

Community hub
Recent from talks
Contribute something
Nothing was collected or created yet.
Urdu alphabet
View on Wikipedia
| Urdu alphabet اُردُو حُرُوفِ تَہَجِّی Urdū ḥurūf-i tahajjī | |
|---|---|
 The word Urdū written in the Urdu alphabet | |
| Script type | |
| Official script | |
| Languages | |
| Related scripts | |
Parent systems | |
Child systems |
|
| Unicode | |
| U+0600 to U+06FF U+0750 to U+077F | |
| Urdu alphabet |
|---|
| ا (آ) ب پ ت ٹ ث ج چ ح خ د ڈ ذ ر ڑ ز ژ س ش ص ض ط ظ ع غ ف ق ک گ ل م ن (ں) و ہ (ھ) ء ی ے |
|
Extended Perso-Arabic script |
| Writing systems |
|---|
 |
| Abjad |
| Abugida |
| Alphabetical |
| Logographic |
| Syllabic |
| Hybrids |
|
Japanese (Logographic and syllabic) Hangul (Alphabetic and syllabic) |
The Urdu alphabet (Urdu: اُردُو حُرُوفِ تَہَجِّی, romanized: urdū ḥurūf-i tahajjī) is the right-to-left alphabet used for writing Urdu. It is a modification of the Persian alphabet, which itself is derived from the Arabic script. It has co-official status in the republics of Pakistan, India and South Africa. The Urdu alphabet has up to 39[4] or 40[5] distinct letters with no distinct letter cases and is typically written in the calligraphic Nastaʿlīq script, whereas Arabic is more commonly written in the Naskh style.
Usually, bare transliterations of Urdu into the Latin alphabet (called Roman Urdu) omit many phonemic elements that have no equivalent in English or other languages commonly written in the Latin script.
History
[edit]The standard Urdu script is a modified version of the Perso-Arabic script and has its origins in the 13th century Iran. It is also related to Shahmukhi, used for the Punjabi language varieties in Punjab, Pakistan. It is closely related to the development of the Nastaʻliq style of Perso-Arabic script. During the Mughal era, Nasta'liq became the common script for writing the Hindustani language, especially Urdu.[6][7]
Despite the invention of the Urdu typewriter in 1911, Urdu newspapers continued to publish prints of handwritten scripts by calligraphers known as katibs or khush-navees until the late 1980s. The Pakistani national newspaper Daily Jang was the first Urdu newspaper to use Nastaʿlīq computer-based composition. There are efforts under way to develop more sophisticated and user-friendly Urdu support on computers and the internet. Nowadays, nearly all Urdu newspapers, magazines, journals, and periodicals are composed on computers with Urdu software programs.
Other than the Indian subcontinent, the Urdu script is also used by Pakistan's large diaspora, including in the United Kingdom, the United Arab Emirates, the United States, Canada, Saudi Arabia and other places.[5]
Nastaliq
[edit]
Urdu is written in the Nastaliq style (Persian: نستعلیق Nastaʿlīq). The Nastaliq calligraphic writing style began as a Persian mixture of the Naskh and Ta'liq scripts. After the Muslim conquest of the Indian subcontinent, Nastaʻliq became the preferred writing style for Urdu. It is the dominant style in Pakistan and many Urdu writers elsewhere in the world use it. Nastaʿlīq is more cursive and flowing than its Naskh counterpart.
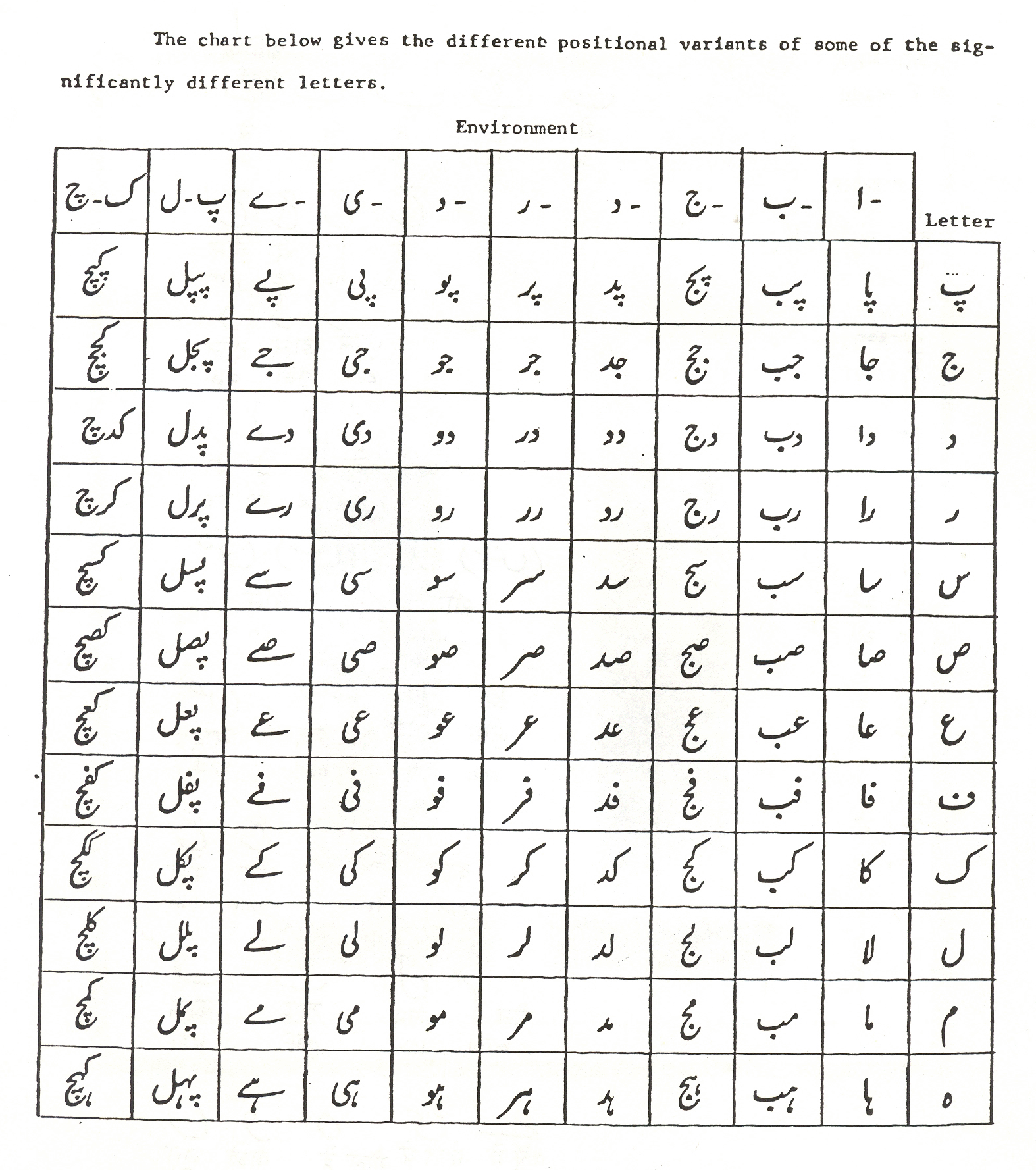
In the Arabic alphabet, and many others derived from it, letters are regarded as having two or three general forms each, based on their position in the word (though Arabic calligraphy can add a great deal of complexity). But the Nastaliq style in which Urdu is written uses more than three general forms for many letters, even in simple non-decorative documents.[8]
Alphabet
[edit]The Urdu script is an abjad script derived from the modern Persian script, which is itself a derivative of the Arabic script. As an abjad, the Urdu script only shows consonants and long vowels; short vowels can only be inferred by the consonants' relation to each other. While this type of script is convenient in Semitic languages like Arabic and Hebrew, whose consonant roots are the key of the sentence, Urdu is an Indo-European language, which requires more precision in vowel sound pronunciation, hence necessitating more memorisation. The number of letters in the Urdu alphabet is somewhat ambiguous and debated.[9]
Letter names and phonemes
[edit]| Name[10] | Forms | IPA | Romanization | Unicode | Order | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Urdu Roman Urdu |
Isolated | Final | Medial | Initial | ALA-LC[11] | Hunterian[12] | [A] | [14] | [B] | ||
| الف alif |
ا | ـا | /ɑː/, /ʔ/, silent[C] | ā, – | U+0627 | 1 | |||||
| بے bē |
ب | ـب | ـبـ | بـ | /b/ | b | U+0628 | 2 | |||
| پے pē |
پ | ـپ | ـپـ | پـ | /p/ | p | U+067E | 3 | |||
| تے tē |
ت | ـت | ـتـ | تـ | /t/ | t | U+062A | 4 | |||
| ٹے ṭē |
ٹ | ـٹ | ـٹـ | ٹـ | /ʈ/ | ṭ | t | U+0679 | 5 | ||
| ثے s̱ē |
ث | ـث | ـثـ | ثـ | /s/ | s̱ | s | U+062B | 6 | ||
| جيم jīm |
ج | ـج | ـجـ | جـ | /d͡ʒ/ | j | U+062C | 7 | |||
| چے cē |
چ | ـچ | ـچـ | چـ | /t͡ʃ/ | c | ch | U+0686 | 8 | ||
| بڑی حے baṛī ḥē |
ح | ـح | ـحـ | حـ | /ɦ/ | ḥ | h | U+062D | 9 | ||
| حائے حطی ḥā'e huttī | |||||||||||
| حائے مہملہ ḥā'e muhmala | |||||||||||
| خے k͟hē |
خ | ـخ | ـخـ | خـ | /x/ | k͟h | kh | U+062E | 10 | ||
| دال dāl |
د | ـد | /d/ | d | U+062F | 11 | |||||
| ڈال ḍāl |
ڈ | ـڈ | /ɖ/ | ḍ | d | U+0688 | 12 | ||||
| ذال ẕāl |
ذ | ـذ | /z/ | ẕ | z | U+0630 | 13 | ||||
| رے rē |
ر | ـر | /r/ | r | U+0631 | 14 | |||||
| ڑے ṛē |
ڑ | ـڑ | /ɽ/ [D] |
ṛ | r | U+0691 | 15 | ||||
| زے zē |
ز | ـز | /z/ | z | U+0632 | 16 | |||||
| ژے zhē |
ژ | ـژ | /ʒ/ [E] |
zh | U+0698 | 17 | |||||
| سین sīn |
س | ـسـ | سـ | /s/ | s | U+0633 | 18 | ||||
| شین shīn |
ش | ـشـ | شـ | /ʃ/ | sh | U+0634 | 19 | ||||
| صاد ṣwād |
ص | ـصـ | /s/ | ṣ | s | U+0635 | 20 | ||||
| ضاد ẓwād |
ض | ـضـ | /z/ | ẓ | z | U+0636 | 21 | ||||
| طوے t̤oʼē |
ط | ـطـ | /t/ | t̤ | t | U+0637 | 22 | ||||
| ظوے z̤oʼē |
ظ | ـظـ | /z/ | z̤ | z | U+0638 | 23 | ||||
| عین ʻain |
ع | ـع | ـعـ | عـ | /ɑː/, /oː/, /eː/, /ʔ/, /ʕ/, silent |
ʻ | ʻ [citation needed] |
U+0639 | 24 | ||
| غین g͟hain |
غ | ـغ | ـغـ | غـ | /ɣ/ | g͟h | gh | U+063A | 25 | ||
| فے fē |
ف | ـف | ـفـ | فـ | /f/ | f | U+0641 | 26 | |||
| قاف qāf |
ق | ـقـ | قـ | /q/ | q | U+0642 | 27 | ||||
| کاف kāf |
ک | ـک | ـکـ | کـ | /k/ | k | U+06A9 | 28 | |||
| گاف gāf |
گ | ـگ | ـگـ | گـ | /ɡ/ | g | U+06AF | 29 | |||
| لام lām |
ل | ـل | ـلـ | لـ | /l/ | l | U+0644 | 30 | |||
| میم mīm |
م | ـمـ | مـ | /m/ | m | U+0645 | 31 | ||||
| نون nūn |
ن | ـن | ـنـ | نـ | /n/, /ɲ/, /ɳ/, /ŋ/ |
n | U+0646 | 32 | |||
| نون غنّہ nūn g͟hunnā |
ں ٘ |
ـں | ـںـ | ںـ | / ◌̃ / [D] |
ṉ | n | U+06BA U+0658 [F] |
[G] | 32a | 33 |
| واؤ wāʼo |
و | /ʋ /, /uː/, /ʊ /, /o ː /, /ɔː / |
v, ū, u, o, au |
w, ū, u, o, au |
U+0648 | 33 | 34 | ||||
| ہے hē |
ہ | ـہ | ـہـ | ہـ | /ɦ/, /ɑː/, /eː/ | h, ā, e | U+06C1 [H] |
34 | 34 | 35 | |
| چھوٹی ہے choṭī hē |
34a | ||||||||||
| دو چشمی ہے do-cashmī hē |
ھ | ـھـ | /ʰ/ or /ʱ/ [D] |
h | U+06BE | 35 | 34b | 36 | |||
| یے yē |
ی | ـی | ـیـ | یـ | /j/, /iː/, /ɑː/ | y, ī, á | U+06CC | 36 | 35 | 38 | |
| بڑی یے baṛī yē |
ے | /ɛː/, /eː/ [D] |
ai, e | U+06D2 | 37 | 35b | 39 | ||||
| ہمزہ hamzah |
ئ | ـئ | ـئـ | ئـ | /ʔ/ or silent [I] |
ʼ, –, yi | U+0626 | 35a | 37 [J] | ||
| ء | U+0621 | 0 | |||||||||
Footnotes:
- ^ dictionary order[13]
- ^ [citation needed]
- ^ At the beginning of a word it can represent another vowel, holding a vowel diacritic that would normally be held by the consonant preceding the vowel, for examble اُردو "Urdu". But the diacritic indicating which vowel is often omitted اردو like other short vowel diacritics.
