Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
Code page 866
View on Wikipedia | |
| MIME / IANA | IBM866 |
|---|---|
| Alias(es) | cp866, 866[1] |
| Languages | Russian, Bulgarian; Partial support: Ukrainian,[a] Belarusian[b] |
| Standard | WHATWG Encoding Standard |
| Classification | OEM code page, extended ASCII |
| Extends | US-ASCII |
| Based on | Alternative code page |
| Other related encoding | (See below) |
Code page 866 (CCSID 866)[2] (CP 866, "DOS Cyrillic Russian")[3] is a code page used under DOS and OS/2[4] in Russia to write Cyrillic script.[5][6] It is based on the "alternative code page" (Russian: Альтернативная кодировка) developed in 1984 in IHNA AS USSR and published in 1986 by a research group at the Academy of Science of the USSR.[7] The code page was widely used during the DOS era because it preserves all of the pseudographic symbols of code page 437 (unlike the "Main code page" or Code page 855) and maintains alphabetic order (although non-contiguously) of Cyrillic letters (unlike KOI8-R). Initially this encoding was only available in the Russian version of MS-DOS 4.01 (1990), but with MS-DOS 6.22 it became available in any language version.
The WHATWG Encoding Standard, which specifies the character encodings permitted in HTML5 which compliant browsers must support,[8] includes Code page 866.[9] It is the only single-byte encoding listed which is not named as an ISO 8859 part, Mac OS specific encoding, Microsoft Windows specific encoding (Windows-874 or Windows-125x) or KOI-8 variant.[9] Authors of new pages and the designers of new protocols are instructed to use UTF-8 instead.[10]
A number of variants were used in different Russian territories that had slightly different sets of characters.
Character set
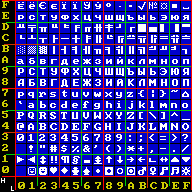
[edit]Each non-ASCII character is shown with its equivalent Unicode code point. The first half (code points 0–127) of this table is the same as that of code page 437.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| 0x | NUL | ☺ 263A |
☻ 263B |
♥ 2665 |
♦ 2666 |
♣ 2663 |
♠ 2660 |
• 2022 |
◘ 25D8 |
○ 25CB |
◙ 25D9 |
♂ 2642 |
♀ 2640 |
♪ 266A |
♫ 266B |
☼ 263C |
| 1x | ► 25BA |
◄ 25C4 |
↕ 2195 |
‼ 203C |
¶ 00B6 |
§ 00A7 |
▬ 25AC |
↨ 21A8 |
↑ 2191 |
↓ 2193 |
→ 2192 |
← 2190 |
∟ 221F |
↔ 2194 |
▲ 25B2 |
▼ 25BC |
| 2x | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | ⌂ 2302 |
| 8x | А 0410 |
Б 0411 |
В 0412 |
Г 0413 |
Д 0414 |
Е 0415 |
Ж 0416 |
З 0417 |
И 0418 |
Й 0419 |
К 041A |
Л 041B |
М 041C |
Н 041D |
О 041E |
П 041F |
| 9x | Р 0420 |
С 0421 |
Т 0422 |
У 0423 |
Ф 0424 |
Х 0425 |
Ц 0426 |
Ч 0427 |
Ш 0428 |
Щ 0429 |
Ъ 042A |
Ы 042B |
Ь 042C |
Э 042D |
Ю 042E |
Я 042F |
| Ax | а 0430 |
б 0431 |
в 0432 |
г 0433 |
д 0434 |
е 0435 |
ж 0436 |
з 0437 |
и 0438 |
й 0439 |
к 043A |
л 043B |
м 043C |
н 043D |
о 043E |
п 043F |
| Bx | ░ 2591 |
▒ 2592 |
▓ 2593 |
│ 2502 |
┤ 2524 |
╡ 2561 |
╢ 2562 |
╖ 2556 |
╕ 2555 |
╣ 2563 |
║ 2551 |
╗ 2557 |
╝ 255D |
╜ 255C |
╛ 255B |
┐ 2510 |
| Cx | └ 2514 |
┴ 2534 |
┬ 252C |
├ 251C |
─ 2500 |
┼ 253C |
╞ 255E |
╟ 255F |
╚ 255A |
╔ 2554 |
╩ 2569 |
╦ 2566 |
╠ 2560 |
═ 2550 |
╬ 256C |
╧ 2567 |
| Dx | ╨ 2568 |
╤ 2564 |
╥ 2565 |
╙ 2559 |
╘ 2558 |
╒ 2552 |
╓ 2553 |
╫ 256B |
╪ 256A |
┘ 2518 |
┌ 250C |
█ 2588 |
▄ 2584 |
▌ 258C |
▐ 2590 |
▀ 2580 |
| Ex | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
| Fx | Ё 0401 |
ё 0451 |
Є 0404 |
є 0454 |
Ї 0407 |
ї 0457 |
Ў 040E |
ў 045E |
° 00B0 |
∙ 2219 |
· 00B7 |
√ 221A |
№ 2116 |
¤ 00A4 |
■ 25A0 |
NBSP 00A0 |
Variants
[edit]There existed a few variants of the code page, but the differences were mostly in the last 16 code points (240–255).
Alternative code page
[edit]The original version of the code page by Bryabrin et al. (1986)[7] is called the "Alternative code page" (Russian: Альтернативная кодировка), to distinguish it from the "Main code page" (Russian: Основная кодировка) by the same authors. It supports only Russian and Bulgarian. It is mostly the same as code page 866, except for codes F2hex through F7hex (which code page 866 changes to Ukrainian and Belarusian letters) and codes F8hex through FBhex (where code page 866 matches code page 437 instead). The differing row is shown below.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Fx | Ё 0401 |
ё 0451 |
🮣 1FBA3 |
🮢 1FBA2 |
🮠 1FBA0 |
🮡 1FBA1 |
→ 2192 |
← 2190 |
↓ 2193 |
↑ 2191 |
÷ 00F7 |
± 00B1 |
№ 2116 |
¤ 00A4 |
■ 25A0 |
NBSP 00A0 |
Modified code page 866
[edit]An unofficial variant with code points 240–255 identical to code page 437. However, the letter Ёё is usually placed at 240 and 241.[17] This version supports only Russian and Bulgarian. The differing row is shown below.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Fx | Ё 0401 |
ё 0451 |
≥ 2265 |
≤ 2264 |
⌠ 2320 |
⌡ 2321 |
÷ 00F7 |
≈ 2248 |
° 00B0 |
∙ 2219 |
· 00B7 |
√ 221A |
ⁿ 207F |
² 00B2 |
■ 25A0 |
NBSP 00A0 |
GOST R 34.303-92
[edit]The GOST R 34.303-92 standard[18] defines two variants, KOI-8 N1 and KOI-8 N2. These are not to be confused with the KOI-8 encoding, which they do not adhere to.
