaql – a functional data processing and query language most commonly used for JSON query processing
- jq – a "JSON query language" and high-level programming language
- JSONiq – a JSON-oriented query and processing language based on XQuery
- JSON streaming
- S-expression
References
[edit]- ^ a b c Crockford, Douglas (August 28, 2011). The JSON Saga (video). YUI Library. Retrieved February 21, 2022 – via YouTube.
- Transcript (archived 2019-10-30) from Transcript Vids
- ^ a b c "ISO/IEC 21778:2017 Information technology — The JSON data interchange syntax". ISO. Retrieved June 24, 2025.
- ^ "ECMA-404: The JSON Data Interchange Syntax" (2nd ed.). Ecma International. December 2017. p. iii, footnote. Archived (PDF) from the original on October 27, 2019. Retrieved April 29, 2024.
- ^ a b c "ECMA-404: The JSON Data Interchange Format" (1st ed.). Ecma International. October 2013. Archived (PDF) from the original on November 1, 2013. Retrieved November 20, 2023.
- ^ Sweigart, Al (2015). Automate the Boring Stuff with Python: Practical Programming for Total Beginners. No Starch Press. p. 319. ISBN 9781593276850. Retrieved October 29, 2019.
pronounced 'JAY-sawn' or 'Jason'—it doesn't matter how because either way people will say you're pronouncing it wrong
(assuming the cot-caught merger: "sawn" /sɔːn/ → [sɒn]). - ^ a b Bray, T. (December 2017). Bray, T (ed.). The JavaScript Object Notation (JSON) Data Interchange Format. IETF. doi:10.17487/RFC8259. S2CID 263868313. RFC 8259. Retrieved February 16, 2018.
- ^ Bray, Tim. "JSON Redux AKA RFC7159". Ongoing. Retrieved March 16, 2014.
- ^ "Unofficial Java History". Edu4Java. 26 May 2014. Archived from the original on 26 May 2014. Retrieved 30 August 2019.
In 1996, Macromedia launches Flash technology which occupies the space left by Java and ActiveX, becoming the de facto standard for animation on the client side.
- ^ "JSON". json.org.
- ^ Yahoo!. "Using JSON with Yahoo! Web services". Archived from the original on October 11, 2007. Retrieved July 3, 2009.
- ^ Crockford, Douglas (May 28, 2009). "Introducing JSON". json.org. Retrieved July 3, 2009.
It is based on a subset of the JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999.
- ^ Bray, Tim (December 2017). "History for draft-ietf-jsonbis-rfc7159bis-04". IETF Datatracker. Internet Engineering Task Force. Retrieved October 24, 2019.
2017-12-13 [...] RFC published
- ^ Bray, Tim (December 13, 2017). "RFC 8259 - The JavaScript Object Notation (JSON) Data Interchange Format". IETF Datatracker. Internet Engineering Task Force. Retrieved October 24, 2019.
Type: RFC - Internet Standard (December 2017; Errata); Obsoletes RFC 7159; Also known as STD 90
- ^ "Apache and the JSON license" on LWN.net by Jake Edge (November 30, 2016).
- ^ Douglas Crockford (July 10, 2016). "JSON in JavaScript". Archived from the original on July 10, 2016. Retrieved August 13, 2016.
JSON is a subset of the object literal notation of JavaScript.
- ^ Holm, Magnus (May 15, 2011). "JSON: The JavaScript subset that isn't". The timeless repository. Archived from the original on May 13, 2012. Retrieved September 23, 2016.
- ^ a b c "Subsume JSON: Proposal to make all JSON text valid ECMA-262". Ecma TC39. August 23, 2019. Retrieved August 27, 2019.
- ^ a b "Advance to Stage 4 - tc39/proposal-json-superset". GitHub. May 22, 2018.
- ^ "BigInt - MDN Web doc glossary". Mozilla. Retrieved October 18, 2020.
- ^ ECMA-404, 2nd ed., p. 3: "The JSON syntax does not impose any restrictions on the strings used as names, does not require that name strings be unique, and does not assign any significance to the ordering of name/value pairs."
- ^ a b c d e Crockford, Douglas (April 30, 2012). "Comments in JSON". Archived from the original on July 4, 2015. Retrieved August 30, 2019.
I removed comments from JSON because I saw people were using them to hold parsing directives, a practice which would have destroyed interoperability. I know that the lack of comments makes some people sad, but it shouldn't. Suppose you are using JSON to keep configuration files, which you would like to annotate. Go ahead and insert all the comments you like. Then pipe it through JSMin before handing it to your JSON parser.
- ^ Andrysco, Marc; Jhala, Ranjit; Lerner, Sorin (February 18, 2016). Printing Floating-Point Numbers: An Always Correct Method (PDF) (Report). Retrieved May 31, 2025.
- ^ "Trailing commas - JavaScript | MDN". developer.mozilla.org. September 12, 2023. Retrieved December 16, 2023.
- ^ "JSON5". json5. Archived from the original on November 29, 2020. Retrieved December 16, 2020.
- ^ ECMA-404, 2nd ed., p. iii: "The JSON syntax is not a specification of a complete data interchange. Meaningful data interchange requires agreement between a producer and consumer on the semantics attached to a particular use of the JSON syntax. What JSON does provide is the syntactic framework to which such semantics can be attached"
- ^ "Media Types". iana.org. Retrieved September 13, 2015.
- ^ "Correct Content-Type Header for JSON". ReqBin. January 13, 2023. Retrieved March 23, 2024.
- ^ Bray, Tim (December 2017). Bray, T. (ed.). "11. IANA Considerations". RFC 8259: The JavaScript Object Notation (JSON) Data Interchange Format. IETF. doi:10.17487/RFC8259. S2CID 263868313.
- ^ "JSON Schema and Hyper-Schema". json-schema.org. Retrieved June 8, 2021.
- ^ "JSON Schema - Specification Links". json-schema.org. Retrieved March 22, 2024.
- ^ "JSON Schema Implementations". json-schema.org. Archived from the original on June 16, 2021. Retrieved June 8, 2021.
- ^ Zyp, Kris (September 16, 2012). Bryan, Paul C. (ed.). "JSON Reference: draft-pbryan-zyp-json-ref-03". Internet Engineering Task Force.
- ^ Crockford, Douglas (May 16, 2019). "JSMin". Retrieved August 12, 2020.
JSMin [2001] is a minification tool that removes comments and unnecessary whitespace from JavaScript files.
- ^ "JSONB data type". www.cockroachlabs.com. Retrieved April 1, 2025.
- ^ "The JSON data type". dev.mysql.com. Retrieved April 1, 2025.
- ^ "JSON: The JavaScript subset that isn't". Magnus Holm. Archived from the original on May 13, 2012. Retrieved May 16, 2011.
- ^ "ECMA-262: ECMAScript Language Specification" (5th ed.). December 2009. Archived (PDF) from the original on April 14, 2011. Retrieved March 18, 2011.