- ^ a b c d No Urdu word begins with ں, ھ, ڑ, or ے.[citation needed]
- ^ Used mainly for Persian loanwords.
- ^ The version shown on the left is U+06BA, which is used only at the end of words. When it is used in the middle of a word it is a diacritic U+0658, which is usually omitted (see below for further information on diacritic omission in Urdu).
- ^ Not present in dictionary order because it is not used at the beginning of words.
- ^ Sometimes choṭī hē is used to refer to hey but choṭī hē can also refer to the Arabic / Persian variant, a stylistic variation representing an equivalent letter, but Persian and Arabic usually use U+0647 whereas Urdu uses U+06C1 for gōl hey.[14] See also: Urdu in Unicode.
- ^ Hamzah: In Urdu, hamzah is silent in all its forms except for when it is used as hamzah-e-izafat. The main use of hamzah in Urdu is to indicate a vowel cluster.
- ^ [citation needed]
Additional characters and variations
[edit]Arabic Tāʼ marbūṭah
[edit]Tāʼ marbūṭah is also sometimes considered the 40th letter of the Urdu alphabet, though it is rarely used except for in certain loan words from Arabic. Tāʼ marbūṭah is regarded as a form of tā, the Arabic version of Urdu tē, but it is not pronounced as such, and when replaced with an Urdu letter in naturalised loan words it is usually replaced with Gol hē.
Table
[edit]| Group | Letter[A] | Name (see: Glossary of key words) | Unicode [15][16] | |||
|---|---|---|---|---|---|---|
| Nastaliq [B] |
Naskh with diacritics |
Roman Urdu or English[4][14] | ||||
| Alif | آ | آ | الف مدہ | الِف مَدّه [14] |
alif maddah [14][C] |
U+0622 alef with madda above [16] |
| Hamza[D] | ء | ء | ہمزہ | ہَمْزه [14] |
hamzah | U+0621 hamza [16] |
| ___ | ___ | hamza on the line | ||||
| ٔ | ــٔـ | ___ | ___ | hamza diacritic [C][E] |
U+0654 Hamza Above | |
| ئ | ئ | ہمزہ | ہَمْزه [14] |
hamzah | U+0626 yeh with hamza above [16] | |
| ___ | ___ | yē hamza / alif hamza | ||||
| ۓ | ۓ | ___ | ___ | baṛī yē hamza | U+06D3 yeh barree with hamza above [15] | |
| ؤ | ؤ | واوِ مَہْمُوز | واوِ مَہْمُوز [14] |
vāv-e mahmūz [14] |
U+0624 waw with hamza above [16] | |
| ۂ ۂ | ۂ ـۂ | ___ | ___ | U+06C2 heh goal with hamza above [15] or U+06C1 + U+0654 | ||
| Arabic[F] | ۃ ۃ | ۃ ـۃ | Arabic: تاء مربوطة [ar] |
Arabic: تَاء مَرْبُوطَة |
tāʼ marbūṭah "bound ta" |
U+06C3 teh marbuta goal [15] |
| ة ـة | U+0629 teh marbuta [16] | |||||
| ت | ت | Arabic: تاء مفتوحة [ar] |
Arabic: تَاء مَفْتُوحَة |
tāʼ maftūḥah "open ta" |
U+062A Teh | |
Footnotes:
- ^ Left: Urdu Nastaliq. Right: Arabic Naskh or modern style.
- ^ The Nastaliq text will display in a different style if there is not an appropriate font installed on the machine.
- ^ a b Most vowel diacritics are omitted in most Urdu writing, but Urdu writing usually does distinguish alif mad, and include hamza over bari ye, gol he, and wow. For example, alif mad and bare alif in آزادی - "āzādī", ɑ:zɑ:d̪i, freedom
[17] - are distinguished in most contexts. - ^ See: Hamzah in Nastaliq.
- ^ See: Hamzah in Nastaliq.
- ^ see: Arabic Tāʼ marbūṭah above.
Hamza in Nastaliq
[edit]Hamza can be difficult to recognise in Urdu handwriting and fonts designed to replicate it, closely resembling two dots above as featured in ت Té and ق Qaf, whereas in Arabic and Geometric fonts it is more distinct and closely resembles the western form of the numeral 2 (two).
Digraphs
[edit]| Digraph[11] | Transcription[11] | IPA | Examples |
| بھ | bh | [bʱ] | بھاری |
| پھ | ph | [pʰ] | پھول |
| تھ | th | [tʰ] | تھیلا |
| ٹھ | ṭh | [ʈʰ] | ٹھنڈا |
| جھ | jh | [d͡ʒʱ] | جھاڑی |
| چھ | chh | [t͡ʃʰ] | چھتری |
| دھ | dh | [dʱ] | دھوبی |
| ڈھ | ḍh | [ɖʱ] | ڈھول |
| رھ | rh | [rʱ] | تیرھواں |
| ڑھ | ṛh | [ɽʱ] | اڑھائی |
| کھ | kh | [kʰ] | کھانسی |
| گھ | gh | [ɡʱ] | گھوڑا |
| لھ | lh | [lʱ] | دولھا (alternative of دُلہا) |
| مھ | mh | [mʱ] | تمھیں |
| نھ | nh | [nʱ] | ننھا |
A separate do-chashmi-he letter, ھ, exists to denote a /ʰ/ or a /ʱ/. This letter is mainly used as part of the multitude of digraphs, detailed in above.
Differences from the Persian alphabet
[edit]Urdu has more letters added to the Perso-Arabic base to represent sounds not present in Persian, which already has additional letters added to the Arabic base itself to represent sounds not present in Arabic. The letters added are shown in the table below:
| Letter | IPA |
|---|---|
| ٹ | /ʈ/ |
| ڈ | /ɖ/ |
| ڑ | /ɽ/ |
| ں | /◌̃/ |
| ے | /ɛ:/ or /e:/. |
Retroflex letters
[edit]
Old Hindustani used four dots ٿ ڐ ڙ over three Arabic letters ت د ر to represent retroflex consonants.[18] In handwriting those dots were often written as a small vertical line attached to a small triangle. Subsequently, this shape became identical to a small letter ط t̤oʼē.[19] It is commonly and erroneously assumed that ṭāʾ itself was used to indicate retroflex consonants because of it being an emphatic alveolar consonant that Arabic scribes thought approximated the Hindustani retroflexes.[citation needed] In modern Urdu, called to'e is always pronounced as a dental, not a retroflex. [citation needed]
Vowels
[edit]The Urdu language has ten vowels and ten nasalized vowels. Each vowel has four forms depending on its position: initial, middle, final and isolated. Like in its parent Arabic alphabet, Urdu vowels are represented using a combination of digraphs and diacritics. Alif, Waw, Ye, He and their variants are used to represent vowels.
Vowel chart
[edit]Urdu does not have standalone vowel letters. Short vowels (a, i, u, o) are represented by optional diacritics (zabar, zer, pesh, ulta pesh) upon the preceding consonant or a placeholder consonant (alif, ain, or hamzah) if the syllable begins with the vowel, and long vowels by consonants alif, ain, ye, and wa'o as matres lectionis, with disambiguating diacritics, some of which are optional (zabar, zer, pesh, ulta pesh), whereas some are not (madd, hamzah). Urdu does not have short vowels at the end of words. This is a table of Urdu vowels:
| Romanization | Pronunciation | Final | Middle | Initial |
|---|---|---|---|---|
| a | /ə/ | N/A | ـَ | اَ |
| ā | /aː/ | ـَا، ـَی، ـَہ | ـَا | آ |
| i | /ɪ/ | N/A | ـِ | اِ |
| ī | /iː/ | ـِى | ـِیـ | اِیـ |
| e | /eː/ | ـے | ـیـ | ایـ |
| ai | /ɛː/ | ـَے | ـَیـ | اَیـ |
| u | /ʊ/ | N/A | ـُ | اُ |
| ū | /uː/ | ـُو | اُو | |
| o | /ɔː/ | N/A | ـ ٗ | ا ٗ |
| ō | /oː/ | ـو ٗ | ٗاو | |
Alif
[edit]Alif is the first letter of the Urdu alphabet, and it is used exclusively as a vowel. At the beginning of a word, alif can be used to represent any of the short vowels: اب ab, اسم ism, اردو Urdū. For long ā at the beginning of words alif-mad is used: آپ āp, but a plain alif in the middle and at the end: بھاگنا bhāgnā.