KOI-8 N2
[edit]KOI-8 N2 is the more extensive variant and matches code page 866 and the Alternative code page except for the last row or stick.[c] For this last row, it supports letters for Belarusian and Ukrainian in addition to Russian, but in a layout unrelated to code page 866 or 1125. Notably the Russian Ё/ё (which was unchanged between the Alternative code page and code page 866) is also in a different location. KOI-8 N2's final stick is shown below.[18]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Fx | SHY | № 2116 |
Ґ 0490 |
ґ 0491 |
Ё 0401 |
ё 0451 |
Є 0404 |
є 0454 |
І 0406 |
і 0456 |
Ї 0407 |
ї 0457 |
Ў 040E |
ў 045E |
■ 25A0 |
NBSP 00A0 |
KOI-8 N1
[edit]The other variant, KOI-8 N1, is a subset of KOI-8 N2 which omits the non-Russian Cyrillic letters and mixed single/double lined box-drawing characters, leaving them empty for further internationalization (compare with code page 850). The affected sticks are shown below.[18]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Bx | ░ 2591 |
▒ 2592 |
▓ 2593 |
│ 2502 |
┤ 2524 |
╣ 2563 |
║ 2551 |
╗ 2557 |
╝ 255D |
┐ 2510 | ||||||
| Cx | └ 2514 |
┴ 2534 |
┬ 252C |
├ 251C |
─ 2500 |
┼ 253C |
╚ 255A |
╔ 2554 |
╩ 2569 |
╦ 2566 |
╠ 2560 |
═ 2550 |
╬ 256C |
|||
| Dx | ┘ 2518 |
┌ 250C |
█ 2588 |
▄ 2584 |
▌ 258C |
▐ 2590 |
▀ 2580 | |||||||||
| Ex | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
| Fx | SHY | № 2116 |
Ё 0401 |
ё 0451 |
■ 25A0 |
NBSP 00A0 |
Lithuanian variants
[edit]KBL
[edit]The KBL code page, unofficially known as Code page 771,[19] is the earliest DOS character encoding for Lithuanian.[20] It mostly matches code page 866 and the Alternative code page, but replaces the last row and some block characters with letters from the Lithuanian alphabet not otherwise present in ASCII. The Russian Ё/ё is not supported,[20] similarly to KOI-7.
A modified version, Code page 773, which replaces the Cyrillic letters with Latvian and Estonian letters, also exists.[20]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Dx | ╨ 2568 |
╤ 2564 |
╥ 2565 |
╙ 2559 |
╘ 2558 |
╒ 2552 |
╓ 2553 |
╫ 256B |
╪ 256A |
┘ 2518 |
┌ 250C |
█ 2588 |
Ą 0104 |
ą 0105 |
Č 010C |
č 010D |
| Ex | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
| Fx | Ę 0118 |
ę 0119 |
Ė 0116 |
ė 0117 |
Į 012E |
į 012F |
Š 0160 |
š 0161 |
Ų 0172 |
ų 0173 |
Ū 016A |
ū 016B |
Ž 017D |
ž 017E |
■ 25A0 |
NBSP 00A0 |
LST 1284
[edit]Lithuanian Standard LST 1284:1993, known as Code page 1119 or unofficially as Code page 772,[19] mostly matches the "modified" Code page 866, except for the addition of quotation marks in the last row and the replacement of the mixed single-double box-drawing characters with Lithuanian letters (compare code page 850). Unlike KBL, the Russian Ё/ё is retained.
It accompanies LST 1283 (Code page 774/1118), which encodes the additional Lithuanian letters at the same locations as LST 1284, but is based on Code page 437 instead. It was later superseded by LST 1590-1 (Code page 775),[19] which encodes these Lithuanian letters in the same locations, but does not include Cyrillic letters, replacing them with Latvian and Estonian letters.[20]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Bx | ░ 2591 |
▒ 2592 |
▓ 2593 |
│ 2502 |
┤ 2524 |
Ą 0104 |
Č 010C |
Ę 0118 |
Ė 0116 |
╣ 2563 |
║ 2551 |
╗ 2557 |
╝ 255D |
Į 012E |
Š 0160 |
┐ 2510 |
| Cx | └ 2514 |
┴ 2534 |
┬ 252C |
├ 251C |
─ 2500 |
┼ 253C |
Ų 0172 |
Ū 016A |
╚ 255A |
╔ 2554 |
╩ 2569 |
╦ 2566 |
╠ 2560 |
═ 2550 |
╬ 256C |
Ž 017D |
| Dx | ą 0105 |
č 010D |
ę 0119 |
ė 0117 |
į 012F |
š 0161 |
ų 0173 |
ū 016B |
ž 017E |
┘ 2518 |
┌ 250C |
█ 2588 |
▄ 2584 |
▌ 258C |
▐ 2590 |
▀ 2580 |
| Ex | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
| Fx | Ё 0401 |
ё 0451 |
≥ 2265 |
≤ 2264 |
„ 201E |
“ 201C |
÷ 00F7 |
≈ 2248 |
° 00B0 |
∙ 2219 |
· 00B7 |
√ 221A |
ⁿ 207F |
² 00B2 |
■ 25A0 |
NBSP 00A0 |
Ukrainian and Belarusian variants
[edit]Ukrainian standard RST 2018-91 is designated by IBM as Code page 1125 (CCSID 1125),[25] abbreviated CP1125, and also known as CP866U, CP866NAV or RUSCII.[26] It matches the original Alternative code page for all points except for F2hex through F9hex inclusive, which are replaced with Ukrainian letters.[27] Code page/CCSID 1131[28][29] matches code page 866 for all points except for F8hex, F9hex, and FChex through FEhex inclusive, which are replaced with otherwise-missing Ukrainian and Belarusian letters, in the process displacing the bullet character (∙) from F9hex to FEhex.[30][31] The differing rows are shown below.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Fx | Ё 0401 |
ё 0451 |
Ґ 0490 |
ґ 0491 |
Є 0404 |
є 0454 |
І 0406 |
і 0456 |
Ї 0407 |
ї 0457 |
÷ 00F7 |
± 00B1 |
№ 2116 |
¤ 00A4 |
■ 25A0 |
NBSP 00A0 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Fx | Ё 0401 |
ё 0451 |
Є 0404 |
є 0454 |
Ї 0407 |
ї 0457 |
Ў 040E |
ў 045E |
І 0406 |
і 0456 |
· 00B7 |
¤ 00A4 |
Ґ 0490 |
ґ 0491 |
∙ 2219 |
NBSP 00A0 |
Also, the so-called CP 866ukr code page is a modified version of CP866 with the replacement of Ўў by Іі. Unlike CP1125, it maintains full compatibility of Ukrainian letters with CP866, although Ґґ is missing. It is not included in the standard Windows distributions, but some users install a home-made patch[38] that allows using this encoding to work in command-line programs (such as FAR Manager) with filenames containing the Cyrillic Іі.