- ^ "douglascrockford/JSON-js". GitHub. August 13, 2019.
- ^ "Denial of Service and Unsafe Object Creation Vulnerability in JSON (CVE-2013-0269)". Retrieved January 5, 2016.
- ^ "Microsoft .NET Framework JSON Content Processing Denial of Service Vulnerability". Archived from the original on November 6, 2018. Retrieved January 5, 2016.
- ^ "JSON: The Fat-Free Alternative to XML". json.org. Retrieved March 14, 2011.
- ^ "Amazon Ion". Amazon. Archived from the original on August 12, 2024. Retrieved August 26, 2024.
- ^ "XML 1.1 Specification". World Wide Web Consortium. Retrieved August 26, 2019.
- ^ Saternos, Casimir (2014). Client-server web apps with Javascript and Java. "O'Reilly Media, Inc.". p. 45. ISBN 9781449369316.
- ^ Edelman, Jason; Lowe, Scott; Oswalt, Matt. Network Programmability and Automation. O'Reilly Media.
for data representation you can pick one of the following: YAML, YAMLEX, JSON, JSON5, HJSON, or even pure Python
- ^ a b McCombs, Thayne (July 16, 2018). "Why JSON isn't a good configuration language". Lucid Chart. Retrieved June 15, 2019.
- ^ "HOCON (Human-Optimized Config Object Notation)". GitHub. January 28, 2019. Retrieved August 28, 2019.
The primary goal is: keep the semantics (tree structure; set of types; encoding/escaping) from JSON, but make it more convenient as a human-editable config file format.
- ^ a b "YAML Ain't Markup Language (YAML) Version 1.2". yaml.org. Retrieved September 13, 2015.
- ^ Dohm, Lee (2014). "CoffeeScript Object Notation". The Big Book of Atom. Archived from the original on April 22, 2023. Retrieved April 29, 2024.
- ^ "Basic Customization". Atom Flight Manual. GitHub. Archived from the original on April 29, 2024. Retrieved April 29, 2024.
- ^ "CSON". Bevry. December 20, 2023. Archived from the original on April 23, 2024. Retrieved April 29, 2024 – via GitHub.
- ^ Seonghoon, Kang (July 1, 2021). "CSON". Archived from the original on December 16, 2023. Retrieved February 27, 2023 – via GitHub.
- ^ "config/HOCON.md at master · lightbend/config". GitHub. Retrieved August 5, 2021.
- ^ "Config File - 2.5.x". www.playframework.com. Retrieved August 5, 2021.
- ^ Akka.NET HOCON Docs
- ^ "Akka.NET Documentation". getakka.net. Retrieved August 5, 2021.
- ^ "Managing HOCON configuration files with Puppet". Archived from the original on February 11, 2017. Retrieved March 4, 2023.
- ^ "StreamBase Documentation". docs.streambase.com. Retrieved August 5, 2021.
- ^ "Configuration Guide". docs.streambase.com. Retrieved August 5, 2021.
- ^ "StreamBase New and Noteworthy Archive". docs.streambase.com. Retrieved August 5, 2021.
- ^ "Exabeam Advanced Analytics Release Notes". Archived from the original on October 20, 2020. Retrieved March 4, 2023.
- ^ JITSI Project. "Config phase 1". GitHub. Retrieved February 16, 2021.
- ^ JITSI Project. "reference.conf". GitHub. Retrieved February 16, 2021.
- ^ "The JSON5 Data Interchange Format". Retrieved June 25, 2022.
- ^ SQLite. "JSON Functions And Operators". Retrieved June 25, 2023.
- ^ "JSON with Comments - JSON editing in Visual Studio Code". Visual Studio Code. Microsoft. Retrieved April 29, 2024.
- ^ Butler, H.; Daly, M.; Doyle, A.; Gillies, Sean; Schaub, T.; Hagen, Stefan (August 2016). "RFC 7946 - The GeoJSON Format". IETF Datatracker. Retrieved June 17, 2022.
- ^ "GeoJSON". geojson.org. Retrieved August 7, 2022.
- ^ "JSON-LD 1.1". World Wide Web Consortium. July 16, 2020. Retrieved June 17, 2022.
- ^ "JSON-LD - JSON for Linking Data". json-ld.org. Retrieved August 7, 2022.
- ^ "JSON-RPC". jsonrpc.org. Retrieved June 17, 2022.
- ^ "JsonML (JSON Markup Language)". JsonML.org. Retrieved June 17, 2022.
- ^ McKamey, Stephen (June 14, 2022), JsonML, retrieved August 7, 2022
- ^ "FasterXML/smile-format-specification: New home for Smile format". GitHub. Retrieved June 17, 2022.
- ^ Gupta, Ayush (February 10, 2019). "Understanding Smile — A data format based on JSON". Code with Ayush. Retrieved August 7, 2022.
- ^ "Universal Binary JSON Specification – The universally compatible format specification for Binary JSON". ubjson.org. Retrieved June 17, 2022.
- ^ "UBJSON - JSON for Modern C++". json.nlohmann.me. Retrieved August 7, 2022.
- ^ Bryan Feuling "Repeatability, Reliability, and Scalability Through GitOps". 2021. p. 129.
- ^ William Hegedus. "Mastering Prometheus". 2024. p. 194 - 198.
- ^ Eric Liang and Aaron Davidson "Declarative Infrastructure with the Jsonnet Templating Language". 2017.