Wāʾo
[edit]Wāʾo is used to render the vowels "ū", "o", "u" and "ō" ([uː], [oː], [ʊ] and [ɔː] respectively), and it is also used to render the labiodental approximant, [ʋ]. Only when preceded by the consonant k͟hē (خ), can wāʾo render the "u" ([ʊ]) sound (such as in خود, "k͟hud" - myself), or not pronounced at all (such as in خواب, "k͟haab" - dream). This is known as the silent wāʾo, and is only present in words loaned from Persian.[20] When written with pesh (اُ / وُ), it is usually pronounced with "u" and "ū", for example "umeed" (اُمید) and "khushbū" (خوشبو). In the case of wāʾo being written with an ulta pesh (ـ ٗ / ـوٗ), it would be pronounced with an "o" and "ō", such as the likes of "mohtāj" (محتاج ٗ) and "jāgō" (جاگـوٗ)
Ye
[edit]Ye is divided into two variants: choṭī ye ("little ye") and baṛī ye ("big ye").
Choṭī ye (ی) is written in all forms exactly as in Persian. It is used for the long vowel "ī" and the consonant "y".
Baṛī ye (ے) is used to render the vowels "e" and "ai" (/eː/ and /ɛː/ respectively). Baṛī ye is distinguishable in writing from choṭī ye only when it comes at the end of a word/ligature. Additionally, Baṛī ye is never used to begin a word/ligature, unlike choṭī ye.
| Letter's name | Final Form | Middle Form | Initial Form | Isolated Form |
|---|---|---|---|---|
| چھوٹی يے Choṭī ye |
ـی | ـیـ | یـ | ی |
| بڑی يے Baṛī ye |
ـے | ے |
The 2 he's
[edit]He is divided into two variants: gol he ("round he") and do-cašmi he ("two-eyed he").
Gol he (ہ) is written round and zigzagged, and can impart the "h" (/ɦ/) sound anywhere in a word. Additionally, at the end of a word, it can be used to render the long "a" or the "e" vowels (/ɑː/ or /eː/), which also alters its form slightly (on modern digital writing systems, this final form is achieved by writing two he's consecutively).
Do-cašmi he (ھ) is written as in Arabic Naskh style script (as a loop), in order to create the aspirate consonants and write Arabic words.
| Letter's name | Final Form | Middle Form | Initial Form | Isolated Form |
|---|---|---|---|---|
| گول ہے Gol he |
ـہ | ـہـ | ہـ | ہ |
| دو چشمی ہے Do-cašmi he |
ـھ | ـھـ | ھ | |
Ayn
[edit]Ayn in its initial and final position is silent in pronunciation and is replaced by the sound of its preceding or succeeding vowel.
Nun Ghunnah
[edit]Vowel nasalization is represented by nun ghunna written after their non-nasalized versions, for example: ہَے when nasalized would become ہَیں. In middle form nun ghunna is written just like nun and is differentiated by a diacritic called maghnoona or ulta jazm which is a superscript V symbol above the ن٘.
Examples:
| Form | Urdu | Transcription |
| Orthography | ں | ṉ |
| End form | میں | maiṉ |
| Middle form | کن٘ول | kaṉwal |
Diacritics
[edit]Urdu uses the same subset of diacritics used in Arabic based on Persian conventions. Urdu also uses Persian names of the diacritics instead of Arabic names. Commonly used diacritics are zabar (Arabic fatḥah), zer (Arabic kasrah), pesh (Arabic dammah) and ulta pesh which are used to clarify the pronunciation of vowels, as shown above. Jazam (ـْـ, Arabic sukun) is used to indicate a consonant cluster and tashdid (ـّـ, Arabic shaddah) is used to indicate a gemination, although it is never used for verbs, which require double consonants to be spelled out separately. Other diacritics include khari zabar (Arabic dagger alif), do zabar (Arabic fathatan) which are found in some common Arabic loan words. Other Arabic diacritics are also sometimes used though very rarely in loan words from Arabic. Zer-e-izafat and hamzah-e-izafat are described in the next section.
Other than common diacritics, Urdu also has special diacritics, which are often found only in dictionaries for the clarification of irregular pronunciation. These diacritics include kasrah-e-majhool, fathah-e-majhool, dammah-e-majhool, maghnoona, ulta jazam, alif-e-wavi and some other very rare diacritics. Among these, only maghnoona is used commonly in dictionaries and has a Unicode representation at U+0658. Other diacritics are only rarely written in printed form, mainly in some advanced dictionaries.[21]
Iẓāfat
[edit]Iẓāfat is a syntactical construction of two nouns, where the first component is a determined noun, and the second is a determiner. This construction was borrowed from Persian. A short vowel "i" is used to connect these two words, and when pronouncing the newly formed word the short vowel is connected to the first word. If the first word ends in a consonant or an ʿain (ع), it may be written as zer ( ِ ) at the end of the first word, but usually is not written at all. If the first word ends in choṭī he (ہ) or ye (ی or ے) then hamzā (ء) is used above the last letter (ۂ or ئ or ۓ). If the first word ends in a long vowel (ا or و), then a different variation of baṛī ye (ے) with hamzā on top (ئے, obtained by adding ے to ئ) is added at the end of the first word.[22]
| Forms | Example | Transliteration | Meaning |
|---|---|---|---|
| ـ◌ِ | شیرِ پنجاب | sher-e-Panjāb | the lion of Punjab |
| ۂ | ملکۂ دنیا | malikā-e-dunyā | the queen of the world |
| ئ | ولئ کامل | walī-e-kāmil | perfect saint |
| ـئے | مئے عشق | mai-e-ishq | the wine of love |
| ئے | روئے زمین | rū-'e-zamīn | the surface of the Earth |
| صدائے بلند | sadā-'e-buland | a high voice |
Computers and the Urdu alphabet
[edit]In the early days of computers, Urdu was not properly represented on any code page. One of the earliest code pages to represent Urdu was IBM Code Page 868 which dates back to 1990.[23] Other early code pages which represented Urdu alphabets were Windows-1256 and MacArabic encoding both of which date back to the mid-1990s. In Unicode, Urdu is represented inside the Arabic block. Another code page for Urdu, which is used in India, is Perso-Arabic Script Code for Information Interchange. In Pakistan, the 8-bit code page which is developed by National Language Authority is called Urdu Zabta Takhti (اردو ضابطہ تختی) (UZT)[24] which represents Urdu in its most complete form including some of its specialized diacritics, though UZT is not designed to coexist with the Latin alphabet.
Encoding Urdu in Unicode
[edit]
| Characters in Urdu |
Characters in Arabic |
|---|---|
| ہ (U+06C1) ھ (U+06BE) |
ه (U+0647) |
| ی (U+06CC) | ى (U+0649) ي (U+064A) |
| ک (U+06A9) | ك (U+0643) |
Like other writing systems derived from the Arabic script, Urdu uses the 0600–06FF Unicode range.[25] Certain glyphs in this range appear visually similar (or identical when presented using particular fonts) even though the underlying encoding is different. This presents problems for information storage and retrieval. For example, the University of Chicago's electronic copy of John Shakespear's "A Dictionary, Hindustani, and English"[26] includes the word 'بهارت' (bhārat "India"). Searching for the string "بھارت" (with ھ) returns no results, whereas querying with the (identical-looking in many fonts) string "بهارت" (with ه) returns the correct entry.[27] This is because the medial form of the Urdu letter do chashmi he (U+06BE)—used to form aspirate digraphs in Urdu—is visually identical in its medial form to the Arabic letter hāʾ (U+0647; phonetic value /h/). In Urdu, the /h/ phoneme is represented by the character U+06C1, called gol he (round he), or chhoti he (small he).
In 2003, the Center for Research in Urdu Language Processing (CRULP)[28]—a research organisation affiliated with Pakistan's National University of Computer and Emerging Sciences—produced a proposal for mapping from the 1-byte UZT encoding of Urdu characters to the Unicode standard.[29] This proposal suggests a preferred Unicode glyph for each character in the Urdu alphabet.
Software
[edit]The Daily Jang was the first Urdu newspaper to be typeset digitally in Nastaʻliq by computer. There are efforts underway to develop more sophisticated and user-friendly Urdu support on computers and on the Internet. Nowadays, nearly all Urdu newspapers, magazines, journals and periodicals are composed on computers via various Urdu software programmes, the most widespread of which is InPage Desktop Publishing package. Microsoft has included Urdu language support in all new versions of Windows and both Windows Vista and Microsoft Office 2007 are available in Urdu through Language Interface Pack[30] support. Most Linux Desktop distributions allow the easy installation of Urdu support and translations as well.[31] Apple implemented the Urdu language keyboard across Mobile devices in its iOS 8 update in September 2014.[32]
Romanization standards and systems
[edit]There are several romanization standards for writing Urdu with the Latin alphabet, though they are not very popular because most fall short of representing the Urdu language properly. Instead of standard romanization schemes, people on Internet, mobile phones and media often use a non-standard form of romanization which tries to mimic English orthography. The problem with this kind of romanization is that it can only be read by native speakers, and even for them with great difficulty. Among standardized romanization schemes, the most accurate is ALA-LC romanization, which is also supported by National Language Authority. Other romanization schemes are often rejected because either they are unable to represent sounds in Urdu properly, or they often do not take regard of Urdu orthography, and favor pronunciation over orthography.[33]
The National Language Authority of Pakistan has developed a number of systems with specific notations to signify non-English sounds, but these can only be properly read by someone already familiar with the loan letters.[citation needed]
Roman Urdu also holds significance among the Christians of Pakistan and North India. Urdu was the dominant native language among Christians of Karachi and Lahore in present-day Pakistan and Madhya Pradesh, Uttar Pradesh Rajasthan in India, during the early part of the 19th and 20th century, and is still used by Christians in these places. Pakistani and Indian Christians often used the Roman script for writing Urdu. Thus Roman Urdu was a common way of writing among Pakistani and Indian Christians in these areas up to the 1960s. The Bible Society of India publishes Roman Urdū Bibles that enjoyed sale late into the 1960s (though they are still published today). Church songbooks are also common in Roman Urdu. However, the usage of Roman Urdu is declining with the wider use of Hindi and English in these states.