Hryvnia variants
[edit]FreeDOS code page 30040 is a variant of code page 866 which replaces the currency sign (¤) at byte 0xFD with the hryvnia sign (₴, U+20B4).
FreeDOS code page 30039 is a variant of code page 1125 which makes the same replacement.
Euro sign updates
[edit]IBM code page/CCSID 808 is a variant of code page/CCSID 866; with the euro sign (€, U+20AC) in position FDhex, replacing the universal currency sign (¤).[39][40][41]
IBM code page/CCSID 848 is a variant of code page/CCSID 1125 with the euro sign at FDhex, replacing ¤.[42][43][44]
IBM code page/CCSID 849 is a variant of code page/CCSID 1131 with the euro sign at FBhex, replacing ¤.[45][46][47]
Lehner–Czech modification
[edit]An unofficial modification used in software developed by Michael Lehner and Peter R. Czech. It replaces three mathematic symbols with guillemets and the section sign which are commonly used in the Russian language. (Lehner and Czech created a number of alternative character sets for other European languages as well, including one based on CWI-2 for Hungarian, a Kamenicky-based one for Czech and Slovak, a Mazovia variant for Polish and a seemingly-unique encoding for Lithuanian. The modified row is shown below.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Fx | Ё 0401 |
ё 0451 |
Є 0404 |
є 0454 |
Ї 0407 |
ї 0457 |
Ў 040E |
ў 045E |
» 00BB |
« 00AB |
· 00B7 |
§ 00A7 |
№ 2116 |
¤ 00A4 |
■ 25A0 |
NBSP 00A0 |
Latvian variant
[edit]A Latvian variant, supported by Star printers and FreeDOS, is code page 3012 (earlier FreeDOS called it code page 61282). This encoding is nicknamed "RusLat".[48]
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| Bx | ░ 2591 |
▒ 2592 |
▓ 2593 |
│ 2502 |
┤ 2524 |
Ā 0100 |
╢ 2562 |
ņ 0146 |
╕ 2555 |
╣ 2563 |
║ 2551 |
╗ 2557 |
╝ 255D |
Ō 014C |
╛ 255B |
┐ 2510 |
| Cx | └ 2514 |
┴ 2534 |
┬ 252C |
├ 251C |
─ 2500 |
┼ 253C |
ā 0101 |
╟ 255F |
╚ 255A |
╔ 2554 |
╩ 2569 |
╦ 2566 |
╠ 2560 |
═ 2550 |
╬ 256C |
╧ 2567 |
| Dx | Š 0160 |
╤ 2564 |
č 010D |
Č 010C |
╘ 2558 |
╒ 2552 |
ģ 0123 |
Ī 012A |
ī 012B |
┘ 2518 |
┌ 250C |
█ 2588 |
▄ 2584 |
ū 016B |
Ū 016A |
▀ 2580 |
| Ex | р 0440 |
с 0441 |
т 0442 |
у 0443 |
ф 0444 |
х 0445 |
ц 0446 |
ч 0447 |
ш 0448 |
щ 0449 |
ъ 044A |
ы 044B |
ь 044C |
э 044D |
ю 044E |
я 044F |
| Fx | Ē 0112 |
ē 0113 |
Ģ 0122 |
ķ 0137 |
Ķ 0136 |
ļ 013C |
Ļ 013B |
ž 017E |
Ž 017D |
ō 014D |
· 00B7 |
√ 221A |
Ņ 0145 |
š 0161 |
■ 25A0 |
NBSP 00A0 |
FreeDOS
[edit]FreeDOS provides additional unofficial extensions of code page 866 for various non-Slavic languages:[49]
- 30002 – Cyrillic Tajik
- 30008 – Cyrillic Abkhaz and Ossetian
- 30010 – Cyrillic Gagauz and Moldovan
- 30011 – Cyrillic Russian Southern District (Kalmyk, Karachay-Balkar, Ossetian, North Caucasian)
- 30012 – Cyrillic Russian Siberian and Far Eastern Districts (Altai, Buryat, Khakas, Tuvan, Yakut, Tungusic, Paleo-Siberian)
- 30013 – Cyrillic Volga District – Turkic languages (Bashkir, Chuvash, Tatar)
- 30014 – Cyrillic Volga District – Finno-Ugric languages (Mari, Udmurt)
- 30015 – Cyrillic Khanty
- 30016 – Cyrillic Mansi
- 30017 – Cyrillic Northwestern District (Cyrillic Nenets, Latin Karelian, Latin Veps)
- 30018 – Latin Tatar and Cyrillic Russian
- 30019 – Latin Chechen and Cyrillic Russian
- 58152 – Cyrillic Kazakh with euro
- 58210 – Cyrillic Azeri
- 59234 – Cyrillic Tatar
- 60258 – Latin Azeri and Cyrillic Russian
- 62306 – Cyrillic Uzbek
Code page 900
[edit]Before Microsoft's final code page for Russian MS-DOS 4.01 was registered with IBM by Franz Rau of Microsoft as CP866 in January 1990, draft versions of it developed by Yuri Starikov (Юрий Стариков) of Dialogue were still called code page 900 internally. While the documentation was corrected to reflect the new name before the release of the product, sketches of earlier draft versions still named code page 900 and without Ukrainian and Belarusian letters, which had been added in autumn 1989, were published in the Russian press in 1990.[50] Code page 900 slipped through into the distribution of the Russian MS-DOS 5.0 LCD.CPI codepage information file.[51]
Notes
[edit]- ^ Includes distinctly Ukrainian and Rusyn letters Є and Ї, but no І distinct from Latin I, and implements Soviet orthography, i.e. omits Ґ. These are added in some modifications.
- ^ Includes uniquely Belarusian Ў, but no І distinct from Latin I (although this is added in some modifications).
- ^ i.e. codes 240 through 255, or F0hex through FFhex
References
[edit]- ^ Character Sets, Internet Assigned Numbers Authority (IANA), 2018-12-12
- ^ "CCSID 866 information document". Archived from the original on 2016-03-27.
- ^ a b Steele, Shawn (1996-04-24). "CP866.TXT: cp866_DOSCyrillicRussian to Unicode table". Unicode Consortium.
- ^ "OS/2" (in Russian). Archived from the original on 2016-08-13. Retrieved 2016-06-19.
- ^ a b "Code page 866 information document". Archived from the original on 2016-03-16.
- ^ "Code Pages Supported by Windows: OEM Code Pages". Go Global Development Center. Microsoft. Archived from the original on 2011-11-02. Retrieved 2011-10-11.
- ^ a b (in Russian) Брябрин В. М., Ландау И. Я., Неменман М. Е. О системе кодирования для персональных ЭВМ // Микропроцессорные средства и системы. — 1986. — № 4. — С. 61–64.