External links
[edit]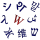 Definitions from Wiktionary
Definitions from Wiktionary Media from Commons
Media from Commons Textbooks from Wikibooks
Textbooks from Wikibooks
Standards of Ecma International | ||
|---|---|---|
| Application interfaces | ||
| File systems (tape) |
| |
| File systems (disk) | ||
| Graphics | ||
| Programming languages | ||
| Radio link interfaces | ||
| Other | ||
List of Ecma standards (1961 – present) | ||
| International | |
|---|---|
| National | |
| Other | |
application/json.[2]
A simple JSON object might look like this:
{
"name": "John Doe",
"age": 30,
"isStudent": false,
"hobbies": ["reading", "swimming"]
}
{
"name": "John Doe",
"age": 30,
"isStudent": false,
"hobbies": ["reading", "swimming"]
}
Fundamentals
Naming and Pronunciation
JSON stands for JavaScript Object Notation, a term coined by Douglas Crockford in 2001 to describe a lightweight data serialization format derived from a subset of JavaScript's object literal syntax as defined in ECMA-262 3rd Edition.[7][3] Although rooted in JavaScript, JSON was conceived as a language-independent interchange format to facilitate the exchange of structured data across different programming environments and systems.[7][8] The acronym JSON is most commonly pronounced as /ˈdʒeɪsən/ ("jay-son"), akin to the personal name Jason, reflecting English conventions for rendering pronounceable acronyms as words rather than spelling out the letters.[9] Alternative pronunciations include /ˈdʒeɪsɔːn/ ("jay-sawn"), with emphasis on the second syllable, and an elided form /dʒəˈsɒn/ ("j'son") resembling a French pronunciation, as used by Crockford himself in presentations.[10] The preference for "jay-son" stems from its simplicity and alignment with phonetic norms for tech acronyms, avoiding the cumbersome letter-by-letter rendition "jay-ess-oh-en".[9]Design Principles
JSON was designed with a core emphasis on simplicity and minimalism, aiming to provide a lightweight alternative to more verbose data interchange formats like XML. As a text-based format, it prioritizes ease of use by being straightforward for humans to read and write, while remaining efficient for machines to parse and generate. This approach avoids unnecessary complexity, such as mandatory schemas or extensive markup, focusing instead on basic data serialization and deserialization for straightforward interchange.[1][2] The primary goals of JSON include promoting interoperability across diverse programming languages and environments, without tying it exclusively to any one implementation. It achieves this by supporting a limited set of universal data structures—objects (name/value pairs) and arrays (ordered lists)—that map naturally to common constructs in languages like C, Java, Python, and others. By reducing verbosity and eliminating features like comments or schemas in its core specification, JSON facilitates faster processing and lower overhead compared to XML, which often requires additional parsing layers and validation mechanisms. This "fat-free" philosophy underscores its role as a portable, textual format optimized for networked data exchange.[11][2] Influenced by the object model in JavaScript (ECMA-262), JSON adopts a subset of its syntax to ensure familiarity and parsability, but it was intentionally crafted to be language-independent, extending beyond JavaScript environments. This design choice reflects a deliberate minimalism, where only essential elements are included to maintain universality and avoid the bloat seen in heavier formats. As its creator noted, JSON represents a natural fit for C-family languages while enabling broad adoption without the need for proprietary extensions.[1][2]Historical Development
Origins and Creation
JSON originated in April 2001 when Douglas Crockford, serving as Chief Technology Officer and co-founder of State Software, Inc., discovered a lightweight data interchange format derived from JavaScript object literals.[12][11] State Software, founded that year, aimed to build highly interactive web applications, and Crockford developed JSON to facilitate efficient data exchange between client-side JavaScript and server-side systems.[12] This innovation addressed the verbosity and parsing overhead of XML, which was then the dominant format for web data exchange, by leveraging a simple, text-based structure that could be natively evaluated in JavaScript without additional libraries.[11] The motivations stemmed from challenges in early web development, where developers needed efficient, human-readable ways to transfer structured data across networks for dynamic applications—concepts predating the formal term "AJAX" coined in 2005.[11] Crockford sought to avoid the complexities of binary formats like ASN.1 or Protocol Buffers, opting instead for a universal text representation that ensured broad interoperability across programming languages and platforms, while remaining a strict subset of the ECMAScript specification (Third Edition, December 1999).[13] The first practical use of JSON occurred in April 2001 during internal testing at State Software for inter-server communication and simple data persistence.[11] In 2002, following the company's closure, Crockford acquired the json.org domain and published the initial specification, grammar, and a JavaScript parser implementation to promote the format publicly.[11] This early documentation emphasized JSON's minimalism as a "fat-free alternative to XML," highlighting its suitability for embedding data directly in web pages or transmitting it via HTTP without specialized tooling.[11] The format's design prioritized ease of generation and parsing in resource-constrained environments like browsers, marking a pivotal shift toward simplified data serialization in web technologies.Adoption Milestones
JSON's adoption accelerated in the mid-2000s alongside the rise of Asynchronous JavaScript and XML (AJAX), which enabled dynamic web applications and highlighted the need for lightweight data interchange formats. In 2005, Jesse James Garrett coined the term "AJAX" in an influential article, spurring widespread experimentation with JSON for server-client communication due to its simplicity and native compatibility with JavaScript.[5] Early JavaScript libraries, such as the Dojo Toolkit released in 2006, integrated JSON parsing and serialization capabilities, facilitating its use in cross-browser AJAX implementations and contributing to broader developer uptake.[14] By the 2010s, JSON's momentum led to formal standardization and pervasive integration in web services. Ecma International adopted JSON as ECMA-404 in October 2013, defining its syntax as a language-independent data interchange format derived from JavaScript.[15] The Internet Engineering Task Force (IETF) followed with RFC 7159 in January 2014, further specifying JSON for internet protocols and emphasizing interoperability.[16] This era saw an explosion in RESTful APIs leveraging JSON, including Twitter's API (introduced in 2006 but expanded significantly in the 2010s) and Facebook's Graph API (launched in 2010), both returning data in JSON format to simplify client-side processing.[17][18] Refinements continued into the late 2010s and 2020s, solidifying JSON's role in emerging technologies. The IETF updated the specification with RFC 8259 in December 2017, introducing clarifications on numeric precision and structural rules to enhance robustness across implementations.[2] In the 2020s, JSON became integral to Internet of Things (IoT) protocols, such as MQTT, where it structures payloads for efficient device-to-cloud data exchange in industrial applications.[19] Similarly, serverless computing platforms, like AWS Lambda, adopted JSON as the standard input/output format for functions, supporting scalable event-driven architectures in the growing serverless computing market. Usage statistics underscored JSON's dominance by the mid-2010s, with developer surveys and API analyses indicating it as the leading data format for web services, surpassing XML in adoption for its conciseness and ease of parsing.[4]Standards and Specifications
Official Standards (ECMA and IETF)
JSON, as a data interchange format, is formally defined by standards from Ecma International and the Internet Engineering Task Force (IETF). The Ecma International standard ECMA-404, first published in October 2013, specifies JSON as a lightweight, text-based, language-independent syntax derived from the object literals of the ECMAScript programming language (as defined in ECMA-262).[20] It describes JSON as a restricted subset of JavaScript, focusing on a simple grammar for representing structured data using Unicode characters, with rules for objects (unordered collections of name/value pairs), arrays (ordered lists of values), and primitive types including strings, numbers, booleans, and null.[15] The standard emphasizes portability across programming languages and prohibits features like functions or dates that could introduce implementation dependencies.[20] In December 2017, Ecma International released the second edition of ECMA-404, which refined the grammar to align precisely with contemporary interoperability needs while maintaining equivalence to the IETF specification.[21] This revision incorporated clarifications on whitespace handling and structural elements but did not introduce substantive changes to the core syntax, ensuring backward compatibility with the 2013 edition.[21] The IETF's primary specification is RFC 8259, published in December 2017 as a Proposed Standard on the IETF Standards Track.