Glossary of key words from letter names
[edit]
| Letter name(s) | Urdu word | Examples of other uses | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Isolated form |
Urdu name |
Roman Urdu | Urdu | IPA | Roman Urdu name |
English Translation | Urdu | Roman Urdu or IPA | Translation |
| ح | بَڑی حے | baṛī ħē | بَڑی | bəɽi[17] | baṛī / bari |
big / elder[17] | بڑی آنت [ur] | Baṛi ant | large intestine |
| ے | بَڑی يـے | baṛī yē | آنت [ur] | Ant | intestine | ||||
| ی | چھوٹی یے | čhōṭī yē | چھوٹی | tʃʰoːʈi[17] | choti | small / minor / junior[17] | |||
| ہ | چھوٹی ہے | čhōṭī hē | چھوٹی آنت [ur] | small intestine | |||||
| گول ہـے | gōl hē | گول | goːl[17] | gōl | round / spherical / vague / silly / obese[34] | گول گپے [ur] | gol gappay | panipuri | |
| ھ | دوچَشْمی ہے | dō-čašmī hē | دوچَشْمی | do-cashmī | two-eyed [citation needed] |
دو چشمی دوربین [ur] | do-cashmi
dorabīn |
binoculars | |
| دوربین [ur] | dorabīn | telescope | |||||||
| دو | do | 2 / two | دو ایوانیت [ur] | do ayvanīt | bicameralism | ||||
| چشم | /tʃəʃm/[17] | chashm | the eye / hope / expectation[34] | چشم [ur] | cashm | eye | |||
| ں | نُونِ غُنّہ | nūn-e ğunnah | غُنّہ | ɣʊnnɑ[17] | ğunnah / g͟hunnah | nasal sound or twang[17] | [example needed] | ||
| آ | الِف مَدّه | alif maddah | مَدّه | maddah | Arabic: | [example needed] | |||
| ؤ | واوِ مَہْمُوز | vāv-e mahmūz | مَہْمُوز | mæhmuːz[17] | mahmūz | defective / improper[17] | [example needed] | ||
| ء ا آ ب پ ت ٹ ث ب ج چ خ ح د ڈ ذ ر ڑ ز ژ س ش ص ض ط ظ ع غ ف ق ک گ ل م ن ں و ہ ھ ی ے | حروف تہجی [ur] [35] |
harūf tahajī (alphabet) | تہجی | tahajī | sequence [citation needed] |
[example needed] | |||
| حُرُوف | /hʊruːf/[17] | harūf | letters (plural)[17] (often referred to as "alphabets" in informal Pakistani English) |
[example needed] | |||||
| حَرْف | /hərf/[17] | harf | "letter of the alphabet" / handwriting / statement / blame / stigma[17] | [example needed] | |||||
See also
[edit]References
[edit]- ^ "Constitution of the Republic of South Africa, 1996 – Chapter 1: Founding Provisions". gov.za. Retrieved 6 December 2014.
- ^ "Balti alphabet and pronunciation". omniglot.com. Retrieved 31 January 2023.
- ^ Bashir, Elena; Hussain, Sarmad; Anderson, Deborah (5 May 2006). "N3117: Proposal to add characters needed for Khowar, Torwali, and Burushaski" (PDF). ISO/IEC JTC1/SC2/WG2.
- ^ a b Project Fluency (7 October 2016). Urdu: The Complete Urdu Learning Course for Beginners: Start Speaking Basic Urdu Immediately (Kindle ed.). Createspace Independent Publishing Platform. p. Kindle Locations 66–67. ISBN 978-1-5390-4780-3.
- ^ a b "Urdu". Omniglot.
- ^ Blair, p. 536-539, 552-554.
- ^ Yusofi, Gholam-Hosayn. "CALLIGRAPHY (continued)". Encyclopædia Iranica.
- ^ "*positional chart*". Urdu: some thoughts about the script and grammar, and other general notes for students. Retrieved 28 February 2020 – via www.columbia.edu.
- ^ "Controversy over number of letters in Urdu alphabet". DAWN.COM. 15 June 2009.
- ^ Delacy 2003, pp. XV–XVI.
- ^ a b c "Urdu romanization" (PDF). The Library of Congress.
- ^ Geographical Names Romanization in Pakistan. UNGEGN, 18th Session. Geneva, 12–23 August 1996. Working Papers No. 85 and No. 85 Add. 1.
- ^ Bhatia, Tej K.; Khoul, Ashok; Koul, Ashok (2015). Colloquial Urdu: The Complete Course for Beginners. Routledge. pp. 41–42. ISBN 978-1-317-30471-5. Retrieved 30 June 2020.
- ^ a b c d e f g h i "Urdu Alphabet". www.user.uni-hannover.de. Archived from the original on 11 September 2019. Retrieved 29 February 2020.
- ^ a b c d "Extended Arabic Letter". unicode.org. Retrieved 6 April 2020.
- ^ a b c d e f "Based on ISO 8859-6". unicode.org. Retrieved 6 April 2020.
- ^ a b c d e f g h i j k l m n o "Urdu: Oxford Living Dictionaries". Urdu: Oxford Living Dictionaries. Archived from the original on 18 October 2016. Retrieved 15 March 2020.
- ^ Ballantyne, James Robert (1842). A Grammar of the Hindustani Language, with Brief Notices of the Braj and Dakhani Dialects. Madden & Company. p. 11.
- ^ Berggren, Olaf (2002). Scripts. Bibliotheca Alexandrina. p. 108.
- ^ Grierson, George Abraham. "Urdu Language Management". Language Information Services (LIS)-India. Retrieved 23 July 2022.
- ^ "Proposal of Inclusion of Certain Characters in Unicode" (PDF).
- ^ Delacy 2003, pp. 99–100.
- ^ "IBM 868 code page"
- ^ "Urdu Zabta Takhti" (PDF).
- ^ "Arabic" (PDF). unicode.org. Retrieved 7 April 2019.
- ^ "A dictionary, Hindustani and English". Dsal.uchicago.edu. 29 September 2009. Retrieved 18 December 2011.
- ^ "A dictionary, Hindustani and English". Dsal.uchicago.edu. Archived from the original on 15 December 2012. Retrieved 18 December 2011.
- ^ "Center for Research in Urdu Language Processing". Crulp.org. Retrieved 18 December 2011.
- ^ Archive index at the Wayback Machine
- ^ "مائِیکروسافٹ ڈاؤُن لوڈ مَرکَزWindows". Microsoft.com. Retrieved 18 December 2011.
- ^ "Ubuntu in Urdu « Aasim's Web Corner". Aasims.wordpress.com. 5 October 2009. Retrieved 18 December 2011.
- ^ "E-Urdu: How one man's plea for Nastaleeq was heard by Apple". The Express Tribune. 16 October 2014. Retrieved 29 March 2015.
- ^ "اردو میں نقل حرفی ۔ ایک ابتدائی تعارف: نبلٰی پیرزادہ". nlpd.gov.pk.
- ^ a b "Urdu: Oxford Living Dictionaries (Urdu to English Translation)". Urdu: Oxford Living Dictionaries. Retrieved 15 March 2020.[dead link]
- ^ "خلا سے زمین پر انگریزی کےحروف تہجی". BBC News اردو (in Urdu). 5 January 2016. Retrieved 7 May 2020.
{kind=link}
Sources
[edit]- Delacy, Richard (2003). Beginner's Urdu Script. McGraw-Hill.
- Delacy, Richard (2010). Read and write Urdu script. McGraw-Hill. ISBN 978-0-07-174746-2.
- "Urdu romanization" (PDF). The Library of Congress.
- Ishida, Richard. "Urdu script notes".
External links
[edit]- Urdu alphabet
- Urdu alphabet with Devanagari equivalents. Archived 11 September 2019 at the Wayback Machine.
- Hugo's Urdu Alphabet Page. Archived 16 July 2020 at the Wayback Machine.
- calligraphyislamic.com, a resource for Urdu calligraphy and script
- Urdu Script Introduction from Columbia University
- National Council for Promotion of Urdu Language. Archived 6 March 2018 at the Wayback Machine.
† indicates the language is no longer written using Arabic | |
| Europe |
|
| Asia |
|
| Africa | |
Urdu alphabet
View on GrokipediaHistorical Development
Origins in Perso-Arabic Script
The Urdu alphabet originates from the Perso-Arabic script, a writing system that evolved from the Arabic abjad—a consonant-focused alphabet introduced to the Indian subcontinent through Islamic conquests and trade beginning in the 8th century. The Arabic script, with its 28 basic letters, provided the foundational structure, but it was insufficient for rendering Persian phonemes absent in Arabic, such as /p/, /ch/, /zh/, and /g/. Persians adapted the script around the 8th to 9th centuries by introducing four additional letters to accommodate these sounds, creating what became known as the Perso-Arabic script.[6][7] This adapted Perso-Arabic script was further modified in the 13th century to suit the phonology of Indo-Aryan languages spoken in northern India, particularly the emerging Hindustani dialect, which blended Prakrit-derived vernaculars with Persian and Arabic loanwords. During the Delhi Sultanate (1206–1526), the script served as the medium for administrative, literary, and religious texts in Persian, the court language, while local elites began employing it for vernacular compositions to bridge Persianate high culture with indigenous expressions. This hybrid adaptation reflected the cultural synthesis of the period, transforming the script into a tool for expressing an Indo-Persian linguistic identity.[8][9] The script's adoption for Hindustani solidified under the Mughal Empire (1526–1857), where it became the preferred vehicle for poetry, chronicles, and official correspondence, elevating the language's status among diverse populations in the empire's heartland around Delhi and Agra. Mughal patronage encouraged the use of this script for recording oral traditions and courtly dialogues, fostering a shared literary heritage that distinguished it from purely Persian or Arabic usages.[7][10] A pivotal figure in this early phase was the poet and scholar Amir Khusrau (1253–1325), who, during the Delhi Sultanate, composed some of the earliest known works in Hindavi—the precursor to Urdu—using the modified Perso-Arabic script. As a courtier under sultans like Alauddin Khalji, Khusrau integrated local dialects into Perso-Arabic forms, producing riddles, songs, and narratives that demonstrated the script's versatility for Indo-Aryan sounds and rhythms, thereby laying groundwork for Urdu's poetic tradition.[11][12]Evolution and Standardization
During the 18th century, amid the decline of the Mughal Empire, the Urdu script underwent significant refinements, with orthography increasingly influenced by Persian conventions to integrate a growing number of Persian loanwords and enhance expressiveness in literary and administrative texts. This period saw Urdu transitioning from a spoken vernacular to a more formalized written medium, as Persian's status waned and regional courts in northern India adopted Urdu for poetry and prose, leading to adjustments in letter forms and diacritic usage for clarity. [13][14] The advent of the printing press in the early 19th century revolutionized the dissemination of Urdu literature, beginning with initiatives at [Fort William College](/page/Fort William_College) in Calcutta around 1800, which produced the first printed Urdu books in the Nastaliq style despite technical challenges posed by its cursive design. Sir Syed Ahmad Khan emerged as a central figure in standardizing Nastaliq for Urdu, founding the Scientific Society in 1864 and launching Urdu typesetting operations that published magazines like Tehzeeb-ul-Akhlaq in the 1870s, thereby establishing consistent orthographic norms for educational and scientific works to bridge traditional Islamic scholarship with Western knowledge. [15][16] Following the partition of India in 1947, national policies diverged sharply regarding the Urdu alphabet. In Pakistan, Urdu was declared the national language in 1948, solidifying the Perso-Arabic script's role, with the government forming an advisory board on education in 1948 that recommended script reforms favoring the Naskh form over Nastaliq to simplify mechanical composition and standardize letter forms. [17] In contrast, India's constitution promoted Hindi in Devanagari as the official language while listing Urdu among scheduled languages, allowing it to retain its traditional script but facing pressures from unification efforts that encouraged Devanagari adaptations for Hindi-Urdu commonality. [18] These policies reinforced retroflex letters as key adaptations for Indic phonetics in both nations' versions of the script.Script Styles and Calligraphy
Nastaliq as Primary Style