- ^ "8.2.2.3. Character encodings". HTML 5.1 2nd Edition. W3C.
User agents must support the encodings defined in the WHATWG Encoding standard, including, but not limited to […]
- ^ a b van Kesteren, Anne. "Legacy single-byte encodings". Encoding Standard. WHATWG.
- ^ van Kesteren, Anne. "Names and labels". Encoding Standard. WHATWG.
- ^ "OEM 866". Go Global Development Center. Microsoft. Archived from the original on 2012-02-04. Retrieved 2011-10-17.
- ^ van Kesteren, Anne (2018-01-06). "Index index-ibm866". Encoding Standard. WHATWG.
- ^ Code Page CPGID 00866 (pdf) (PDF), IBM
- ^ Code Page CPGID 00866 (txt), IBM
- ^ International Components for Unicode (ICU), ibm-866_P100-1995.ucm, 2002-12-03
- ^ (in Russian) Брябрин В. М., Ландау И. Я., Неменман М. Е. О системе кодирования для персональных ЭВМ // Микропроцессорные средства и системы. — 1986. — № 4. — С. 64.
- ^ (in Russian) Фигурнов В. Э. IBM PC для пользователя. — 2-е изд. — М.: 1992. — С. 279.
- ^ a b c (in Russian) ГОСТ Р 34.303-92. Наборы 8-битных кодированных символов. 8-битный код обмена и обработки информации. = 8-bit coded character sets. 8-bit code for information interchange.
- ^ a b c "Codepages: Comprehensive list". Aivosto.
- ^ a b c d "Rašmenų koduotės". Lietuvių kalba informacinėse technologijose (in Lithuanian).
- ^ "771 kodų lentelė" (in Lithuanian). Likit.
- ^ "771 kodų lentelė". Lietuvių kalba informacinėse technologijose – Rašmenų koduotės (in Lithuanian).
- ^ "772 kodų lentelė" (in Lithuanian). Likit.
- ^ "772 kodų lentelė". Lietuvių kalba informacinėse technologijose – Rašmenų koduotės (in Lithuanian).
- ^ "CCSID 1125 information document". Archived from the original on 2014-12-02.
- ^ Nechayev, Valentin (2013) [2001]. "Review of 8-bit Cyrillic encodings universe". Archived from the original on 2016-12-05.
- ^ a b Code Page CPGID 01125 (pdf) (PDF), IBM
- ^ "CCSID 1131 information document". Archived from the original on 2016-03-27.
- ^ "Code page 1131 information document". Archived from the original on 2016-03-17.
- ^ IBM. "Code page identifiers: CP 01131". IBM Globalization. Archived from the original on 2016-03-17.
- ^ IBM. "Code Page 01131" (PDF). Archived (PDF) from the original on 2015-07-08.
- ^ Code Page CPGID 01125 (txt), IBM
- ^ International Components for Unicode (ICU), ibm-1125_P100-1997.ucm, 2002-12-03
- ^ (in Ukrainian) РСТ УРСР 2018-91. Система обробки інформації. Кодування символів української абетки 8-бітними кодами.
- ^ Code Page CPGID 01131 (pdf) (PDF), IBM
- ^ Code Page CPGID 01131 (txt), IBM
- ^ International Components for Unicode (ICU), ibm-1131_P100-1997.ucm, 2002-12-03
- ^ "Linux Wine + Far2l Ukrainian cp866".
- ^ "CCSID 808 information document". Archived from the original on 2014-12-01.
- ^ Code Page CPGID 00808 (pdf) (PDF), IBM
- ^ Code Page CPGID 00808 (txt), IBM
- ^ "CCSID 848 information document". Archived from the original on 2014-12-01.
- ^ Code Page CPGID 00848 (pdf) (PDF), IBM
- ^ Code Page CPGID 00848 (txt), IBM
- ^ "CCSID 849 information document". Archived from the original on 2016-03-26.
- ^ Code Page CPGID 00849 (pdf) (PDF), IBM
- ^ Code Page CPGID 00849 (txt), IBM
- ^ "LC-8021 Dot Matrix Printer, User's Manual" (PDF). Archived from the original (PDF) on 2020-09-29. Retrieved 2020-05-13.
- ^ "CPIDOS - CPX files (Code Page Information) Pack v3.0 - DOS codepages". FreeDOS. Archived from the original on 2018-05-12. Retrieved 2018-01-30.
- ^ Starikov, Yuri (2005-04-11). "15-летию Russian MS-DOS 4.01 посвящается" [15 Years of Russian MS-DOS 4.01] (in Russian). Archived from the original on 2016-12-04. Retrieved 2014-05-07.
- ^ Paul, Matthias R. (2001-06-10) [1995]. "Overview on DOS, OS/2, and Windows codepages" (CODEPAGE.LST file) (1.59 preliminary ed.). Archived from the original on 2016-04-20. Retrieved 2016-08-20.
{kind=link}
{kind=link}
{kind=link}
Further reading
[edit]- Kornai, Andras; Birnbaum, David J.; da Cruz, Frank; Davis, Bur; Fowler, George; Paine, Richard B.; Paperno, Slava; Simonsen, Keld J.; Thobe, Glenn E.; Vulis, Dimitri; van Wingen, Johan W. (1993-03-13). "CYRILLIC ENCODING FAQ Version 1.3". 1.3. Retrieved 2020-06-04.