[2] This document obsoletes RFC 7159 (March 2014), which had obsoleted RFC 7158 (March 2014) and the earlier informational RFC 4627 (July 2006), providing a comprehensive definition of JSON for network interchange.[2] RFC 8259 mandates UTF-8 encoding without a byte order mark (BOM), specifies robust error handling for malformed input (such as treating invalid UTF-8 sequences as errors), and requires implementations to reject non-conforming documents to enhance security and reliability.[2] It also addresses ambiguities in prior versions, such as prohibiting leading zeros in integral parts of numbers (except for zero itself) to avoid octal misinterpretation and restricting Unicode escape sequences to non-ASCII characters for clarity.[2] Key revisions in RFC 8259 compared to its predecessors include improved Unicode support, such as explicit requirements for surrogate pair handling in strings, and guidance on implementation limits (e.g., recommending at least 64 levels of nesting to prevent stack overflows).[2] These changes promote greater interoperability across diverse systems, repairing errors like inconsistent treatment of whitespace and plus signs in exponents from RFC 4627.[2] The ECMA-404 second edition and RFC 8259 are designed to be fully compatible, with the IETF document providing additional protocol-oriented details like media type registration (application/json) and conformance criteria.[21][2] For streaming scenarios in the 2020s, the IETF has extended JSON support through related specifications, such as RFC 7464 (May 2015), which defines JSON text sequences using record separators for concatenated JSON values in streaming protocols.[22] This enables efficient, line-oriented processing without full document parsing, registered as the media type application/json-seq.[22]Schema Standards
JSON Schema is a vocabulary that allows authors to annotate and validate JSON documents, defining the structure, content, and semantics of JSON data. It originated with the first draft (draft-00) published in late 2009 by Kris Zyp, evolving through multiple iterations to address the need for a standardized way to describe JSON constraints beyond the basic format specified in RFC 8259. The specification progressed from early drafts focused on basic validation to more advanced features, with the current version being draft-2020-12, which separates core definitions from validation and hypermedia annotations. This evolution enables schemas ranging from simple type and structure checks to complex hypermedia descriptions, filling gaps in the core JSON specification by providing a declarative language for constraints like required properties and data formats.[23][24] Standardization efforts for JSON Schema are ongoing under the IETF as an internet-draft, specifically draft-handrews-json-schema, which defines it as a media type for describing JSON documents but has not yet advanced to RFC status due to process challenges. Despite this, JSON Schema has seen widespread adoption in development tools and libraries, including the AJV validator, which implements the specification efficiently for JavaScript environments and supports all major drafts. This adoption underscores its role in ensuring data integrity across applications, with implementations in various languages facilitating interoperability in APIs, configuration files, and data exchange.[25][26] Key features of JSON Schema include essential keywords such as$schema to identify the draft version, type for specifying primitive or compound types, properties for object member definitions, and required for mandating fields. Advanced capabilities encompass conditional logic via keywords like if, then, and else to apply subschemas based on data conditions, as well as format assertions for semantic validation (e.g., date-time per RFC 3339). These elements allow for precise control over JSON structures, supporting everything from basic type enforcement to intricate validation rules without altering the underlying JSON syntax.
JSON Schema integrates with JSON-LD, a W3C recommendation initially published in 2014 and updated in 2020, to enhance semantic web applications by validating the structural aspects of linked data expressed in JSON. In contexts like the Web of Things and Verifiable Credentials, JSON Schema describes the syntactic constraints of JSON-LD documents, ensuring they conform to expected shapes while JSON-LD provides the semantic layering through RDF mappings. This combination enables robust, machine-readable schemas for semantic data interchange.[27][28]
Syntax
Character Encoding
JSON text exchanged between systems outside a closed ecosystem must be encoded in UTF-8, as specified in RFC 8259, to ensure interoperability.[2] This requirement aligns with the broader adoption of UTF-8 as the standard for web protocols. While implementations in closed environments may use other Unicode encodings like UTF-16 or UTF-32, these are not mandated for general interchange and require a byte order mark (BOM, U+FEFF) for detection; parsers may ignore a BOM but must not add it to transmitted JSON.[2] Within JSON strings, all Unicode characters are permitted except those that must be escaped: the quotation mark (U+0022), reverse solidus (U+005C), and control characters (U+0000 through U+001F).[29] Escaping uses a reverse solidus followed by specific sequences, including " for quotation mark, \ for reverse solidus, / for solidus (optional but allowed), \b for backspace, \f for form feed, \n for line feed, \r for carriage return, and \t for horizontal tab.[29] Unicode characters in the Basic Multilingual Plane (U+0000 to U+FFFF) can be represented via a six-character \uXXXX escape, where XXXX are four hexadecimal digits encoding the code point; characters in astral planes (beyond U+FFFF) use a 12-character sequence of two \u escapes forming a UTF-16 surrogate pair.[29] Undefined escapes, such as \v for vertical tab, are not permitted and render the JSON invalid.[29] JSON handles astral plane characters through UTF-16 surrogate pairs, but unpaired surrogates (e.g., a lone high surrogate like \uD800) are grammatically allowed yet lead to unpredictable parser behavior, as they do not form valid Unicode scalar values.[30] The specification imposes no Unicode normalization requirements, so JSON strings may use either NFC or NFD forms without issue, provided they consist of valid Unicode sequences.[2] Invalid sequences, including malformed UTF-8 bytes or overlong encodings, should be rejected by parsers, though implementation variations exist.[31]Data Types
JSON supports a small set of primitive and composite data types, designed for simplicity and portability across programming languages. The primitive types include strings, numbers, booleans, and null, while the composite types are objects and arrays. These types form the foundation of JSON's data model, enabling structured representation of information without language-specific features. Strings in JSON are sequences of zero or more Unicode characters, enclosed in double quotation marks. They must escape special characters such as the quotation mark itself (\"), reverse solidus (\\), and control characters (e.g., newline as \n). JSON strings support Unicode via escape sequences like \uXXXX for hexadecimal code points, ensuring consistent representation across systems.
Numbers are represented in base-10 decimal notation, supporting integers and fractions with optional exponents (e.g., 123, 3.14159, 1e-10). Leading zeros are prohibited except for the value zero itself (0), and no octal or hexadecimal formats are allowed to avoid ambiguity. JSON numbers are finite, excluding infinities and NaN values, which are not part of the strict specification.
Booleans are the literals true and false (case-sensitive), representing logical true and false values. The null type is the literal null, denoting the absence of a value. These primitives are self-delimiting and do not require additional quoting or formatting.
Objects are unordered collections of name-value pairs, where each name is a string and values can be any JSON type. Pairs are separated by commas and enclosed in curly braces ({}), forming a structure analogous to a dictionary or map in various languages. Arrays are ordered sequences of zero or more values of any type, delimited by square brackets ([]) and separated by commas, providing list-like functionality.
JSON does not natively support types such as undefined, functions, or dates; attempts to serialize these in implementations often result in approximations like omitting undefined values or converting dates to strings. In practice, dates are commonly represented as ISO 8601-formatted strings (e.g., "2023-10-01T12:00:00Z") within JSON payloads, though this is a convention rather than a built-in type.
Structural Rules
A JSON document, known formally as JSON text, consists of a single top-level value, which may be an object, array, string, number, true, false, or null, serialized according to defined formatting rules. This structure ensures that JSON documents are self-contained and portable for data interchange. Nesting is achieved through recursion, allowing objects to contain arrays and vice versa, which enables the representation of complex hierarchical data without depth limits beyond practical implementation constraints. Objects are delimited by curly braces{} and consist of zero or more name-value pairs separated by colons :, with pairs themselves separated by commas ,. Arrays are delimited by square brackets [] and contain zero or more values separated by commas. These delimiters, along with the comma and colon, form the core grammatical elements that enforce a consistent, parsable syntax across implementations.