Nastaliq script originated in 14th-century Iran, where calligrapher Mir Ali Tabrizi innovated by blending elements of the Naskh and Ta'liq styles to create a more fluid and aesthetically refined form of Perso-Arabic writing.[19] This development marked a significant evolution in Islamic calligraphy, prioritizing artistic expression while maintaining readability for Persian literature and poetry.[20] When Persian influences reached the Indian subcontinent through Mughal rule, Nastaliq was adapted for Urdu, incorporating additional letter forms to suit the language's phonology while preserving its core cursive elegance. The defining features of Nastaliq include its slanted, highly cursive structure, where letters connect in sweeping, diagonal baselines rather than straight horizontal ones, creating a sense of dynamic flow.[21] This style emphasizes elongated horizontal strokes, graceful curves, and intricate ligatures that prioritize visual beauty and rhythmic harmony over strict legibility, often resulting in a dense yet airy composition ideal for poetic expression.[22] In contrast to the more angular and baseline-aligned Naskh style commonly used for Arabic, Nastaliq's tilted orientation lends it a distinctive lyricism suited to the expressive needs of languages like Urdu and Persian.[23] In Urdu, Nastaliq serves as the predominant script for printed books, historical manuscripts, and public signage, reflecting its cultural prestige and traditional role in literary dissemination.[24] This usage is exemplified in the works of renowned poet Mirza Ghalib, whose ghazals and divans were meticulously transcribed in Nastaliq during the 19th century, enhancing the emotional depth of his verses through the script's flowing aesthetics.[25] One key advantage for Urdu lies in how Nastaliq's varied and curled letter shapes visually accommodate the language's retroflex consonants—such as those represented by forms like ṭe, ḍāl, and ṛe—allowing these indigenous sounds to be distinctly rendered within the cursive framework without disrupting the overall harmony.[26]Other Styles and Regional Variations
While Nastaliq remains the predominant style for Urdu, the Naskh script serves as a straighter and more legible alternative, characterized by its upright and linear forms that facilitate readability in printed materials.[27] Historically, Naskh was employed in early Urdu printing presses during the 19th century, before Nastaliq became standardized for literary works, due to its simpler structure for typesetting.[28] In modern contexts, Naskh is widely used in digital fonts and online publications for Urdu, as its angular patterns are easier to code and render on screens, appearing in outlets like BBC Urdu.[24][29] Regional variations in Urdu orthography reflect historical and cultural divergences, particularly between Pakistani and Indian usage. Pakistani Urdu incorporates a higher proportion of Persian loanwords, leading to spellings that preserve more classical Perso-Arabic forms, such as the frequent use of aspirated consonants in borrowed terms, compared to Indian Urdu's tendency toward simplified or Sanskrit-influenced adaptations.[30] Deccani Urdu, spoken in southern India, retains archaic orthographic forms from its 14th- to 17th-century development, including older vowel representations and vocabulary blends with regional languages like Marathi, distinguishing it from northern standardized Urdu.[31][32] Historical styles like Shikasta, a cursive shorthand derived from Nastaliq, feature broken letters and slanted connections for rapid writing, and were used in Urdu manuscripts during the Mughal and Qajar periods for personal correspondence and poetry.[33] However, Shikasta's complexity, which prioritizes aesthetic fluidity over legibility, limits its modern application to specialized calligraphic art rather than everyday or printed Urdu.[34]Core Alphabet Structure
Basic Letters and Positional Forms
The Urdu alphabet comprises 38 basic letters, which serve primarily as consonants in its abjad structure, arranged in a traditional order derived from the Perso-Arabic script. These letters form the core of the writing system and are supplemented by vowel carriers like alif, waw, and ye for certain phonetic roles. The exact count varies slightly across sources, with some including hamza (ء) as the 39th letter for its consonantal role; standard classifications use 38. The total includes 28 letters from the Arabic alphabet, four additional letters from Persian (pe پ, che چ, zhe ژ, gaf گ), and six unique to Urdu (ṭe ٹ, ḍāl ڈ, ṛe ڑ, nūn ghunna ں, hē-do-chashmī ھ, ye barī ے) to represent retroflex, nasal, aspirated, and vowel sounds, though classifications vary slightly across sources.[35][36] Urdu script is cursive and written from right to left, with letters changing shape based on their position in a word or connected sequence. Most of the 38 letters exhibit four distinct positional forms: isolated (standalone or after a non-joining letter), initial (at the start of a word or after a non-joining letter), medial (between two joining letters), and final (at the end of a word or before a non-joining letter). This contextual variation ensures fluid connectivity in handwriting and print. However, six letters—dāl (د), ḍāl (ڈ), re (ر), ṛe (ڑ), zē (ز), and wāw (و)—do not join to the letter following them on the left, limiting them to only two forms: initial/isolated (identical) and final. Alif (ا) is similar but has a distinct medial form ـا in certain contexts. Waw additionally does not join to the preceding letter in some contexts, further restricting its medial form. Joining occurs from right to left, with the baseline of connecting letters aligning to create seamless words; non-joining letters break the flow, starting a new connection segment. The following table presents all 38 basic letters in traditional abjad order, with their names (in Roman transliteration), and positional forms rendered in Unicode for visual clarity. Forms for non-joining letters show only applicable variants, with "—" indicating non-existent positions. Examples illustrate usage: e.g., ب in isolated (ب), initial (بَ), medial (کتاب), final (کتابْ). Hamzah (ء) is often considered a diacritic rather than a full letter but is noted for its consonantal role. Nūn ghunna (ں) appears only in final position as a nasal marker. Ye barī (ے) is used primarily in final position for specific vowels.| Name (Transliteration) | Isolated | Initial | Medial | Final |
|---|---|---|---|---|
| Alif (ʾalif) | ا | ا | ـا | ا |
| Bē (bē) | ب | بـ | ـبـ | ـب |
| Pē (pē) | پ | پـ | ـپـ | ـپ |
| Tē (tē) | ت | تـ | ـتـ | ـت |
| Ṭē (ṭē) | ٹ | ٹـ | ـٹـ | ـٹ |
| Sē (sē) | ث | ثـ | ـثـ | ـث |
| Jīm (jīm) | ج | جـ | ـجـ | ـج |
| Cē (cē) | چ | چـ | ـچـ | ـچ |
| Ḥāʾ (ḥāʾ) | ح | حـ | ـحـ | ـح |
| Khāʾ (khāʾ) | خ | خـ | ـخـ | ـخ |
| Dāl (dāl) | د | د | — | د |
| Ḍāl (ḍāl) | ڈ | ڈ | — | ڈ |
| Zāl (zāl) | ذ | ذـ | ـذـ | ـذ |
| Rē (rē) | ر | ر | — | ر |
| Ṝē (ṛē) | ڑ | ڑ | — | ڑ |
| Zē (zē) | ز | ز | — | ز |
| Žē (žē) | ژ | ژـ | ـژـ | ـژ |
| Sīn (sīn) | س | سـ | ـسـ | ـس |
| Shīn (shīn) | ش | شـ | ـشـ | ـش |
| Swād (swād) | ص | صـ | ـصـ | ـص |
| Zwād (zwād) | ض | ضـ | ـضـ | ـض |
| Taw (tāw) | ط | طـ | ـطـ | ـط |
| Zā (zāʾ) | ظ | ظـ | ـظـ | ـظ |
| ʿAin (ʿain) | ع | عـ | ـعـ | ـع |
| Ghain (ghain) | غ | غـ | ـغـ | ـغ |
| Fāʾ (fāʾ) | ف | فـ | ـفـ | ـف |
| Qāf (qāf) | ق | قـ | ـقـ | ـق |
| Kāf (kāf) | ک | کـ | ـکـ | ـک |
| Gāf (gāf) | گ | گـ | ـگـ | ـگ |
| Lām (lām) | ل | لـ | ـلـ | ـل |
| Mīm (mīm) | م | مـ | ـمـ | ـم |
| Nūn (nūn) | ن | نـ | ـنـ | ـن |
| Nūn ghunna (nūn ghunna) | ں | — | — | ں |
| Waw (wāw) | و | و | — | و |
| Hē (hē) | ہ | ہـ | ـہـ | ـہ |
| Ye (yē) | ی | یـ | ـیـ | ـی |
| Ye barī (ye barī) | ے | — | — | ے |
Letter Names and Phonetic Values
The Urdu alphabet follows the traditional abjad order derived from the Arabic script, recited as a sequence of letter names during learning and liturgical use. These names, such as alif, be, and te, facilitate memorization and are pronounced with specific phonetic values that correspond to consonants in the International Phonetic Alphabet (IPA). Each letter primarily represents a distinct phoneme, though some exhibit allophonic variations or context-dependent realizations influenced by surrounding sounds.[21][37] Urdu distinguishes between aspirated and unaspirated stops and affricates as phonemic contrasts, with unaspirated forms like /t̪/ (from te) contrasting with aspirated /t̪ʰ/, and similar pairs for /p/, /b/, /k/, /g/, /dʒ/, and /tʃ/. This opposition is a key feature of Indo-Aryan phonology adapted into the Perso-Arabic script. Certain letters, such as alif, may be silent in specific positions, functioning as a mater lectionis or glottal stop initiator, while others like waw and ye can vary between consonant sounds (/w/ or /v/ for waw; /j/ for ye) depending on phonetic context. Retroflex sounds, marked by dots (e.g., ṭe as /ʈ/), reflect indigenous Dravidian and Indo-Aryan influences.[37] The following table maps the 38 core letters of the Urdu alphabet to their traditional names and primary phonetic values in IPA, based on standard linguistic descriptions (focusing on consonantal roles; some letters also serve as vowels). Positional forms may subtly affect pronunciation in connected script, but the core phonemes remain consistent. Nūn ghunna represents nasalization (/ŋ/ or homorganic nasal). Ye barī (ے) is primarily vocalic (/eː/ or /ai/) and not listed here as a consonant. Hē-do-chashmī (ھ) is a modifier for /h/ in aspiration.[21]| Letter | Name | Phonetic Value (IPA) |
|---|---|---|
| ا | alif | /ʔ/ or silent |
| ب | bē | /b/ |
| پ | pē | /p/ |
| ت | tē | /t̪/ |
| ٹ | ṭē | /ʈ/ |
| ث | sē | /s/ |
| ج | jīm | /dʒ/ |
| چ | cē | /tʃ/ |
| ح | ḥāʾ | /h/ |
| خ | khāʾ | /x/ |
| د | dāl | /d̪/ |
| ڈ | ḍāl | /ɖ/ |
| ذ | zāl | /z/ |
| ر | rē | /r/ |
| ڑ | ṛē | /ɽ/ |
| ز | zē | /z/ |
| ژ | žē | /ʒ/ |
| س | sīn | /s/ |
| ش | shīn | /ʃ/ |
| ص | swād | /sˤ/ |
| ض | zwād | /zˤ/ |
| ط | tāw | /t̪ˤ/ |
| ظ | zāʾ | /zˤ/ |
| ع | ʿain | /ʕ/ |
| غ | ghain | /ɣ/ |
| ف | fāʾ | /f/ |
| ق | qāf | /q/ |
| ک | kāf | /k/ |
| گ | gāf | /g/ |
| ل | lām | /l/ |
| م | mīm | /m/ |
| ن | nūn | /n/ |
| ں | nūn ghunna | /ŋ/ or nasal |
| و | wāw | /w/ or /v/ |
| ہ | hē | /ɦ/ or /h/ |
| ھ | hē-do-chashmī | /h/ (aspiration) |
| ی | yē | /j/ |
Retroflex Letters and Unique Sounds