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |
Code page 866
View on GrokipediaHistory and Development
Origins in Soviet Standards
Code page 866 emerged from Soviet initiatives to adapt IBM PC-compatible systems for Cyrillic script during the mid-1980s. Its development took place at the Computing Centre of the Academy of Sciences of the USSR (VTS AN SSSR), led by V. M. Bryabrin and collaborators, as part of efforts to create a localized encoding for personal computers in the Eastern Bloc. In 1986, the encoding was formally proposed as a standard for Cyrillic representation in PC systems through a publication in the Soviet technical journal Mikroprocessornye Sredstva i Systemy (Microprocessor Tools and Systems). The article "O sisteme kodirovaniya dlya personal'nykh EVM" (On the Encoding System for Personal Computers) by V. M. Bryabrin, I. Ya. Landau, and M. E. Nemenman outlined the design, which initially supported the alphabets of Russian and Bulgarian exclusively.[8][9] Microsoft registered this 1986 proposal as CCSID 866 in 1990, preserving its focus on Russian and Bulgarian character sets for compatibility with international systems.[10] A pivotal milestone occurred with its integration into early drafts of the Russian version of MS-DOS 4.01 that year, marking the transition from Soviet prototyping to broader adoption in operating systems.[11] This laid the groundwork for its later use in DOS environments beyond the USSR.Adoption in MS-DOS and OS/2
Code page 866 made its debut in the Russian language version of MS-DOS 4.01, released in 1990, where it served as the primary encoding for Cyrillic text support. This introduction marked Microsoft's official endorsement of the code page, positioning it as the standard for Russian DOS environments and enabling localization for Soviet users. By MS-DOS 6.22 in 1994, support for Code page 866 had become widespread, with general integration across international versions to facilitate broader Cyrillic compatibility in console applications and text files.[5] A key design choice in Code page 866 was the preservation of Code page 437's box-drawing characters in the upper half (codes 176–223), ensuring backward compatibility with legacy DOS software that relied on these pseudographic symbols for user interfaces, while reassigning the lower extended range for Cyrillic letters. This feature contributed to its rapid adoption, as it avoided disrupting existing graphical elements in programs like text editors and games.[12] In OS/2, Code page 866 was implemented for Russian localization beginning with version 2.0 in April 1992, providing comprehensive support for Cyrillic in both console sessions and file systems. Console output was handled through EGA.CPI font files tailored for the code page, while file system operations, including keyboard input and text storage, were enabled via layouts in KEYBOARD.SYS, allowing seamless handling of Russian text in multilingual environments.[10]Encoding Structure
Relation to ASCII and Code Page 437
Code page 866 maintains full compatibility with US-ASCII in its lower 128 code points, mapping bytes 0x00 through 0x7F to the standard ASCII control characters and basic Latin letters, identical to those defined in the American National Standards Institute's ANSI X3.4-1986 specification.[13] This design ensures that English-language DOS applications and files remain readable without alteration in Cyrillic-localized environments.[5] In the upper half (0x80 through 0xFF), code page 866 builds upon the structure of code page 437—the original IBM PC character set—by substituting many of its pseudographic block elements and symbols with Cyrillic letters to support Russian text, while preserving key compatibility features. Specifically, positions 0x80–0x9F and 0xA0–0xAF (along with 0xE0–0xEF) are allocated to uppercase and lowercase Cyrillic characters, respectively, displacing the diverse icons and line-drawing elements found in code page 437's equivalent range. However, the code page retains the pseudographic block from 0xB0 to 0xDF directly from code page 437, including characters such as light shade (0xB0, U+2591), box drawings light vertical (0xB3, U+2502), and double line horizontal (0xC3, U+2550), to support legacy text-mode user interfaces that relied on these for borders and shading.[13][5] Positions 0xF0–0xFF diverge more significantly, incorporating additional Cyrillic letters like capital IO (0xF0, U+0401) alongside symbols such as the degree sign (0xF8, U+00B0), rather than fully mirroring code page 437's Greek-derived and mathematical symbols in that range.[13] A notable aspect of this extension is the non-contiguous placement of Cyrillic letters, with uppercase forms grouped in 0x80–0x9F and lowercase split between 0xA0–0xAF and 0xE0–0xEF, interrupting the alphabetic sequence with the preserved pseudographic block at 0xB0–0xDF. This arrangement prioritizes positional compatibility with code page 437's fixed locations for graphics over a linguistically sequential layout, allowing mixed Latin-Cyrillic applications to function without remapping display routines.[5][13] The encoding's design as IBM's Coded Character Set Identifier (CCSID) 866 formalizes this backward compatibility for English DOS environments, registering it as "IBM PC Cyrillic Russian (code page 866)" to enable seamless integration in multilingual IBM systems like OS/2.[14]Core Character Mapping
Code page 866 defines a complete 8-bit character set with 256 code points, where the first 128 positions (0x00 to 0x7F) map directly to the ASCII standard, including control characters and printable Latin symbols.[13] The extended range from 0x80 to 0xFF is primarily allocated to Cyrillic characters, graphics symbols, and legacy elements inherited from earlier code pages, enabling support for text-based interfaces in DOS environments. This mapping was standardized by IBM and Microsoft for Russian-language systems, with the official table documented in Microsoft's submission to the Unicode Consortium.[13] In the upper half (0x80–0xFF), 66 positions are dedicated to the Russian Cyrillic alphabet, covering uppercase (А–Я, including Ё at 0xF0 as U+0401) and lowercase (а–я, including ё at 0xF1 as U+0451) letters, which together form the 33 letters per case with Ё/ё as distinct additions beyond the standard 32-letter set.[13] Gaps in this Cyrillic block are filled with additional symbols, such as mathematical operators and punctuation, while positions 0xB0–0xDF retain box-drawing characters from Code page 437, like light horizontal line (─ at 0xC4, U+2500) and vertical line (│ at 0xB3, U+2502), facilitating terminal graphics.[13] Representative mappings illustrate the structure:| Byte | Character | Unicode Code Point | Description |
|---|---|---|---|
| 0x80 | А | U+0410 | Cyrillic capital letter A |
| 0x81 | Б | U+0411 | Cyrillic capital letter Be |
| 0xAF | п | U+043F | Cyrillic small letter Pe |
| 0xB0 | ░ | U+2591 | Light shade |
| 0xC4 | ─ | U+2500 | Box drawings light horizontal |
| 0xE0 | р | U+0440 | Cyrillic small letter er |
| 0xE1 | с | U+0441 | Cyrillic small letter Es |
| 0xF0 | Ё | U+0401 | Cyrillic capital letter Io |
| 0xF1 | ё | U+0451 | Cyrillic small letter Io |
| 0xFF | U+00A0 | No-break space |
Supported Languages and Scripts
Primary Support for Russian and Bulgarian