Whitespace characters, such as spaces, tabs, carriage returns, and line feeds, are insignificant in JSON text except when enclosed within string values, allowing flexible formatting for readability without affecting semantics. Standard JSON does not support comments, as there is no provision for non-value tokens like // or /* */ in the grammar, ensuring that parsers treat the entire document as data.
JSON is designed to be streamable and stateless, meaning parsers can process documents incrementally without retaining prior state beyond the current nesting level, which supports efficient handling of large payloads. Parsing must fail on syntactic errors, such as trailing commas after the last member of an object or element of an array, unclosed delimiters, or mismatched braces and brackets, to maintain strict interoperability. For very large documents or streaming scenarios, variants like line-delimited JSON (LDJSON), also known as JSON Lines, have emerged, where each line contains a complete JSON value terminated by a newline, facilitating real-time processing without buffering the entire structure.[32]
Semantics and Interoperability
Semantic Definitions
JSON objects are semantically defined as unordered collections of zero or more name/value pairs, where each name is a string and serves as a key, and each value can be any JSON value type including strings, numbers, booleans, null, objects, or arrays.[2] Although the specification does not require keys to be unique, using duplicate keys can lead to interoperability issues across implementations, and it is recommended that keys within an object be unique to ensure consistent behavior.[2] The ordering of pairs in an object has no semantic significance, meaning that the sequence in which they appear in the serialized text does not imply any relational order; however, many modern implementations, influenced by language-specific behaviors like JavaScript's insertion-order preservation since ECMAScript 2015, may retain the order during parsing and serialization.[2] This has sparked discussions in standards bodies and developer communities about whether to rely on order preservation, with the ECMA-404 second edition (2017) maintaining the unordered semantics while aligning closely with RFC 8259 to promote consistency without mandating order.[21][2] JSON arrays represent ordered sequences of zero or more values, where the position of each element implies an implicit integer index starting from zero, and duplicates are explicitly permitted without any restrictions.[2] The order of values in an array is semantically significant and must be preserved by conforming parsers to maintain the intended structure during data interchange.[2] For example, the array[ "a", "b", "a" ] conveys two distinct occurrences of "a" at different positions, distinguishing it from a set-like structure.[2]
Numbers in JSON are represented as double-precision floating-point values in base-10 decimal notation, without support for special values like Infinity or NaN, and their internal representation is implementation-dependent but should follow IEEE 754 conventions for interoperability.[2] Integer values are exactly representable up to the range from -(2^53 - 1) to 2^53 - 1, beyond which precision may be lost in floating-point storage, limiting safe interchange of larger integers without additional encoding.[2] This constraint arises from the 53-bit significand in double-precision format, ensuring that whole numbers within this "safe integer" range can be round-tripped without alteration across compliant systems.[2]
The boolean values true and false, along with the null literal null, are primitive types defined by exact, case-sensitive string matches to these lowercase keywords, carrying no additional semantic payload beyond their literal meanings.[2] Any deviation in casing, such as True or NULL, renders the text invalid JSON, enforcing strict literal interpretation for reliable parsing.[2] These primitives provide foundational truth values and absence indicators, integral to expressing conditional logic and optional data in JSON structures.[2]
Cross-Language Compatibility
JSON enjoys native support in several major programming languages, facilitating seamless parsing and generation without external dependencies. In JavaScript, the built-in JSON global object provides methods likeparse() and stringify() for handling JSON data directly in the language's runtime environment.[33] Python includes the json module in its standard library, offering functions such as json.dumps() for serialization and json.loads() for deserialization, compliant with RFC 8259.[34] Java provides the javax.json API through the Java API for JSON Processing (JSON-P), a standard specification that enables object model and streaming APIs for JSON operations, though implementations like GlassFish JSON-P are required for full functionality.[35]
For languages lacking native support, robust third-party libraries address JSON handling, including edge cases like big integers that exceed JavaScript's safe integer limit of 2^53 - 1. In Java, Google's Gson library converts objects to JSON and vice versa, with options to serialize large integers as strings or use BigInteger types to preserve precision without floating-point conversion.[36] Similarly, jsoncpp for C++ supports parsing and generating JSON, treating oversized integers as strings by default to avoid precision loss during double-based number handling.[37] These libraries ensure cross-language consistency by adhering to the JSON specification while accommodating language-specific type systems.
A key challenge in cross-language JSON use involves common pitfalls in serialization and deserialization. Dates lack a native type in JSON per RFC 8259, so they are typically serialized as ISO 8601 strings (e.g., "2025-11-08T12:00:00Z") using conventions like JavaScript's Date.toJSON(), requiring careful parsing on the receiving end to reconstruct date objects accurately across languages.[2][38] Binary data, being incompatible with JSON's text-based format, must be encoded as base64 strings, as recommended in standards like RFC 7951 for YANG-modeled data, which increases payload size by approximately 33% but ensures safe transmission.[39]
In 2025, advancements enhance JSON interoperability in emerging environments. WebAssembly's Interop 2025 initiative improves JavaScript string builtins, enabling more efficient JSON parsing and generation in WASM modules for cross-language applications without foreign function interface overhead.[40] Additionally, .NET 10 (released November 2025) introduces JSON library enhancements, such as support for duplicate properties in JsonSerializerOptions, to better handle interoperability issues with non-unique keys. Separately, it adds post-quantum cryptography support, including algorithms such as ML-KEM, for secure data interchange scenarios.[41]
Validation and Metadata
JSON Schema