The Urdu alphabet incorporates several letters specifically adapted to represent retroflex consonants, which are characteristic of Indo-Aryan phonology and absent in the original Arabic and Persian scripts. These include ṭe (ٹ), ḍāl (ڈ), and ṛe (ڑ), corresponding to the phonemes /ʈ/, /ɖ/, and /ɽ/, respectively. The retroflex articulation involves curling the tip of the tongue back toward the hard palate, producing a distinct sound from the dental or alveolar equivalents found in Arabic-derived letters.[39][40][41] Historically, these letters emerged as modifications to the Perso-Arabic script during its adaptation in the Indian subcontinent over the past millennium, to accommodate the retroflex sounds inherited from earlier Indo-Aryan languages through sound changes in their development from Proto-Indo-Iranian. The forms were created by adding superscript dots to existing letters—two dots above tāʾ for ṭe, one dot above dāl for ḍāl, and two dots above re for ṛe—drawing on the need to transcribe phonemes present in Brahmi-derived scripts used for Sanskrit and Prakrit, which explicitly distinguished retroflexes. This adaptation reflects Urdu's hybrid nature, blending Perso-Arabic orthography with Indo-Aryan phonetic requirements, particularly for Dravidian-influenced or native Indic vocabulary.[39][42] In addition to these consonants, Urdu features a unique symbol for nasalization, nūn ghunnah (ں), a dotless form of nūn that represents the phoneme /ŋ/ or a nasal murmur, often applied to final vowels or consonants to indicate homorganic nasal release. This mark, derived from Persian influences but expanded for Indo-Aryan nasal patterns, is essential for words ending in nasalized sounds not native to Arabic.[43][39] The following table summarizes the basic retroflex letters and nūn ghunna, with their phonemes and representative examples. Aspirated retroflexes like ṭh (ٹھ) use combinations with hē-do-chashmī (ھ).| Letter | Name | Phoneme | Example Word (Urdu) | Transliteration | Meaning |
|---|---|---|---|---|---|
| ٹ | ṭe | /ʈ/ | ٹاپ | ṭāp | top |
| ڈ | ḍāl | /ɖ/ | ڈاکٹر | ḍākṭar | doctor |
| ڑ | ṛe | /ɽ/ | بڑھنا | baṛhnā | to grow |
| ں | nūn ghunna | /ŋ/ or nasal | بن | bañ | make/build |
Vowel System
Representation of Short and Long Vowels
The Urdu script employs an abjad system, in which vowels are not fully represented by dedicated letters but are instead conveyed through a combination of optional diacritics for short vowels, specific consonant letters for long vowels, and contextual inference rules. This approach prioritizes consonants while allowing experienced readers to infer vowels from linguistic context, though diacritics and vowel letters provide explicit guidance when needed. Short vowels are marked by harakat (diacritics), while long vowels use matres lectionis—letters that double as consonants and prolongation markers.[45][21] Short vowels in Urdu correspond to the sounds /ə/ (or /a/ in some positions), /ɪ/, and /ʊ/, and are optionally indicated by three diacritics: zabar (also called fatha, َ), a short diagonal stroke placed above the preceding consonant to denote /a/ or /ə/; zer (kasra, ِ), a breve-like mark below the consonant for /ɪ/; and pesh (damma, ُ), a small superscript curl above the consonant for /ʊ/. These marks, known collectively as ahruf or harakat, are rarely used in standard printed or handwritten Urdu texts, as readers rely on familiarity with words to supply the vowels; they appear mainly in pedagogical materials, poetry, or ambiguous contexts to ensure accurate pronunciation. In the absence of any diacritic, an implicit short /ə/ is conventionally assumed following most consonants, embodying the script's efficiency for native speakers. For instance, the consonant sequence کتب (ktb) is read as /kɪt̪aːb/ ("books") with the /ɪ/ and /aː/ inferred, but explicit marking yields کِتَبْ /kɪt̪əb/.[46][47][45] Long vowels, which extend the short counterparts in duration, are represented by dedicated letters that function as vowel carriers: alif (ا) for /aː/, wāw (و) for /uː/, and ye (ی) for /iː/. Alif typically denotes /aː/ at the beginning or end of a word, often following a zabar or standing alone; wāw indicates /uː/ after a pesh or in isolation; and ye marks /iː/ after a zer. These letters integrate into the word's skeletal structure, distinguishing long vowels from their short forms without additional diacritics in most cases. An example is باب /baːb/ ("door"), where alif prolongs the /a/ sound.[48][21][49] The following table summarizes the representation of short and long vowels, including their diacritic or letter forms, phonetic values in the International Phonetic Alphabet (IPA), and illustrative examples:| Vowel Pair | IPA (Short/Long) | Short Form (Diacritic) | Long Form (Letter) | Example (Urdu Script / Romanization / IPA) |
|---|---|---|---|---|
| a/ā | /ə/ /aː/ | َ (zabar) | ا (alif) | کَتَبْ /katab/ /kət̪əb/ ; باب /bāb/ /baːb/ |
| i/ī | /ɪ/ /iː/ | ِ (zer) | ی (ye) | کِتاب /kitāb/ /kɪtaːb/ ; کی /kī/ /kiː/ |
| u/ū | /ʊ/ /uː/ | ُ (pesh) | و (wāw) | کُتب /kutub/ /kʊt̪ʊb/ ; بو /bū/ /buː/ |
Special Vowel Letters and Implicit Vowels
In Urdu orthography, the letter alif (ا) serves primarily as a carrier for the long vowel /aː/, particularly in medial and final positions, where it explicitly denotes the prolonged sound without functioning as a consonant. For initial long /aː/, the form alif madd (آ) is used, as in آگ (āg, "fire") /aːg/.[21] Additionally, alif is placed silently at the initial position of words beginning with a vowel to adhere to the script's connection rules, as it does not connect to the following letter and allows the vowel sound to commence the word. For instance, in the word آب (āb, meaning "water"), the initial alif carries the /aː/ sound, while in اُردُو (Urdū), it is silent, enabling the following wāw to produce the initial /u/ vowel.[48] The letters wāw (و) and ye (ی) exhibit dual roles in vowel representation, functioning both as consonants (/w/ and /j/, respectively) and as carriers for specific long vowels. Wāw denotes /uː/ in positions like final or after a consonant with appropriate diacritics, and /oː/ when preceded by a fatha (short /a/ mark), as seen in words like گھوڑا (ghoṛā, "horse") where it renders the /oː/ sound.[21] Similarly, ye represents /iː/ directly, such as in کتابی (kitābī, "bookish"), and /eː/ when modified by a kasra (short /i/ mark) above the preceding letter, exemplified in پیش (pēsh, "before"). Additionally, the baṛī ye (ے) is a special form used in word-final position to represent /eː/, as in بے (be, "without") /beː/. These letters' versatility stems from the Perso-Arabic script's adaptation to Urdu's phonology, allowing economy in writing long back and front rounded/unrounded vowels.[21] Urdu writing omits short vowels in most cases, relying on implicit rules for their realization, particularly the inherent schwa /ə/ that follows each consonant in the script's abjad system but is frequently deleted in spoken Urdu.[50] This schwa, represented underlyingly as /a/ in orthography, is omitted in pronunciation for medial and final unstressed syllables, creating a mismatch between written and spoken forms; for example, the written کِتَاب (kitāb, "book") is pronounced /kɪˈt̪aːb/ with the schwa after /t̪/ deleted.[50] Word-ending rules typically eliminate the final schwa, resulting in consonant-final pronunciation unless a vowel carrier like alif or he follows, as in ہَوَا (havā, "air"), where the schwa after /v/ is absent in speech.[51] Short vowel diacritics (matras) may be added sparingly for clarity in pedagogical texts but are rare in standard writing.[46] Special cases include the letter ayn (ع), which in Urdu loanwords from Arabic often remains silent in initial and final positions, allowing adjacent vowels to blend, or carries an /ɛ/ sound for emphasis in certain dialects, as in عَین (ʿain, "eye") pronounced with a pharyngeal /ɛ/.[21] The letter he (ہ) similarly has a dual function: as a consonant /h/ in non-final positions, but in word-final use, it typically indicates a short /ə/ (or sometimes lengthened to /aː/), distinguishing it from alif; for example, in سُبَحْ (subaḥ, "morning"), it provides the final /ə/ sound, reflecting historical Perso-Arabic influences.[52]Diacritics and Modifications
Vowel Diacritics (Matras)
Vowel diacritics, known as matras or ahruf (vowel signs), are essential marks in the Urdu script used to indicate short vowels that are otherwise implicit in the consonantal skeleton. These diacritics are derived from the Arabic tashkil system and are placed as superscripts or subscripts on consonants to specify pronunciation, particularly for learners or in ambiguous contexts.[21] The three primary vowel diacritics correspond to the short vowels /ə/ (zabar or fatha, َ), /ɪ/ (zer or kasra, ِ), and /ʊ/ (pesh or damma, ُ). Zabar appears as a short diagonal stroke above the consonant, zer as a similar stroke below, and pesh as a small superscript curl resembling a "u" above the letter.[49][21] In practice, these diacritics are optional in fluent Urdu texts, where experienced readers infer short vowels from context, word boundaries, and phonetic knowledge, allowing for a more streamlined cursive script. They become mandatory in educational primers, religious texts like the Quran, and materials for non-native speakers to ensure accurate reading. Stacking occurs when multiple diacritics are needed, such as combining a short vowel mark with sukun (ْ) to indicate a consonant cluster without an intervening vowel, though this is rare in standard Urdu orthography.[21] Historically, vowel diacritics saw fuller application in early Perso-Arabic manuscripts from the 13th century onward, when Urdu script emerged, to aid precise recitation amid the script's evolution from Arabic and Persian influences; this mirrors the 8th-century introduction of tashkil in Arabic for Quranic clarity. In modern print, their use has been significantly reduced for efficiency and aesthetic flow in Nastaliq style, appearing primarily in pedagogical resources rather than everyday literature.[21][53] For example, the word "kitab" (book) is written without diacritics as کتاب, but with them as کِتَاب, where zer (ِ) on ک indicates /ɪ/, zabar (َ) on ت denotes /ə/, and the alif (ا) represents the long /ɑː/, clarifying the pronunciation /kɪt̪ɑb/. Long vowels, by contrast, rely on dedicated letters like alif (ا) rather than these diacritics.[49][21]Consonant Modifications and Hamza