Code page 866 offers full native support for the Russian language by encoding all 33 letters of the Russian Cyrillic alphabet, including both uppercase (А–Я) and lowercase (а–я) forms, with dedicated positions for the unique letter Ё/ё.[13] Uppercase letters occupy codes 0x80–0x9F in alphabetic order from А (0x80) to Я (0x9F), while lowercase letters are mapped across 0xA0–0xAF (а–щ) and 0xE0–0xEF (р–я), with ё at 0xF1.[3] This arrangement ensures seamless representation of Russian text in legacy computing environments, such as MS-DOS consoles, where the encoding was standardized for Cyrillic output.[1] For Bulgarian, the encoding provides comprehensive coverage of the 30-letter Bulgarian Cyrillic alphabet, which excludes Ё/ё and Ы/ы but includes the hard sign Ъ/ъ.[13] All required characters—uppercase from А (0x80) to Щ (0x99) and Ъ (0x9A), and corresponding lowercase forms—are present, allowing full orthographic representation without substitutions.[3] This support aligns with the encoding's alphabetic sequencing in the upper byte range (0x80–0xFF), which prioritizes sequential access for Cyrillic scripts in text-based applications.[1] The design of Code page 866 emphasizes alphabetic order for its Cyrillic mappings, differing from earlier standards like GOST or KOI-8 that followed typewriter keyboard layouts; this facilitates efficient sorting and display in console and early word processing software.[3] However, it lacks dedicated code points for certain characters outside core Russian and Bulgarian usage, such as the Ukrainian or Belarusian short i (і/І), which must be approximated or omitted in standard implementations.[13]Partial Coverage for Other Cyrillic Languages
Code page 866 offers limited support for Cyrillic languages beyond Russian and Bulgarian, with only a handful of additional character positions allocated for select letters from other scripts, resulting in significant gaps that require approximations or substitutions using existing Russian mappings. While the encoding fully covers the 33-letter alphabets of Russian and Bulgarian through its core 66 dedicated Cyrillic positions, these extras fall short for comprehensive representation in secondary languages.[3] In Ukrainian, key letters such as і/І (U+0406/U+0456) and ґ/Ґ (U+0490/U+0491) are absent, forcing users to approximate them with visually similar Russian characters like и/И or omit them entirely; dedicated positions exist for other Ukrainian-specific letters like Є/є at 0xF2/0xF3 and Ї/ї at 0xF4/0xF5.[3] Belarusian coverage is similarly incomplete, lacking positions for і/І (U+0406/U+0456), with text often relying on Russian equivalents despite shared characters; it includes ў/Ў (U+040E/U+045E) at 0xF6/0xF7 for the full 32-letter alphabet.[3] Support for additional Cyrillic scripts is even more restricted. Serbian receives partial accommodation through the base mappings but omits đ/Đ (equivalent to Ђ/ђ, U+0402/U+0452), essential for its 30-letter orthography. Macedonian fares worse, with incomplete diacritics and missing letters such as those for gj (Ѓ/ѓ, U+0403/U+0453) and kj (Ќ/ќ, U+040C/U+045C), limiting accurate rendering of its unique phonetic requirements.[3] Overall, the 66 core Cyrillic positions prioritize Russian and Bulgarian, proving insufficient for seamless multi-language use and highlighting the encoding's design focus on primary Soviet-era needs.[3]Variants and Extensions
Alternative and Modified Code Page 866
The alternative version of Code page 866, introduced in 1986 as part of Soviet efforts to adapt IBM PC-compatible systems for Cyrillic text, supported only Russian and Bulgarian languages and featured a distinct mapping in the 0xF0–0xFF range that diverged from Code Page 437 by incorporating mathematical symbols such as arrows and division signs instead of graphical elements.[15] This design choice prioritized additional typographic characters over visual compatibility with Western PC interfaces.[16] In contrast, the modified version of Code page 866 realigned the 0xF0–0xFF range to match the box-drawing and line-drawing characters of Code Page 437, while relocating the Russian letters Ё (uppercase) to 0xF0 and ё (lowercase) to 0xF1 to accommodate these pseudographics without displacing core Cyrillic mappings.[15] This adjustment enhanced rendering of user interfaces and ASCII art in DOS environments.[16] The modified variant emerged as the de facto standard starting with MS-DOS 5.0 in 1991, offering superior graphics compatibility for applications reliant on box-drawing elements, such as early text-based software and games.[5] Key differences between the versions include the alternative's omission of certain graphical symbols in favor of extra mathematical notations, whereas the modified emphasized pseudographics at the expense of some less common letters, reflecting a trade-off for broader hardware interoperability.[15]GOST R 34.303-92 and KOI-8 Subsets
GOST R 34.303-92, published in 1992 by the Russian Federal Agency for Technical Regulating and Metrology, establishes sets of 8-bit coded symbols for information exchange and processing, aligning encodings like Code Page 866 with national requirements for Cyrillic script in computing systems.[17] This standard formalizes character mappings to support Russian text handling in DOS-based environments and government applications, ensuring compatibility with Soviet-era conventions while adapting to IBM/Microsoft implementations.[17] Within GOST R 34.303-92, KOI-8 N1 defines a Russian-only 8-bit subset, remapping characters from Code Page 866 for compatibility with traditional KOI-8 structures, such as shifting positions of non-Russian Cyrillic letters like those used in Ukrainian to prioritize the 33 Russian alphabet characters.[17] This variant excludes pseudographic elements, focusing solely on alphabetic, numeric, and punctuation symbols essential for Russian-language processing.[17] KOI-8 N2 extends KOI-8 N1 as a superset, incorporating Belarusian and Ukrainian letters such as і (uppercase І), і (lowercase і), and ў by reassigning positions previously occupied by symbols in Code Page 866, thereby adding four extra characters at the expense of box-drawing pseudographics.[17] These modifications enable broader Cyrillic coverage without expanding beyond 8 bits, supporting official use in Russian government systems for multilingual Slavic text.[17]Lithuanian and KBL/LST 1284 Variants
The Lithuanian and KBL/LST 1284 variants of Code page 866 represent adaptations designed to accommodate the Lithuanian language's Latin script with diacritics in MS-DOS environments, particularly during the early post-Soviet era of localization for Baltic computing systems. These variants modify the standard Code page 866 structure by reallocating positions in the upper code point range (128–255) to prioritize Lithuanian characters, while retaining some Cyrillic support for compatibility with Russian influences in the region. Developed in the early 1990s, they addressed the need for native language support in DOS-based software following Lithuania's independence in 1990, focusing on post-Soviet transition to Latin orthography over extensive Cyrillic coverage.[18][19] The KBL variant, designated as Code page 771, is the earliest known DOS encoding tailored for Lithuanian. It replaces several Russian Cyrillic letters in the upper half of Code page 866 with essential Lithuanian diacritics, including ą (a with ogonek), č (c with caron), and ė (e with dot above), enabling basic text rendering in Lithuanian applications. This unofficial code page, also referred to as KBL after its developing Lithuanian software efforts, was employed in initial Lithuanian-localized editions of MS-DOS to facilitate software distribution in the Baltic states. While it maintains partial Cyrillic compatibility for mixed-language use, its primary emphasis is on Latin extensions to support Lithuanian typography without requiring full script overhauls.[18][17] The LST 1284 variant, formalized as the Lithuanian national standard LST 1284:1993 and implemented by IBM as Code page 1119 (with an earlier unofficial designation as Code page 772), builds upon similar principles but offers a more standardized approach. Intended for MS-DOS usage, it supplements the 8-bit Latin alphabet with additional Lithuanian letters such as ę (e with ogonek), į (i with ogonek), š (s with caron), and ũ (u with tilde), while omitting certain Cyrillic characters to allocate space for these diacritics. This encoding supports both Lithuanian and limited Russian alphabets, reflecting its purpose in multilingual Baltic DOS systems, but it was later superseded by the more comprehensive Code page 775 for broader Baltic language coverage. The standard's development in 1993 underscores its role in formalizing localization efforts for emerging independent computing infrastructures.[19][18][17] Both variants differ from the core Code page 866 by de-emphasizing full Cyrillic sets in favor of Lithuanian-specific Latin extensions, a deliberate choice for efficient localization in resource-constrained DOS environments where complete multilingual support was impractical. This prioritization enabled practical text handling in software, documents, and interfaces for Lithuanian users, though they were eventually phased out in favor of Unicode-based standards.[17]Ukrainian, Belarusian, and Hryvnia Variants