JSON Schema is a declarative language that allows developers to annotate and validate the structure, constraints, and content of JSON documents. It enables the definition of expected data formats through a JSON-based vocabulary of keywords, facilitating both documentation and programmatic validation of JSON instances against these specifications. This approach ensures data consistency in applications ranging from APIs to configuration files, by specifying rules such as required properties, data types, and value constraints.[42] The core usage of JSON Schema involves creating a schema document that describes the anticipated structure of a JSON instance. For validation, schemas employ keywords to enforce rules on properties like strings, numbers, objects, and arrays. Key validation keywords includeenum, which restricts a value to a predefined set of options; minLength, which sets a minimum character count for strings; and pattern, which applies a regular expression to match string formats. These keywords are applied within schema objects to define precise constraints, allowing validators to check if an instance conforms or report specific violations.[43]
A simple example of a JSON Schema defines an object with a required string property for a product name:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"productName": {
"type": "string",
"description": "The name of the product"
}
},
"required": ["productName"]
}
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"productName": {
"type": "string",
"description": "The name of the product"
}
},
"required": ["productName"]
}
{"productName": "Widget"} but rejects {"id": 123} due to the missing required property. For more advanced features, keywords like allOf combine multiple subschemas, requiring an instance to satisfy all; oneOf requires exactly one subschema to match; and anyOf requires at least one subschema to match. Discriminated unions, also known as tagged unions, can be implemented using oneOf or anyOf combined with a discriminator field to distinguish between variants. For example, a schema might use a "type" field as the discriminator to select the appropriate subschema for different object types. An example using allOf for a product with both an ID and name:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"allOf": [
{
"type": "object",
"properties": {
"productId": { "type": "integer" }
},
"required": ["productId"]
},
{
"type": "object",
"properties": {
"productName": { "type": "string" }
},
"required": ["productName"]
}
]
}
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"allOf": [
{
"type": "object",
"properties": {
"productId": { "type": "integer" }
},
"required": ["productId"]
},
{
"type": "object",
"properties": {
"productName": { "type": "string" }
},
"required": ["productName"]
}
]
}
{"productId": 1, "productName": "Widget"}. An example of a discriminated union using oneOf with a discriminator:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"oneOf": [
{
"properties": {
"type": { "const": "cat" },
"meows": { "type": "integer" }
},
"required": ["type", "meows"],
"additionalProperties": false
},
{
"properties": {
"type": { "const": "dog" },
"barks": { "type": "number" }
},
"required": ["type", "barks"],
"additionalProperties": false
}
],
"discriminator": {
"propertyName": "type"
}
}
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"oneOf": [
{
"properties": {
"type": { "const": "cat" },
"meows": { "type": "integer" }
},
"required": ["type", "meows"],
"additionalProperties": false
},
{
"properties": {
"type": { "const": "dog" },
"barks": { "type": "number" }
},
"required": ["type", "barks"],
"additionalProperties": false
}
],
"discriminator": {
"propertyName": "type"
}
}
{"type": "cat", "meows": 5} or {"type": "dog", "barks": 3.0} but rejects those without a matching discriminator value.[44][45]
Implementations of JSON Schema are available across languages, with libraries handling validation against various draft versions for compatibility. In Python, the jsonschema library provides comprehensive support for drafts 3 through 2020-12, enabling both validation and schema introspection. For JavaScript, AJV (Another JSON Schema Validator) offers high-performance validation compatible with drafts 4, 6, 7, 2019-09, and 2020-12, widely used in web applications. Draft compatibility is crucial, as the specification has evolved from early drafts (e.g., draft-04) to the current 2020-12, which introduces simplifications like unified type handling; tools like these ensure backward compatibility where needed. As of November 2025, Draft 2020-12 remains the latest version of the JSON Schema specification.[46][47][48][24]
JSON Schema integrates deeply with API standards, notably OpenAPI 3.1.0 (released February 18, 2021), with a minor update to 3.1.1 in October 2024, which mandates the use of JSON Schema (based on Draft 2020-12) in Schema Objects for defining and validating request and response payloads. This requirement ensures consistent structure enforcement in API documentation and tooling, such as specifying media types in RequestBody and Response objects.
Metadata Extensions
JSON-LD (JSON for Linking Data) is a W3C recommendation that provides a lightweight syntax for serializing Linked Data in JSON, enabling the representation of RDF (Resource Description Framework) graphs while maintaining compatibility with standard JSON structures.[27] Introduced as a W3C Recommendation in 2014 with version 1.0, it was updated to version 1.1 in 2020 to address usability issues and enhance integration with web-based programming environments.[27] Key features include the@context keyword, which maps JSON keys to RDF terms for semantic interpretation, and @id for identifying resources with IRIs (Internationalized Resource Identifiers), allowing existing JSON data to be augmented with linked data semantics without altering its core format.[49] The 1.1 specification also introduces support for streaming parsers, facilitating the processing of large documents in memory-constrained environments by handling input incrementally.[50]
Beyond JSON-LD, other metadata extensions build on JSON to add domain-specific annotations or structures. GeoJSON, defined in RFC 7946 and published in 2016, extends JSON for encoding geographic data structures, representing features like points, lines, and polygons alongside their properties and bounding boxes.[51] This format uses standard JSON objects but incorporates geometry types (e.g., "Point" with coordinate arrays) to enable geospatial interoperability without requiring proprietary extensions.[52] Similarly, JSON Patch, specified in RFC 6902, introduces annotations for describing modifications to JSON documents through an array of operations such as "add", "remove", "replace", and "move", allowing precise, reversible updates while preserving the original data's integrity.[53] These operations are expressed as JSON objects with paths using JSON Pointer syntax, making them suitable for partial updates in distributed systems.[54]
In API design, metadata extensions like these are commonly used to incorporate non-core information such as versioning indicators or detailed error descriptions, ensuring that primary data remains uncluttered. For instance, the JSON:API specification employs a top-level meta object to hold supplementary details, such as API version numbers or pagination metadata, which do not influence the serialization of resource objects and thus avoid polluting the core data payload.[55] Likewise, RFC 9457 defines a "problem details" format for HTTP APIs, using JSON to convey machine-readable error information—including status codes, titles, and instances—separate from the main response body to enhance error handling without embedding it in the primary data structure.[56] This approach promotes cleaner data interchange by isolating descriptive metadata, reducing parsing complexity for clients.