In the Urdu script, the hamza (ء) serves primarily as an orthographic device to separate adjacent vowels, rather than representing a consonantal glottal stop as it does in Arabic.[39] It is typically positioned above or below a carrier letter, known as its "seat" or "chair," which varies based on the surrounding vowels and the word's position.[54] In initial positions, the hamza is attached to an alif (ا) with the seat determined by the following short vowel: for a kasra (ِ), it seats on a yeh (ئَ); for a damma (ُ), on a waw (ؤَ); and for a fatha (َ), on the alif itself (أَ).[55] For example, the word ئِدْ (id) illustrates initial hamza on yeh for the /i/ sound separation. In medial positions, the seat adjusts according to the preceding vowel, such as on waw after a damma or on yeh after a kasra, as seen in compounds like اَءْلَهْ (allāh), where it prevents vowel coalescence.[56] Other consonant modifications include the jazm (ْ), a diacritic that suppresses the implicit short vowel after a consonant to form clusters, effectively "cutting short" the sound.[45] Shaped like an inverted v and placed above the consonant, the jazm is uncommon in everyday Urdu writing but appears in educational texts to clarify pronunciation, similar to the halant (्) in Devanagari. For instance, in کْتَب (ktab, for kitāb without vowel), it indicates no /i/ between k and t.[48] Additionally, the superscript alif (ٰ), or dagger alif (also known as khari zabar), modifies consonants by indicating a long /aː/ sound, particularly in Arabic loanwords, such as above yeh (ی) in اعلیٰ (aʿlā́, high). This form, a small vertical stroke, alters the pronunciation from a simple yeh to /aː/, distinguishing it from non-modified forms.[47] Nasality in Urdu consonants is marked by the nun ghunnah (ں), a modified form of nun with an overline, used to nasalize preceding vowels, especially at word ends, producing sounds like /m̃/, /ñ/, or /ŋ/.[57] This diacritic follows the vowel letter without altering the consonant's base form, creating nasalized vowels akin to those in French (e.g., bon). For example, بَحْتَں (bahtẽ, discussions) uses nun ghunnah to nasalize the final /e/, indicating /ẽ/ rather than a plain /e/.[43] It applies to long vowels like alif, waw, or yeh, enhancing phonetic nuance in Indo-Aryan contexts.[58] In the Nastaliq script predominant for Urdu, the positioning of hamza and other diacritics like nun ghunnah can vary by calligrapher, as the cursive, diagonal flow allows artistic flexibility that may obscure precise placement.[21] This variation, while aesthetically enriching, poses challenges in digital typesetting, where hamza often renders as an s-shaped mark rather than a strict diacritic, potentially affecting readability in complex words.[59]Special Orthographic Features
Digraphs and Ligatures
In the Urdu script, digraphs are essential for representing aspirated consonants, which combine a base consonant with ھ (do-chashmī hāʾ, or "two-eyed hāʾ") to produce breathy or aspirated sounds—a phonological contrast inherited from Indo-Aryan languages and absent in classical Arabic or Persian. These digraphs distinguish unaspirated stops and affricates from their aspirated counterparts, affecting meaning in words; for example, کھڑا (khaṛā, "standing," [kʰəɽa]) contrasts with کڑا (kaṛā, "stiff," [kəɽa]). There are typically eleven such digraphs, covering bilabial, dental, retroflex, palatal, and velar places of articulation, with retroflex forms like ٹھ (ṭh, [ʈʰ]) and ڈھ (ḍh, [ɖʱ]) reflecting Urdu's South Asian substrate.[60][61][62] Ligatures in Urdu, rendered in the Nastaliq style, involve the cursive joining of letters to form interconnected shapes that enhance aesthetic flow and legibility, often blending two or more characters into a single visual unit. Unlike fixed digraphs for phonemes, ligatures are contextual and variable, with traditional calligraphy featuring thousands of forms; for instance, یل (ye-lām) ligates to represent /il/ in words like ملی (milī, "met"), where the tail of ye curves into lām without abrupt breaks. This joining is automatic in connected positions (initial, medial, final), but Nastaliq's diagonal baselines and overlapping strokes create complexity, especially for retroflex ligatures involving letters like ڑ (ṛe), which curls distinctly. Digital fonts approximate these for practicality, reducing the full calligraphic variability.[21][63] The table below enumerates key aspirated digraphs, including retroflex examples, with their script forms, romanizations, IPA values, and illustrative words (transliterations approximate standard pronunciation).| Digraph | Romanization | IPA | Example Word (Urdu) | English Meaning |
|---|---|---|---|---|
| بھ | bh | [bʱ] | بھائی (bhāʾī) | brother |
| پھ | ph | [pʰ] | پھول (phūl) | flower |
| تھ | th | [t̪ʰ] | تھم (thum) | halt |
| ٹھ | ṭh | [ʈʰ] | ٹھنڈ (ṭhaṇḍ) | coolness |
| چھ | chh | [tʃʰ] | چھوڑ (chhoṛ) | leave |
| کھ | kh | [kʰ] | کھڑا (khaṛā) | standing |
| دھ | dh | [d̪ʱ] | دھوپ (dhūp) | sunlight |
| ڈھ | ḍh | [ɖʱ] | ڈھکن (ḍhakkan) | lid |
| جھ | jh | [dʒʱ] | جھوٹ (jhūṭ) | falsehood |
| گھ | gh | [ɡʱ] | گھوڑا (ghoṛā) | horse |
| ڑھ | ṛh | [ɽʱ] | مڑھو (maṛhū) | twist (rare) |
Izafat and Tāʾ Marbūṭah
The izafat (Arabic: إِضَافَة, meaning "addition") is a grammatical and orthographic construct in Urdu derived from Persian, where it is employed more frequently, serving to link nouns in possessive, descriptive, or attributive relationships, akin to the English "of" or genitive case.[64] In Urdu, it appears in three primary orthographic forms depending on the ending of the initial noun (muḍāf): the kasr-e-izafat (ِ, a short vowel mark added to consonants), the yāʾ-e-izafat (ی, for nouns ending in long ā), and the hāʾ-e-izafat (ہ, for nouns ending in e).[65] For instance, in the phrase کتابِ خان (kitāb-e khān, "book of Khan"), the kasr-e-izafat (ِ) is used after the consonant-final kitāb to indicate possession.[64] Usage of the izafat is obligatory in formal Urdu writing and poetry to maintain grammatical precision and rhythmic flow, though it may be omitted or replaced by postpositions like ke, kā, or kī in casual speech.[65] This construct is restricted to Persianate or Arabo-Persian vocabulary, avoiding native Indo-Aryan words, and it is pronounced as a short /e/ sound between the linked terms.[64] In prose, such as legal or administrative texts, it ensures clarity in compound phrases like ahl-e-bait (people of the house). In poetry, it enhances euphony; for example, in Mirza Ghalib's ghazal, the line "dil-e-nādān tujhe huā kyā hai" employs yāʾ-e-izafat in dil-e-nādān ("O naive heart") to convey emotional possession and metrical balance.[66] The tāʾ marbūṭah (تاء مربوطة, "tied tāʾ") is an orthographic element borrowed from Arabic, marking the feminine gender in loanwords, typically rendered in Urdu as a final hāʾ (ہ) or occasionally the Arabic form ة in formal or religious contexts.[67] It originates from Arabic feminine nouns and adjectives integrated into Urdu, where it denotes finality and gender without altering the base form's pronunciation in isolation.[68] In Urdu orthography, it is pronounced as /a/ or /e/ in pause (e.g., مدرسہ, madrasa, "school" or "madrasa"), but shifts to /t/ in construct states or when followed by suffixes, as in madrasat al-ʿulūm ("school of sciences").[69] This marker is mandatory in formal writing for Arabic-derived feminine nouns to preserve etymological integrity, though colloquial pronunciation often simplifies it to a vowel ending, and it may interact briefly with hamza in certain genitive constructions.[67] Examples abound in prose like religious texts, such as رسالہ (risāla, "treatise" or "letter"), and in poetry, where Allama Iqbal uses forms like it in "masjid-e-qurtaba" (though izafat-linked, the feminine ending underscores thematic femininity in cultural motifs).[70] Its retention highlights Urdu's hybrid script, blending Arabic morphology with indigenous phonology for gender indication in loan vocabulary.[68]Differences from Persian and Arabic Alphabets
The Urdu alphabet, while rooted in the Perso-Arabic script, incorporates significant adaptations to accommodate the phonetic inventory of Indo-Aryan languages, resulting in a more expanded and phonetically explicit system. The standard Arabic alphabet consists of 28 letters, the Persian of 32 (adding four letters—pe پ, che چ, zhe ژ, and gāf گ—for sounds absent in Arabic), and the Urdu of 39 letters, which build upon the Persian base with further innovations primarily for retroflex, aspirated, and nasal sounds not native to Arabic or Persian.[71][72] Among the key additions in Urdu are the retroflex consonants ṭe (ٹ), ṭhe (ٹھ), ḍāl (ڈ), ḍhe (ڈھ), and ṛe (ڑ), which represent tongue-tip sounds derived from Prakrit and other Indic substrates, alongside nūn ghunnah (ں) for final nasalization and do-chashmi he (ھ) to indicate aspiration on consonants—features largely absent in the source scripts.[21] These extensions allow Urdu to distinguish phonemes like the retroflex /ʈ/, /ɖ/, and /ɽ/ that Persian and Arabic lack, enabling more precise representation of native vocabulary. In contrast, Urdu omits or underutilizes certain Arabic gutturals, such as the emphatic ṣād (ص) and ḍād (ض), which are either merged with non-emphatic counterparts or rarely employed due to phonological simplification in spoken Urdu.[73] Persian letters like pe and che are retained and integrated but often modified in form or frequency to fit Urdu's aspirated series (e.g., phe پھ, che چھ).[6] Orthographic variances further highlight Urdu's divergence, particularly in its approach to vowels, where the script's abjad nature is tempered by heavier use of diacritics (matras) to denote short and long vowels explicitly—driven by the vowel prominence in Indic phonology—compared to the minimalism of Persian and Arabic, which rely more on reader inference and consonantal skeletons.[47] For instance, Urdu frequently marks vowels like zabar (َ) for /a/ or pesh (ِ) for /i/ in ambiguous contexts to avoid misreading, a practice less common in Persian's more ambiguous orthography or Arabic's fully vocalized classical forms.[74]| Aspect | Arabic (28 letters) | Persian (32 letters) | Urdu (39 letters) |
|---|---|---|---|
| Core Letters | All 28 basic consonants (e.g., alif ا, bā ب, etc.) | Arabic 28 + pe (پ), che (چ), zhe (ژ), gāf (گ) | Arabic/Persian 32 + retroflex ṭe (ٹ), ḍāl (ڈ), ṛe (ڑ); nūn ghunnah (ں); aspiration markers like do-chashmi he (ھ) |
| Sound Adaptations | Gutturals and emphatics prominent (e.g., qāf ق, ḍād ض) | Adds /p/, /tʃ/, /ʒ/, /ɡ/; reduces some emphatics | Adds retroflex /ʈ/, /ɖ/, /ɽ/, /ɳ/; aspiration (e.g., /pʰ/, /tʰ/); less distinction for Arabic emphatics |
| Vowel Marking | Optional diacritics; context-dependent | Sparse matras; relies on long vowels (e.g., alif, wāw) | Frequent matras for short vowels; explicit for Indic vowel harmony |
| Example Variance | Writes "kitab" (book) as كتاب (vowels inferred) | Similar: کتاب (minimal vowels) | Writes "kitāb" as کتاب but often كِتَابْ with matras for clarity in teaching/native words |
Modern Digital and Romanization Aspects
Unicode Encoding and Input Challenges