Code page 866 variants emerged in the mid-1990s to address the specific needs of Ukrainian and Belarusian in post-Soviet computing environments, extending the base encoding for better Cyrillic support in DOS and OS/2 systems. These adaptations remapped certain byte positions to accommodate language-specific characters while preserving compatibility with the core Russian-focused layout where possible. The Ukrainian variant, designated as IBM Code page 1125 (also known as CP866U, RUSCII, or x-cp866-u), follows the Ukrainian government standard RST 2018-91 for DOS environments. It is based on the alternative Cyrillic encoding but diverges from standard Code page 866 in bytes 0xF2 through 0xF9 to properly define Ukrainian-specific letters, including і/І (Cyrillic small/capital i with dot) and ґ/Ґ (Cyrillic small/capital ghe with upturn), which were absent or misrepresented in the original CP866. This remapping enabled full orthographic support for Ukrainian text processing, though it introduced incompatibilities that occasionally led to display issues when mixed with standard CP866 files.[16] For Belarusian, IBM Code page 1131 (ibm-1131_P100-1997) provides dedicated support as a PC data encoding for Cyrillic Belarusian in OS/2 and related systems. It incorporates essential characters such as ў/Ў (short u with breve) and the short ъ (hard sign), which are integral to Belarusian orthography but not fully represented in base CP866. This variant maintains the overall structure of CP866 while prioritizing these additions for accurate representation in legacy applications.[20] Hryvnia variants address the need for the Ukrainian currency symbol ₴ (U+20B4) in code page 866 derivatives, particularly following the official adoption of the symbol design in 2004 via a contest organized by the National Bank of Ukraine. In FreeDOS, code page 30040 (Russian-focused) and code page 30039 (Ukrainian-focused) modify CP866 by replacing the currency sign ¤ at byte 0xFD with ₴, facilitating its use in financial and keyboard input contexts for Ukrainian systems. These updates were integrated into FreeDOS keyboard layouts around 2011 to enhance compatibility with post-2004 currency representations.[21][22]Euro Sign and IBM Updates (808, 848, 849)
IBM developed code pages 808, 848, and 849 as extensions to support the Euro sign (U+20AC) in Cyrillic encodings, primarily for legacy DOS and OS/2 systems in regions using Cyrillic scripts. These variants were introduced between 1999 and 2002 to facilitate compatibility with the Eurozone's economic integration, aligning with the European Central Bank's launch of the euro as an electronic currency on January 1, 1999.[23][24] The additions targeted international environments where Cyrillic-speaking countries required updated character sets for financial and business applications without disrupting existing data handling. Code page 808 serves as the Euro-enabled variant of code page 866 for Russian Cyrillic, incorporating the Euro sign at byte position 0xFD by replacing the international currency symbol (¤).[24] Similarly, code page 848 extends code page 1125 for Ukrainian Cyrillic, and code page 849 extends code page 1131 for Belarusian Cyrillic, with 808 and 848 mapping the Euro sign to 0xFD in place of the currency symbol, while 849 maps it to 0xFB in place of another symbol.[25][26] These modifications ensured minimal changes to the core Russian character mappings in 808 while providing tailored support for Ukrainian and Belarusian scripts in 848 and 849, respectively; further refinements in 848 and 849 accommodate variations seen in related Cyrillic languages such as Bulgarian and Serbian through shared symbol adjustments.[25] The updates had limited impact on the fundamental Russian Cyrillic repertoire of code page 866, preserving compatibility for existing Russian-language software and data in OS/2 environments.[24] By integrating the Euro sign without extensive remapping, IBM enabled seamless adoption in Eurozone-adjacent Cyrillic regions, supporting applications in banking and international trade during the euro's rollout phase from 1999 onward.[23]Lehner–Czech, Latvian, and FreeDOS Modifications
The Lehner–Czech modification is an unofficial variant of the alternative Code page 866. It replaces certain mathematical symbols in the 0xF0–0xFF range with guillemets (‹ and ›) and the section sign (§) to enhance support for Russian typography in text processing. The Latvian modification to code page 866, designated as code page 3012 and nicknamed "RusLat," creates a hybrid encoding suitable for Latvian text within a primarily Cyrillic framework. This variant adds support for key Latvian Latin characters, including ā, č, ē, ģ, ī, ņ, š, ū, and ž, by remapping positions in the upper code page range while retaining core Russian Cyrillic glyphs. Developed as an extension for DOS systems handling mixed-language environments, it enables the display and input of Latvian content in applications originally designed for Russian. The FreeDOS project officially documents code page 3012 as "Cyrillic Russian and Latvian (RusLat)" in its code page information package, facilitating its use in open-source DOS implementations.[27] FreeDOS, an open-source replacement for MS-DOS, extends code page 866 through dedicated variants to enhance compatibility with legacy software and modern emulators. A prominent example is code page 30040, which modifies the standard 866 layout by replacing the international currency sign (¤) at byte 0xFD with the Hryvnia symbol (₴, U+20B4), addressing needs in Ukrainian and Russian financial or textual contexts. This update integrates elements from prior national variants, including Latvian extensions, to support diverse Cyrillic-based applications. Originating in the 2000s as part of FreeDOS's efforts to preserve DOS-era gaming and productivity software, code page 30040 is distributed via the project's CPI files pack and utilized in emulators like DOSBox for accurate rendering of historical content.[27] These modifications reflect adaptations for niche regional requirements beyond standard IBM code pages, prioritizing typography and currency symbols in open-source and localized DOS environments. While Latvian and Hryvnia extensions are well-integrated into FreeDOS tools, they maintain backward compatibility with original code page 866 structures for seamless operation in constrained 8-bit systems.[27]Related Code Pages
Code Page 900 as Predecessor