Applications
Data Interchange and APIs
JSON plays a central role in data interchange for RESTful APIs, serving as the standard format for request and response payloads transmitted over HTTP. In REST architecture, JSON's lightweight structure enables efficient serialization of resources, such as user data or repository information, allowing clients to send structured queries and receive precise responses without excess verbosity. For instance, the GitHub REST API utilizes JSON exclusively for all endpoints, where a GET request to retrieve a repository's details returns a JSON object containing fields like name, description, and stars count, facilitating seamless integration in applications like version control tools.[57] The evolution of client-side JavaScript has further entrenched JSON in web communication through mechanisms like AJAX and the modern Fetch API. Initially, AJAX relied on the XMLHttpRequest object to asynchronously fetch data, often parsing JSON responses to update dynamic web pages without full reloads, a technique popularized in the early 2000s for interactive user interfaces. The Fetch API, introduced as a promise-based successor in 2015, simplifies this process by natively supporting JSON handling via methods likeresponse.json(), enabling cleaner code for sending and receiving JSON payloads in contemporary single-page applications.[58]
For real-time applications, WebSockets extend JSON's utility by allowing bidirectional, low-latency message exchanges between clients and servers, where JSON-formatted messages convey updates like chat notifications or live stock prices. This contrasts with polling-based HTTP requests, reducing overhead while maintaining JSON's parseability for immediate processing in JavaScript environments.[59]
JSON's advantages in API contexts stem from its compact representation and straightforward parsing, which minimize bandwidth usage and computational demands compared to alternatives like XML. JSON payloads are typically 30-50% smaller in size and parse 2-3 times faster, making them ideal for high-volume network traffic. Usage statistics underscore this dominance: by 2022, approximately 97% of API requests analyzed across global traffic utilized JSON, a figure that has held steady into 2025 with 97% of API payloads still in this format.[60][61][62]
As of 2025, emerging trends highlight JSON's adaptability in advanced protocols. GraphQL APIs, which allow clients to query exactly the data needed, standardize responses in JSON format, reducing over-fetching in complex systems like e-commerce platforms. Similarly, gRPC services increasingly incorporate JSON transcoding, enabling HTTP/JSON calls to binary protobuf-based endpoints, thus broadening accessibility for web developers without native gRPC support.[63][64]
Configuration and Storage
JSON's lightweight structure and human-readable format make it particularly suitable for configuration files, where developers need to define project settings, dependencies, and metadata in a way that is both machine-parsable and easily editable by hand. For instance, in Node.js projects, the package.json file specifies package metadata, scripts, and dependencies using JSON syntax, enabling tools like npm to manage installations and builds efficiently.[65] Similarly, in PHP ecosystems, composer.json outlines project requirements and autoloading configurations, allowing Composer to resolve and install dependencies across environments.[66] The advantages of JSON for such files include its simplicity and interoperability, as it requires no special editors beyond a text processor, facilitating quick modifications without risking syntax errors common in more verbose formats. In persistent storage scenarios, JSON serves as a foundational format for NoSQL databases, enabling flexible schema-less data management. MongoDB stores documents in BSON, a binary-encoded superset of JSON that supports additional types like dates and binaries while preserving JSON compatibility for querying and export.[67] Apache CouchDB, in contrast, natively stores data as JSON documents, leveraging HTTP for access and replication, which aligns with web-centric architectures.[68] Querying in these systems often employs JSONPath expressions, a standardized syntax for selecting and extracting values from JSON structures, akin to XPath for XML, to navigate nested objects and arrays efficiently.[69] Beyond databases, JSON finds extensive use in other persistent data applications, such as game save files and structured log files, where its hierarchical nature accommodates complex, evolving data without rigid schemas. In video game development, JSON is commonly used to serialize player progress, inventory, and world states— for example, in engines like Godot, where it balances readability for debugging with efficient parsing for load times.[70] For logging, JSON enables structured formats that include timestamps, levels, and contextual key-value pairs, improving searchability in tools like ELK Stack; best practices recommend consistent schemas and appropriate data types to avoid parsing issues.[71] Manipulation of these files is streamlined by utilities like jq, a command-line JSON processor that filters, transforms, and queries data streams with a syntax inspired by Unix tools such as sed and awk. In the 2020s, JSON's role has expanded in machine learning and edge computing for configuration and storage needs. TensorFlow serializes model architectures and layer configurations into JSON files (e.g., config.json), separating topology from weights to enable portable deployment across platforms.[72] In edge computing, JSON facilitates lightweight data storage on resource-constrained devices, such as IoT gateways, where it supports schema-flexible persistence for sensor readings and control metadata before synchronization to the cloud.[73]Security Considerations
Vulnerabilities
JSON, while lightweight and widely used, introduces several security vulnerabilities during parsing and handling, particularly when processing untrusted input. One prominent risk arises from injection attacks, such as those exploiting deprecated JSONP mechanisms. JSONP, originally designed to bypass same-origin policy restrictions by wrapping JSON in a script tag, enables cross-site scripting (XSS) if the callback function is controlled by an attacker, allowing arbitrary JavaScript execution.[74] This vulnerability has been deprecated in modern frameworks like Spring, where JSONP support was disabled by default starting in version 5.1 to favor CORS, yet legacy implementations remain susceptible.[75] Additionally, prototype pollution in JavaScript environments occurs when parsers fail to sanitize special keys like "proto" in JSON objects, enabling attackers to modify the Object.prototype and alter application behavior globally, potentially leading to arbitrary code execution or data tampering.[76] This issue affects libraries that merge JSON data without deep cloning or property checks, as demonstrated in exploits targeting Node.js applications.[77] Denial-of-service (DoS) attacks exploit JSON's structural flexibility to overwhelm parsers. Deeply nested objects or arrays can trigger stack overflows during recursive parsing, causing applications to crash; for instance, the Jackson library in versions prior to 2.15.0 suffers from this when processing crafted inputs exceeding default recursion limits, leading to StackOverflowError.[78] Similarly, json-smart versions before 2.4.9 are vulnerable to uncontrolled recursion on nested structures, resulting in stack exhaustion and service disruption.[79] Large payloads, such as expansive arrays or objects, can cause memory exhaustion by forcing parsers to allocate disproportionate resources during deserialization. Jettison's XML-to-JSON conversion in affected versions also amplifies memory usage from seemingly compact inputs, enabling attackers to deny service without exceeding request size limits.[80] Recent examples include CVE-2025-12044 in HashiCorp Vault, allowing unauthenticated DoS via malformed JSON payloads (as of October 2025).[81] Encoding discrepancies in JSON further pose risks, particularly with malformed Unicode sequences that can evade sanitization and facilitate XSS. Attackers may embed Unicode escapes (e.g., \u003cscript\u003e) in JSON strings, which, if improperly decoded and inserted into HTML without re-escaping, execute as malicious code; this bypasses filters expecting direct tag injection, as JSON allows any Unicode character except unescaped control codes.[82] Malformed UTF-8 in JSON payloads can also trigger parser errors or buffer overflows in lenient implementations, indirectly enabling injection if error handling outputs raw data.[83] For example, CVE-2025-9403 in the jq JSON processor allows DoS via invalid Unicode escape sequences (as of August 2025).[84] Number parsing ambiguities compound these issues, where extreme values like 1e309—representing near-infinity in double-precision floating-point—can overflow integer types in strict parsers, causing silent data corruption or crashes; JavaScript's Number.parseFloat handles it as finite, but languages like Python's json module may raise exceptions or lose precision, disrupting type-safe applications.[85] From 2022 to 2025, JSON libraries have been implicated in supply chain attacks akin to Log4j, where compromised dependencies introduce remote code execution paths via deserialization gadgets. For example, vulnerabilities in popular parsers like Jackson have enabled interop exploits in enterprise software, allowing attackers to inject malicious payloads through tainted JSON in third-party packages; CVE-2022-40150 in Jettison exemplifies how unpatched JSON handling in supply chains can lead to widespread DoS propagation.[80] Similarly, the 2025 npm compromise affected ubiquitous libraries, highlighting how attackers target widely used packages to amplify reach across ecosystems.[86] These incidents underscore the risks of JSON interop in automated builds, where flawed parsing in one library cascades to dependent applications.[87]Best Practices
When handling JSON in applications, developers should follow established guidelines to ensure security and robustness, particularly in preventing injection attacks, denial-of-service conditions, and data integrity issues. These practices emphasize validation at every stage of the data lifecycle, from ingestion to transmission, and align with standards from organizations like OWASP and IETF.[88][16] For parsing JSON, enable strict mode in libraries to enforce adherence to the JSON specification, rejecting non-conforming input such as comments or trailing commas that could lead to unexpected behavior.[16] Limit recursion depth and object nesting during deserialization to mitigate resource exhaustion attacks, such as those exploiting deeply nested structures; for example, set a maximum depth of 100 levels in implementations like Java's Jackson library.[88] Always validate parsed JSON against a predefined schema before processing to ensure only expected structures and types are accepted, using tools like JSON Schema to block malicious payloads.[88] Regarding encoding, JSON must be serialized in UTF-8 to promote interoperability, as it is the default and recommended encoding per the specification, avoiding issues with multi-byte characters in other formats.[16] Properly escape special characters in strings, including quotation marks (\"), backslashes (\\), and control characters (via \uXXXX for Unicode), to prevent syntax errors and injection vulnerabilities; libraries like Python's json module or Java's Gson handle this automatically when using standard encode functions.[16] Avoid using user-controlled input as object keys in JSON structures, as this can enable prototype pollution in JavaScript environments or similar issues in other languages; instead, map inputs to predefined keys after validation.[88]
For transmission, especially in APIs, enforce HTTPS with TLS 1.3 to encrypt JSON payloads in transit, protecting against interception and man-in-the-middle attacks.[89] Implement size limits on incoming JSON requests, such as capping payloads at 1 MB, to prevent denial-of-service from oversized inputs.[90] For sensitive data, apply JSON Web Encryption (JWE) to sign and encrypt payloads, ensuring both confidentiality and integrity using algorithms like AES-256-GCM.