The Urdu alphabet is encoded within the Unicode Standard using the Arabic block, spanning code points U+0600 to U+06FF, which accommodates the core Perso-Arabic script shared with languages like Arabic and Persian.[75] This block includes 238 Arabic characters, along with inherited and common symbols, enabling representation of Urdu's 39 basic letters and additional diacritics.[75] Urdu-specific characters, such as the letter pe (پ, U+067E), tte (ٹ, U+0679), and rreh (ڑ, U+0691 for ṛe), are integrated into this range to distinguish Urdu phonemes from those in Arabic or Persian.[75] Encoding Urdu script presents several technical challenges due to its right-to-left writing direction, which requires bidirectional text algorithms to properly align with left-to-right elements in mixed-language documents.[76] Contextual shaping is another key issue, as individual letters must change form (initial, medial, final, or isolated) based on their position in a word, demanding robust font rendering engines for accurate display.[76] Ligature support adds complexity, particularly in cursive styles like Nastaliq, where certain letter combinations form joined glyphs that vary by font and require advanced OpenType features for proper substitution.[76] Inputting Urdu text digitally relies on specialized methods to overcome the limitations of standard QWERTY keyboards. On-screen keyboards, such as those provided by Google Input Tools, allow users to select Urdu characters visually or via transliteration from Roman input.[77] Phonetic typing tools further simplify entry by mapping English-like keystrokes to Urdu script, enabling users to type words phonetically (e.g., "kitab" for کتاب) with automatic conversion.[78] Historically, pre-Unicode systems like ASCII (limited to 7-bit Latin characters) offered no support for Urdu's script, forcing reliance on proprietary code pages or transliteration that hindered interoperability.[79] Standardization efforts culminated in the approval of an Urdu code page by the Government of Pakistan in 2000, aligning with Unicode's Arabic block.[79] Post-2000 advancements in OpenType font technology have significantly improved rendering of complex Urdu features, including shaping and ligatures, facilitating better digital adoption across platforms. As of 2025, Unicode 17.0 (released September 2024) provides enhanced support for Nastaliq rendering, improving ligature formation and contextual shaping on modern devices.[80]Romanization Standards and Systems
Romanization of the Urdu script into the Latin alphabet involves systematic transliteration to represent the phonemes of Urdu, which derives from the Perso-Arabic script. Formal standards emerged during the British colonial period and have been refined by international bodies for consistency in scholarly, governmental, and library contexts. The Hunterian system, originally developed in the 19th century for Indian languages, was adapted for Urdu geographical names and adopted by the United States Board on Geographic Names (BGN) and Permanent Committee on Geographical Names (PCGN) in 2007, emphasizing diacritics to distinguish sounds like retroflex consonants and aspirates.[81] Similarly, the United Nations Group of Experts on Geographical Names (UNGEGN) approved a romanization system for Urdu in 1972, based on the Hunterian approach, to handle the script's right-to-left direction and optional vowel diacritics by inferring vowels from context or dictionaries.[82] Another key formal standard is ISO 15919, published in 2001 by the International Organization for Standardization, which provides a unified scheme for transliterating Indic and related scripts, including adaptations for Urdu's Perso-Arabic form; it uses diacritics such as underdots for retroflex sounds (e.g., ṭ for ٹ) and overdots or hooks for aspirates (e.g., kh for خ). The ALA-LC romanization, maintained by the Library of Congress and American Library Association since 1997 (revised 2013), is widely used in bibliographic and academic settings for Urdu; it prioritizes readability while preserving phonetic accuracy, romanizing hamza (ء) as a glottal stop and treating final h (ہ) as silent unless vocalized.[60] These systems differ slightly in diacritic usage—for instance, ISO 15919 employs macrons for long vowels (ā), while Hunterian often simplifies to 'a'—but all aim to capture Urdu's 39 consonants and 10 vowels without ambiguity. Informal romanization, known as Roman Urdu, proliferates in digital communication, social media, and diaspora contexts, bypassing formal diacritics for phonetic approximations using standard English keyboard characters. Common examples include "khush" for خوش (happy), "shukriya" for شکریہ (thank you), and "zindagi" for زندگی (life), reflecting everyday spelling variations without standardization.[83] This approach, prevalent since the British Raj but exploding with SMS and online platforms, often merges Hindi-Urdu lexical overlaps, leading to hybrid forms like "achha" for اچھا (good).[84] Challenges in romanization arise from Urdu's phonological features not native to English, such as retroflex consonants (e.g., distinguishing ṭ from t in ٹ vs. ت), aspirated stops (e.g., kh vs. k in خ vs. ك), and vowel length (e.g., ā vs. a in آ vs. ا), which formal systems address with diacritics but informal ones approximate inconsistently, risking loss of nuance.[85] For instance, the retroflex flap ڑ is rendered as ṛ in ISO 15919 and ALA-LC but simplified to r in casual Roman Urdu, potentially conflating it with the alveolar r (ر).| Urdu Letter | Formal Romanization (ALA-LC/ISO 15919) | Informal Roman Urdu Example | Phonetic Note |
|---|---|---|---|
| خ (khe) | kh | kh | Aspirated velar fricative, as in "loch" |
| ڑ (ṛe) | ṛ | r or rh | Retroflex flap, no direct English equivalent |
| ٹ (ṭe) | ṭ | t' or t | Retroflex stop, tongue curled back |
| ا (alif) | ā (long) or a (short) | aa or a | Long vowel in initial position |
| ہ (he) | h (medial/final silent) | h | Glottal fricative, often dropped informally |
Glossary of Terminology
Key Terms from Letter Names
The Urdu script, as an abjad system, primarily represents consonants while implying short vowels through context, with long vowels indicated by specific letters like alif, waw, and ye.[86] The term abjad derives from the first four letters of the Arabic alphabet (alif, ba, jim, dal) and denotes this consonant-focused writing tradition shared by Urdu, Arabic, and Persian scripts.[86] In Urdu orthography, matra refers to dependent vowel signs attached to consonants, akin to the harakat in Arabic, though Urdu often omits them in everyday writing for brevity.[47] The shadda (also called tashdid), a small "w"-shaped diacritic, marks gemination or doubling of a consonant, emphasizing its pronunciation by indicating a prolonged sound, as in words requiring intensified articulation.[45] Letter names in Urdu carry cultural and symbolic weight beyond phonetics; for instance, alif, the first letter denoting a glottal stop or long vowel /aː/, symbolizes unity and primacy, representing the number one in abjad numerology and evoking themes of oneness (tawhid) in Islamic and Sufi traditions.[87] This symbolism appears in Urdu poetry, where alif often metaphorically signifies the divine or the beginning of creation. Phonetic diacritics in Urdu are named zabar (fatha, a short /a/ sound, marked by a superscript diagonal line), zer (kasra, a short /ɪ/ sound, marked by a subscript diagonal line), and pesh (damma, a short /ʊ/ sound, marked by a superscript curl), collectively known as harakat to guide pronunciation in instructional or ambiguous texts.[46] These marks, though Persian-derived in nomenclature, clarify vowel inflections essential for learners.[88] In Urdu literary culture, letter names and the abjad system extend to numerology, where each letter holds a numerical value (e.g., alif=1, ba=2) used in chronograms—poetic phrases whose abjad sum encodes dates or events, a practice blending script, mathematics, and artistry in ghazals and historical inscriptions.[89] This tradition underscores the script's role in encoding layered meanings beyond literal text.Phonetic and Script-Specific Vocabulary
The Urdu script incorporates a range of diacritical marks, or harakat, to denote short vowels and other phonetic features, with terminology often borrowed from Persian and Arabic linguistic traditions. These marks are optional in everyday writing but essential for precise pronunciation in pedagogical contexts. The zabar (also called fatha), represented as a short horizontal line above a consonant, indicates the short vowel sound /a/, as in the word jab (when) where it modifies ج (jīm) to /dʒa/.[45] The zer (or kasra), a short horizontal line below the consonant, signifies the short vowel /ɪ/, as in kitab (book) applied to initial ک to /kɪ/.[45] Similarly, the pesh (or damma), a small curl above the consonant, denotes the short vowel /ʊ/, as in kuchh (some).[45] These three diacritics collectively guide the "riding" of vowels on preceding consonants, a conceptual framework in Urdu orthography.[48] For consonant modifications, the tashdid (also known as shadda), a small "w"-shaped mark above a letter, indicates gemination or doubling of the consonant sound, lengthening its duration and affecting syllable weight, as in maddad (help) where the doubled d is pronounced emphatically.[45] The jazm (or sukun), depicted as a small circle above the letter, signifies the absence of any vowel, creating a consonant closure, as in the final b of kitab rendered without trailing sound.[49] Additionally, the hamza (ء), a glottal stop diacritic, separates vowels or indicates a brief pause, often seated on a carrier like alif or waw, preventing coalescence in words like sūʾāl (question).[47] Phonetically, Urdu distinguishes between aspirated and unaspirated consonants, with aspiration adding a breathy release (hawa) following the stop. Unaspirated stops, termed be-hawa in descriptive linguistics, include sounds like /p/, /t/, and /k/, produced without audible breath, as in patthar (stone) for the initial /p/.[90] Aspirated counterparts, hawa-dar, feature a puff of air, such as /pʰ/ in phool (flower), /tʰ/ in thanda (cold), and /kʰ/ in khaana (food); Urdu has 10 aspirated stops and affricates out of 20 total.[90] Retroflex consonants, articulated with the tongue curled back toward the palate, include the stops /ʈ/ (ṭ) and /ɖ/ (ḍ), as in ṭik (right) and ḍānkā (drumbeat), contrasting with dental equivalents.[41] A distinctive retroflex flap, /ɽ/ (ṛ or ṛe), appears intervocalically as a quick tap, heard in paṛnā (to read), and can be aspirated as /ɽʱ/ in forms like būṛhā (old man).[91] These features, totaling approximately 41 consonants among Urdu's roughly 52 phonemes, underscore the script's adaptation for Indo-Aryan phonology.[92][90]| Term | Description | Example Sound/Usage | Citation |
|---|---|---|---|
| Zabar (Fatha) | Diacritic for short /a/ | /dʒa/ in jab | [45] |
| Zer (Kasra) | Diacritic for short /ɪ/ | /kɪ/ in kitab | [45] |
| Pesh (Damma) | Diacritic for short /ʊ/ | /kʊ/ in kuchh | [45] |
| Tashdid (Shadda) | Gemination mark | Doubled /d/ in maddad | [45] |
| Jazm (Sukun) | Vowel absence indicator | Silent final /b/ in kitab | [49] |
| Hamza | Glottal stop separator | /ʔ/ in sūʾāl | [47] |
| Hawa-dar (Aspirated) | Breathy release consonants | /pʰ/ in phool | [90] |
| Be-hawa (Unaspirated) | Non-breathy stops | /p/ in patthar | [90] |
| Retroflex (ṭ, ḍ, ṛ) | Tongue-curled articulation | /ɽ/ flap in paṛnā | [41] |