Code Page 900 was an internal draft name used by Microsoft for early versions of the character encoding proposed for the Russian language version of MS-DOS 4.01, serving as the direct precursor to the finalized Code Page 866.[28] This draft was limited to support for Russian and Bulgarian, excluding characters needed for Ukrainian and Belarusian languages.[29] In terms of character mapping, Code Page 900 was similar to an alternative variant of Code Page 866 but lacked certain symbols, with the upper half of the code space (0x80-0xFF) dedicated entirely to Cyrillic characters. It was used briefly in 1989-1990 prototypes but ultimately abandoned in favor of Code Page 866 to achieve better compatibility and alignment with Code Page 437's structure for box-drawing and other graphics characters. Compared to the final Code Page 866, it included fewer box-drawing characters, prioritizing basic Cyrillic text rendering over extended graphical elements.[5]Comparisons with Other Cyrillic Encodings
Code page 866 (CP866), designed for DOS and OS/2 environments, differs from KOI8-R primarily in its allocation of byte values and inclusion of non-text characters. KOI8-R places the 32 Cyrillic letters in 0xC0–0xDF and 0xE0–0xFF in phonetic order corresponding to keyboard layout, with uppercase and lowercase positions swapped between the two ranges, and includes some box-drawing characters in 0xA0–0xAF, focusing on text-only encoding for Unix systems.[30][31] In contrast, CP866 scatters Cyrillic mappings across 0x80–0x9F for uppercase and 0xA0–0xAF plus other ranges for lowercase (e.g., 0xE0–0xEB, 0xEC–0xEF for remaining lowercase), reserving space for pseudographic symbols like box-drawing characters in positions such as 0xB0–0xDF and 0xF0–0xFF.[3] This results in no direct byte-level compatibility for Cyrillic text between the two, as a byte like 0xE1 maps to uppercase 'А' in KOI8-R but to a box-drawing horizontal line in CP866.[31][3] KOI8-R's phonetic layout, where letters are ordered by keyboard position rather than alphabetical sequence, further contrasts with CP866's more alphabetical but interrupted arrangement to accommodate legacy IBM graphics.[30] In comparison to Windows-1251, an 8-bit encoding for Microsoft Windows supporting a broader range of Cyrillic languages, CP866 prioritizes DOS-specific features over extended character support. Windows-1251 places core Cyrillic uppercase letters contiguously from 0xC0 to 0xFF and lowercase from 0xE0 to 0xFF, including additional symbols like the Serbian 'Ђ' at 0x80, while CP866 dedicates much of its upper range to 128 pseudographic characters for text-mode interfaces, limiting it to basic Russian Cyrillic plus Ё.[1][3] A key incompatibility arises at position 0xA0, where CP866 encodes lowercase 'а', but Windows-1251 uses it for the non-breaking space (U+00A0), leading to garbled text if misinterpreted.[3] Windows-1251 also supports variable-width fonts and more punctuation, making it unsuitable for direct substitution in CP866-based legacy applications without conversion.[1] CP866 shares structural similarities with ISO/IEC 8859-5 as single-byte encodings for Cyrillic scripts but diverges in character allocation and supplementary features. ISO 8859-5 maps Cyrillic characters to 0xA1–0xFF in a near-alphabetical order, including Ё at 0xA1 (uppercase) and 0xF1 (lowercase), with 0xA0 reserved for non-breaking space, whereas CP866 integrates pseudographics into the Cyrillic range, such as line-drawing elements at 0xB0–0xDF, and positions Ё separately at 0xF0 (uppercase) and 0xF1 (lowercase).[32][3] This addition of 128 block elements in CP866 supports DOS console rendering but renders it incompatible with ISO 8859-5's text-focused design, which lacks such graphics and was intended for international standards compliance across systems like early web and printing.[15][32] For instance, the byte 0xB0 in CP866 draws a light shade block, but in ISO 8859-5, it represents uppercase 'А'.[3][32]| Byte | CP866 | KOI8-R | Windows-1251 | ISO 8859-5 |
|---|---|---|---|---|
| 0xA0 | а (U+0430) | ═ (U+2550) | (U+00A0) | (U+00A0) |
| 0xC0 | ┌ (U+2510) | ю (U+044E) | А (U+0410) | Р (U+0420) |
| 0xE0 | р (U+0440) | Ю (U+042E) | а (U+0430) | р (U+0440) |
Modern Context and Standards
Historical Usage in Legacy Systems
Code page 866, also known as OEM Russian or DOS Cyrillic Russian, was introduced in the Russian version of MS-DOS 4.01 in 1990 and became generally available in MS-DOS 6.22 in 1994.[5] It served as the primary 8-bit encoding for Cyrillic characters in Russian DOS environments throughout the 1990s, enabling text display in console-based applications, command-line interfaces, and text-mode software.[1] This encoding was essential for handling Russian script in resource-constrained systems, where it supported the Cyrillic alphabet while preserving compatibility with ASCII in the lower 128 code points.[33] In practical applications, code page 866 dominated Russian DOS setups for consoles, where it was the default OEM code page, facilitating everyday computing tasks like file management and scripting.[1] It was commonly used in DOS games and early internet activities, including Bulletin Board Systems (BBS) and file transfers via protocols like Zmodem. In the Russian editions of Windows 95 and 98, code page 866 remained the default for the console (via thechcp 866 command), providing backward compatibility with DOS applications in mixed environments.[1]
Support for code page 866 extended to OS/2, where it could be configured as a secondary code page in CONFIG.SYS or switched via CHCP 866, allowing Cyrillic text rendering in command prompts and GUI applications through tools like CPPal until the operating system's end-of-life in the mid-2000s.[34] Beyond desktops, it found use in embedded systems and printers, such as those from CognitiveTPG and Fujitsu, which incorporated it for outputting Cyrillic receipts and labels in point-of-sale setups.[35]
By the early 2000s, code page 866 began to decline as Unicode adoption accelerated in modern operating systems like Windows NT and later versions, which prioritized universal character support over locale-specific code pages, rendering legacy encodings obsolete for new development.[33]
Inclusion in WHATWG and Recommendations for UTF-8
Code page 866 is included in the WHATWG Encoding Standard, first published in 2012 and maintained as of 2025, as a legacy single-byte encoding supported by user agents for decoding in HTML5 and similar web contexts.[36] It is recognized by labels such as "cp866", "ibm866", "866", and "csibm866", and serves as the sole pure OEM code page dedicated to Cyrillic scripts in this standard.[36] The standard includes it for compatibility with deployed legacy content, utilizing the index-ibm866.txt mapping for byte-to-scalar-value algorithms, without plans for removal despite its niche role.[36] IBM maintains support for Code page 866 via CCSID 866 in its z/OS operating system, where it is designated for Cyrillic PC-data handling and integrated into character data conversion processes.[14] Similarly, in IBM i (formerly iSeries), CCSID 866 corresponds to ibm866 and is available for file encoding conversions involving 8-bit ASCII variants suitable for Cyrillic text.[37][38] As of 2025, Code page 866 persists in DOS emulators such as DOSBox, which supports it via keyboard layout commands likekeyb ru441 866 for Russian Cyrillic rendering in legacy applications, and DOSBox-X, which explicitly includes code page 866 among its supported OEM pages for accurate emulation of DOS-era software.[39][40] It also appears in legacy software environments requiring reverse-engineering of old files, but no new adoptions have emerged, as Unicode standards have supplanted it for contemporary development.
The WHATWG Encoding Standard recommends using UTF-8 for all new content creation and web deployment, positioning Code page 866 strictly for decoding and processing existing legacy files, such as those from DOS systems, to avoid compatibility issues.[36] In Linux console environments, GNU libiconv facilitates this migration, supporting CP866 input via commands like iconv -f CP866 -t [UTF-8](/page/UTF-8) to convert Cyrillic text from legacy sources to modern Unicode formats.[41] This approach ensures preservation of historical data while aligning with Unicode best practices.[36]