In 2025, recommendations for zero-trust environments emphasize treating all JSON inputs as untrusted, even within microservices architectures, by implementing continuous validation and least-privilege access at API gateways.[90] For AI data pipelines, adopt runtime schema enforcement and anomaly detection on JSON flows to isolate potential threats, aligning with cloud-native zero-trust models that verify every request regardless of origin.[91][90]
Related Formats
Alternatives
JSON emerged as a lightweight alternative to XML for data interchange, offering greater brevity through its key-value structure without the need for opening and closing tags that characterize XML's verbosity.[2] XML's tag-based format results in larger payloads, often 2-3 times the size of equivalent JSON for simple objects, making JSON more efficient for bandwidth-constrained environments like web APIs.[92] However, XML provides more mature schema validation via XML Schema Definition (XSD), which enforces stricter data types and constraints compared to JSON Schema, enabling robust validation for complex documents. In terms of use cases, XML dominated enterprise web services pre-2010, particularly in SOAP protocols where its hierarchical structure and extensibility supported intricate messaging patterns in distributed systems.[93] JSON, conversely, gained prominence with RESTful APIs post-2010 due to its simplicity and native integration with JavaScript, reducing parsing overhead in browser-based applications.[94] While XML excels in scenarios requiring detailed hierarchies and formal contracts, such as financial reporting or legacy integrations, JSON's readability and ease of use have made it the default for modern web development, though it lacks XML's built-in support for namespaces and attributes.[95] For tabular data, CSV offers a simpler alternative to JSON, consisting of plain text rows separated by commas with optional headers, ideal for flat datasets like spreadsheets or logs where minimal overhead is prioritized.[96] CSV's lack of nesting limits it to one-dimensional structures, avoiding JSON's overhead for arrays and objects, but it struggles with embedded commas, quotes, or multiline fields without quoting conventions, leading to parsing ambiguities not present in JSON's structured syntax.[96] Thus, CSV suits high-volume, simple exports in tools like Excel, but JSON is preferable when any hierarchy or type safety is needed. Protocol Buffers (Protobuf), developed by Google, provide a binary serialization format as an alternative to JSON, achieving significantly faster serialization and smaller payloads compared to JSON, with benchmarks showing improvements of several times in speed and size depending on the data and implementation.[97] Unlike JSON's human-readable text, Protobuf requires a separate .proto schema file for decoding, sacrificing readability for performance in high-throughput systems like microservices or mobile apps.[98] JSON remains advantageous for debugging and ad-hoc data exchange where inspectability outweighs efficiency, while Protobuf's forward/backward compatibility suits evolving protocols but demands tooling for human interaction. Avro, an Apache project, contrasts with JSON in big data contexts by using binary encoding with embedded JSON schemas, supporting schema evolution that allows adding, removing, or reordering fields without breaking compatibility—essential for Hadoop ecosystems where data pipelines span years. This enables seamless integration in distributed storage like HDFS, where Avro's compact format often results in significantly smaller payloads than JSON (e.g., 40-75% size reduction in benchmarks for large datasets), reducing I/O in big data workflows, though it forgoes JSON's universal readability for schema-centric workflows in analytics.[99] In 2020s Hadoop integrations, Avro's evolution features have made it a staple for dynamic datasets, outperforming JSON in schema-managed environments but requiring upfront schema design absent in JSON's flexibility.Supersets and Derivatives
Supersets of JSON extend its syntax while maintaining backward compatibility, allowing valid JSON to be parsed without modification. These formats address common limitations such as the absence of comments and stricter quoting rules, making them more suitable for human-edited configuration files.[100] JSON5, introduced in 2012, is a prominent superset that adds support for single-line and multi-line comments, trailing commas in arrays and objects, unquoted property names, and additional number formats like hexadecimal and scientific notation. It also permits single-quoted strings and multi-line strings delimited by backticks, enhancing readability for manual editing. For example, a JSON5 document might include:// Configuration file
{
name: 'Example', // Unquoted key with comment
items: [
1,
2, // Trailing comma allowed
]
}
// Configuration file
{
name: 'Example', // Unquoted key with comment
items: [
1,
2, // Trailing comma allowed
]
}
// and multi-line comments using /* */, as well as trailing commas, but retains JSON's requirement for double-quoted keys. VS Code's JSON language mode enables this extension, allowing comments in settings files such as settings.json without validation errors. A common specification defines JSONC as a superset for human-written configs, ensuring compatibility with standard JSON parsers after comment stripping.[102][103]
HOCON (Human-Optimized Config Object Notation), developed as part of the Typesafe Config library, is a superset designed for hierarchical configuration management in JVM applications. It supports JSON syntax while adding features like value substitution (e.g., ${env.VAR}), includes for modular configs, and path expressions for nested access. HOCON files typically use the .conf extension and allow unquoted keys, comments, and multi-line values, making it more concise for complex setups. For instance:
app {
name = "MyApp"
port = ${?PORT:8080} // Substitution with default
}
app {
name = "MyApp"
port = ${?PORT:8080} // Substitution with default
}
#, multi-document streams separated by ---, and additional types like timestamps and binary data, while ensuring all valid JSON is parsable as YAML. YAML's subset compatibility with JSON makes it popular for configuration in tools like Kubernetes and Ansible, though its flexibility can introduce parsing ambiguities if not used carefully. An example YAML equivalent to JSON might be:
name: Example
items:
- 1
- 2
# Comment here
name: Example
items:
- 1
- 2
# Comment here
{
"@context": "https://schema.org",
"@type": "Person",
"name": "John Doe"
}
{
"@context": "https://schema.org",
"@type": "Person",
"name": "John Doe"
}