Recent from talks
Instruction cycle
Knowledge base stats:
Talk channels stats:
Members stats:
Instruction cycle
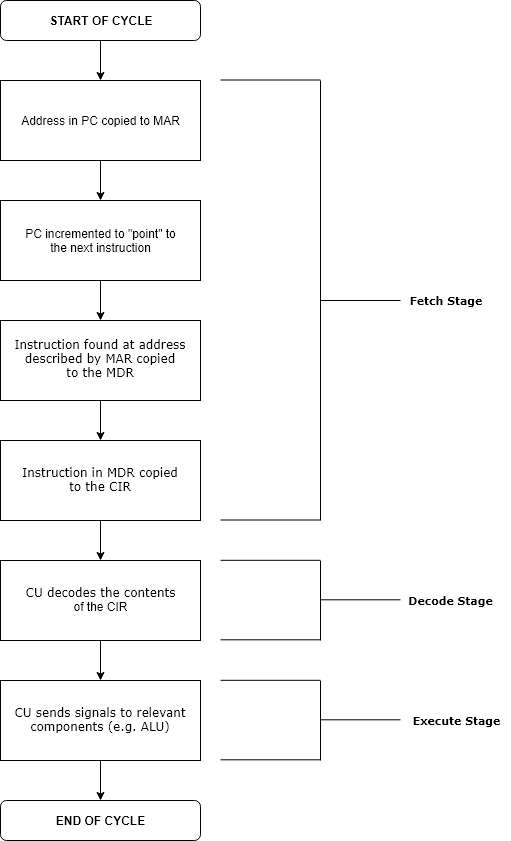
The instruction cycle (also known as the fetch–decode–execute cycle, or simply the fetch–execute cycle) is the cycle that the central processing unit (CPU) follows from boot-up until the computer has shut down in order to process instructions. It is composed of three main stages: the fetch stage, the decode stage, and the execute stage.
In simpler CPUs, the instruction cycle is executed sequentially, each instruction being processed before the next one is started. In most modern CPUs, the instruction cycles are instead executed concurrently, and often in parallel, through an instruction pipeline: the next instruction starts being processed before the previous instruction has finished, which is possible because the cycle is broken up into separate steps.
The program counter (PC) is a register that holds the memory address of the next instruction to be executed. After each instruction copy to the memory address register (MAR), the PC can either increment the pointer to the next sequential instruction, jump to a specified pointer, or branch conditionally to a specified pointer. Also, during a CPU halt, the PC holds the instruction being executed, until an external interrupt or a reset signal is received.
The MAR is responsible for storing the address describing the location of the instruction. After a read signal is initiated, the instruction in the address from the MAR is read and placed into the memory data register (MDR), also known as Memory Buffer Register (MBR). This component overall functions as an address buffer for pointing to locations in memory.
The MDR is responsible for temporarily holding instructions read from the address in MAR. It acts as a two-way register in the instruction cycle because it can take output from memory to the CPU, or output from the CPU to memory.
The current instruction register (CIR, though sometimes referred to as the instruction register, IR) is where the instruction is temporarily held, for the CPU to decode it and produce correct control signals for the execution stage.
The control unit (CU) decodes the instruction in the current instruction register (CIR). Then, the CU sends signals to other components within the CPU, such as the arithmetic logic unit (ALU), or back to memory to fetch operands, or to the floating-point unit (FPU). The ALU performs arithmetic operations based on specific opcodes in the instruction. For example, in RISC-V architecture, funct3 and funct7 opcodes exist to distinguish whether an instruction is a logical or arithmetic operation.
Each computer's CPU can have different cycles based on different instruction sets, but will be similar to the following cycle:
Hub AI
Instruction cycle AI simulator
(@Instruction cycle_simulator)
Instruction cycle
The instruction cycle (also known as the fetch–decode–execute cycle, or simply the fetch–execute cycle) is the cycle that the central processing unit (CPU) follows from boot-up until the computer has shut down in order to process instructions. It is composed of three main stages: the fetch stage, the decode stage, and the execute stage.
In simpler CPUs, the instruction cycle is executed sequentially, each instruction being processed before the next one is started. In most modern CPUs, the instruction cycles are instead executed concurrently, and often in parallel, through an instruction pipeline: the next instruction starts being processed before the previous instruction has finished, which is possible because the cycle is broken up into separate steps.
The program counter (PC) is a register that holds the memory address of the next instruction to be executed. After each instruction copy to the memory address register (MAR), the PC can either increment the pointer to the next sequential instruction, jump to a specified pointer, or branch conditionally to a specified pointer. Also, during a CPU halt, the PC holds the instruction being executed, until an external interrupt or a reset signal is received.
The MAR is responsible for storing the address describing the location of the instruction. After a read signal is initiated, the instruction in the address from the MAR is read and placed into the memory data register (MDR), also known as Memory Buffer Register (MBR). This component overall functions as an address buffer for pointing to locations in memory.
The MDR is responsible for temporarily holding instructions read from the address in MAR. It acts as a two-way register in the instruction cycle because it can take output from memory to the CPU, or output from the CPU to memory.
The current instruction register (CIR, though sometimes referred to as the instruction register, IR) is where the instruction is temporarily held, for the CPU to decode it and produce correct control signals for the execution stage.
The control unit (CU) decodes the instruction in the current instruction register (CIR). Then, the CU sends signals to other components within the CPU, such as the arithmetic logic unit (ALU), or back to memory to fetch operands, or to the floating-point unit (FPU). The ALU performs arithmetic operations based on specific opcodes in the instruction. For example, in RISC-V architecture, funct3 and funct7 opcodes exist to distinguish whether an instruction is a logical or arithmetic operation.
Each computer's CPU can have different cycles based on different instruction sets, but will be similar to the following cycle:
Recent media